-
Concurrent Programming시스템 프로그래밍 2022. 4. 16. 18:42728x90
Concurrent Programming is Hard !
concurrent 프로그래밍은 어렵습니다.
보통 우리는 sequential한 사고방식을 가지고 있어 time(시간)이라는 개념이 다르게 느껴집니다.
또한 동시에 프로그램이 진행되기 때문에 어떤 프로그램이 어떤 event가 발생했는지 예상할 수가 없어
비동기 방식으로 처리 해야합니다. 디버깅도 쉽지않습니다.
이러한 concurrent의 문제점이 존재합니다.
Race (경쟁)
OS가 process를 여러개 띄어놓고 time sharing을 하기 때문에 스케줄링(os 역할) 결과값 다를 수 있음
내가 결정할 수 있는 사안이 아닙니다. 따라서 스케줄링의 순서에 따라 내가 생각한 결과와
다르게 나올 수 있습니다.
Deadlock (교착상태)
우리가 교통상황에서 교착상태가 일어나듯이 부적절한 recource할당이 두개 이상의 process들이
더 이상 전진을 못하는 경우 입니다.

Livelock / Starvation / Fairness
Livelock은 critical section에 들어가기 위한 노력을 의미하고
Starvaion은 critical section에 들어가고 싶은데 다른 process가 이미 들어가 있어 굶어 죽는 경우입니다.
Fairness는 스케줄링이 되는 순서에 따라서 내가 필요한 만큼의 clock cycle을 받지 못하는 경우입니다.

Iterative Servers

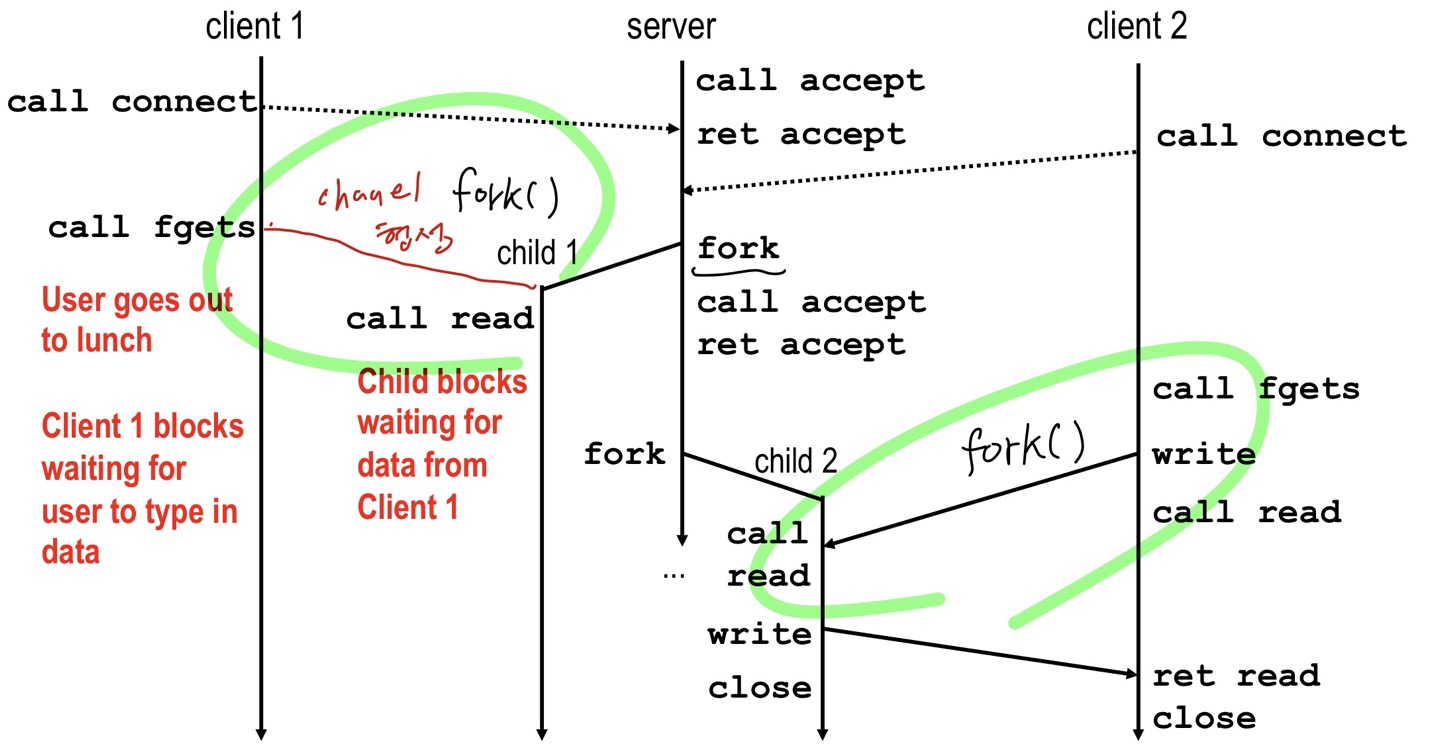
현재 server를 띄우고 listen중일 때, 먼저 Client1이 connect 요청을 보내고 accept합니다.
이때 Client2가 connect 요청을 보냅니다. 현재 Client1이 accept 되있기 때문에 Client2의 요청은
tcp manager에 queueing 됩니다. 따라서 아직 Client2의 요청은 accept되지 않습니다.
server는 client1을 read 상태여서 client1이 write하는 것을 받아들이고 close를 보내면 client1은 종료됩니다.
client2는 client1이 close된 후 accept됩니다. 전에 보냈던 메시지를 read하고 write 하고 종료합니다.
결국 client2는 상대적으로 client1 보다 오랜 시간이 지나서야 수행됩니다.
Where Does Second Client Block
client2가 block되는 과정을 보여줍니다.

client는 connect요청을 보내고 server에서 accept되면 바로 return됩니다.
하지만 client2는 accept되지 않아 return을 못하지만 sever쪽의 OS kernel안에
TCP manager가 queueing하고 있기 때문에 return 할 수 있습니다.
client는 write 함수를 호출해 메시지를 보낼 수 있습니다. server는 TCP manager에서 buffer된
메시지를 queueing 합니다.
하지만 server에서는 아직 accept되지 않았기 때문에 client1는 read 함수에서 blocking 됩니다.
Fundamental Flaw of Iterative Servers

결국 client1은 정상적으로 accept되어 잘 수행 하지만 client2는 시간이 많이 지체 됩니다.
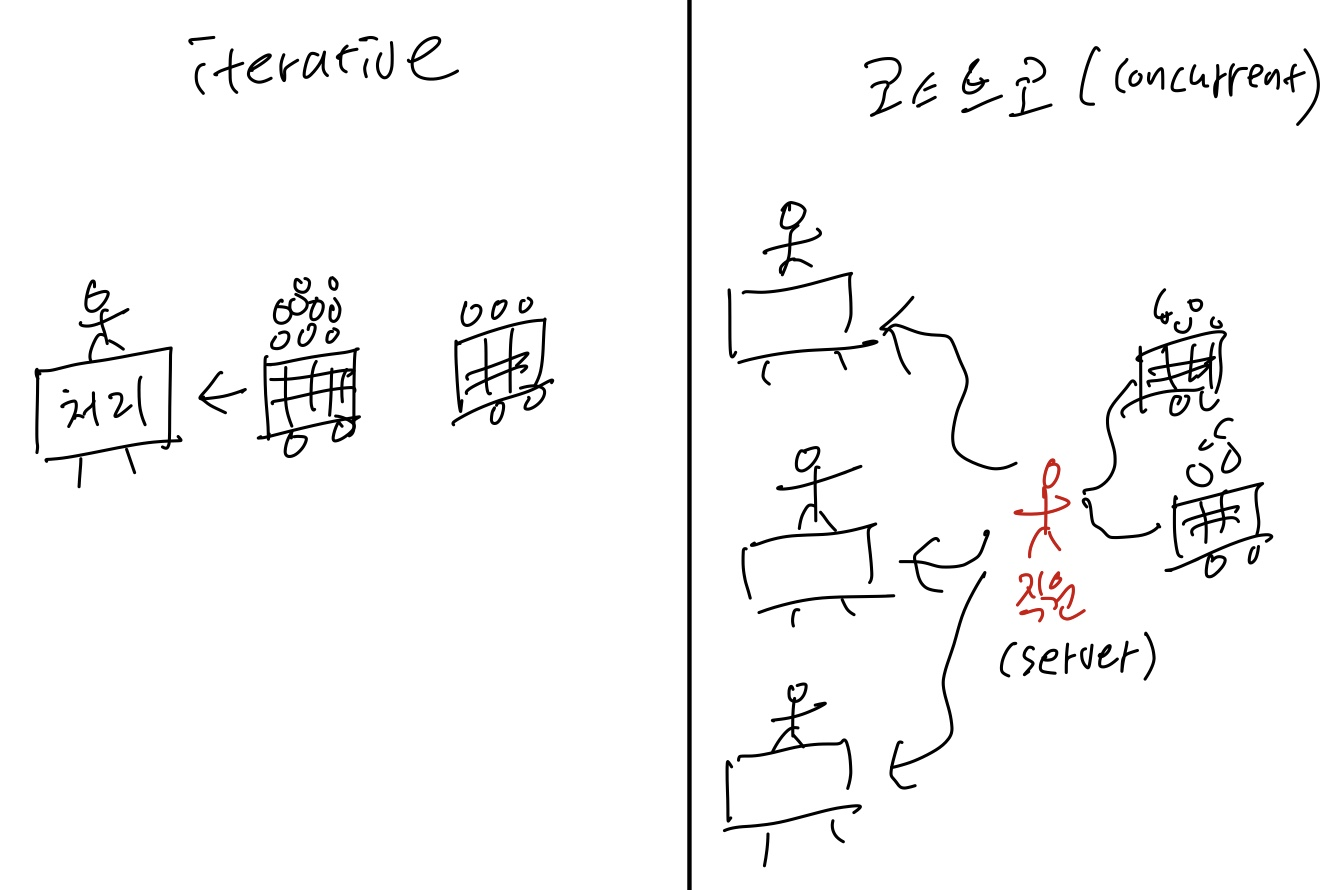
이러한 문제점을 해결할 수 있는것이 Concurrent server 입니다.
Concurrent server는 다수의 client를 동시에 처리하기 위해 다수의 concurrent flow(코스트코 계산대)를 사용합니다.
Approaches for Writing Concurrent Servers
concurrent flow를 여러개 만드는 방법에는 3가지 방법이 존재합니다.
1) Process-based
process 기반은 server가 client로 부터 connection을 맺을 때 마다 accept하고 fork()를 통해 child 를 만들어
오직 client와 child process 와 통신을 하게 만들어 줍니다.
그래서 kernel이 여러개의 logical flow를 맺어 kernel이 time sharing을 해 concurrent하게 서비스를 할 수 있게 합니다.
2) Event-based
server는 1개만 있고 fork()를 하지 않고 각 client를 accept해 fd를 따로따로 가지고 있습니다.
fd마다 어떤 메시지가 오면 조건문에 따라 각 fd에 해당하는 내용을 처리해주는 방식입니다.
logical flow가 있지만 manual하게 처리해야 합니다. 이런것을 I/O multiplexing 이라고 합니다.
모든 flow들은 동일한 address space를 가집니다.
3) Thread-based
kernel이 자동적으로 interleave합니다. 각 flow는 동일한 address space를 가집니다.
process-based 와 event-based의 hybrid 입니다.
Approach #1 : Process-based Servers
client가 server에게 connect 요청을 보내면
server는 fork를 통해 child process를 만들고 cliet를 child process와 통신합니다.
Process-Based Concurrent Echo Server

fork를 통해 만들어진 child process는 listenfd를 먼저 close하고 echo를 실행합니다.
모든 echo가 끝나면 connfd를 close하고 exit 합니다.
그러면 server는 connfd를 close합니다.

server는 fork를 통해 server child를 띄우면
server chlid는 listenfd는 필요없으므로 close하고 echo가 끝나면 client와 연결되었던 connfd를 close하고 exit합니다.
그러면 server는 connfd를 close합니다.
Process-based Server Excution Model

client server 끼리는 독립된 공간을 가지고 있어 서로 통신할 수 없습니다.
Issues with Process-based Servers
server는 child process가 exit하면 자신의 connfd를 반드시 종료해 주어야 합니다.
그러지 않으면 메모리 누수가 일어나게 됩니다.
Pros and Cons of Process-based Servers
장점
다수의 connection들을 동시에 처리할 수 있습니다.
단점
connection 요청이 올때 마다 fork를 띄우기 떄문에 resource를 굉장히 많이 소모합니다.
그리고 client끼리 data sharing이 되지않습니다.
Concurrent Programming with I/O Multiplexing

multiplexing이란 하나의 전송로를 통해 여러 종류의 데이터를 전송하는 방식입니다.
각 socket의 fild descriptor를 리스트화하여 저장해두고, 각 socket의 I/O stream을 감시하다가
client로 부터 데이터가 수신되어 입력 stream에 저장되면 이에 대한 것을 해당 socket에게
client 요청이 왔다고 알려주고 server와 통신을 하게 됩니다. 여기서 socket를 감시하는 역할이
수행하는 것이 select() 함수입니다.
Approach #2 : Event-based Servers
process가 딱 1개만 있습니다.
connfd의 배열을 가지고 있습니다.
connfd 또는 listenfd를 포함한 배열을 가지고 있으면서 만약 file descriptor 각각의 뭔가 pending input이 있다는
것을 확인해 pending input이 있을 때 그때에 해당하는 input에 대해 맞는 action을 수행합니다.
1) select, epoll을 사용해 fild descriptor를 살펴보고 각 event에 맞추어서 해당하는 action을 수행합니다.
2) listenfd에 pending input이 있다면 accept 함수가 connection 맺으면 됩니다. 그리고 새로운 connfd를 받아
배열에 추가해줍니다.
3) connfd에 해당하는 pending input이 왔으면 수행해 주면 됩니다.
1, 2, 3을 반복적으로 수행하면 됩니다.
I/O Multiplexed Event Processing

I/O Multiplexing 기반의 event 처리입니다. Active Descriptor라고 해서 두 가지가 존재합니다.
listenfd와 connfd가 있습니다. connfd의 번호가 할당된 것은 connfd 값이 들어가 있는 것입니다.
-1이 아닌것은 connection이 맺어진 것입니다.
select, epoll 함수를 통해 file descriptor에 pending input이 있는지 확인합니다.
만약에 pending inputr이 있다면 처리해주면 됩니다.
I/O Multilplexing
select 또는 epoll 함수를 사용해 kernel에 process를 일시 중단하도록 요청하여 하나 이상의 I/O event가
발생한 후에만 control 권하는 응용프로그램에 반환합니다.
select 함수


select 함수를 호출해 결과를 얻기까지의 과정을
그린것입니다.
select 호출에 앞서 준비가 필요하고 또 호출 이후에도 결과의
확인을 위한 별도의 과정이 존재함을 보이고 있습니다.
select 함수를 사용하면 여러 개의 file descriptor를 동시에 관찰할 수 있습니다.
file descriptor의 관찰은 socket의 관찰과 동일합니다.
select 함수의 2번째 인자를 보면 fd_set 자료형입니다.

0과 1로 표현되는 bit vector 입니다.
이 bit가 1로 설정되면 해당 file descriptor가 관찰의 대상임을 의미합니다.
위의 그림에서는 file descriptor 1과 3이 관찰대상입니다.
이러한 file descriptor의 숫자를 확인해서 fd_set형 변수의 직접등록을 해야하는 것은 아닙니다.
매크로를 사용합니다.

위의 매크로중 FD_ISSET은 select 함수의 호출결과를 확인하는 용도로 사용됩니다.
select 함수의 1번째 인자는 검사 대상이 되는 file descriptor의 수를 의미합니다.

10번 째 줄 부터 select 함수를 호출하기 위한 준비 단계입니다.
16 번쨰 줄을 보면 listenfd의 값을 3으로 가정해 보자
18번째 줄을 보면 bit vector인 read_set을 모두 0으로 먼저 초기화 합니다.

read_set을 ready_set에 할당해 줍니다. (감시 목록을 유지해주기 위해)
selct 함수는 bit vector가 1인 것만 감시를 해줍니다.
30번째 줄을보면 문제가 발생합니다. echo로 입력을 하는데 EOF를 보낼때까지 입력을 받습니다.
만약 client가 EOF를 보내지 않으면 계속 echo 상태에 놓이게 됩니다. 즉, server가 멈추게 됩니다.
따라서 우리는 EOF가 아니라 server loop를 통해 매번 한개의 text line을 echoing 하는 방법을
생각할 수 있습니다.

위의 그림은 concurrent event의 state machine 입니다.
현재 상태는 descriptor dk를 reading 하기 위해 waiting하는 상태입니다.
그 다음 descriptor dk에 input이 들어오면 reading을 하기 위한 준비 상태입니다.
그 다음 descriptor dk로 부터 한개의 text line을 reading 합니다.
이를 반복합니다.

pool이라는 connected descriptor입니다.
실제 connfd는 수많이 들어오므로 위와 같은 pool이라는 구조체로 관리합니다.
마찬가지로 26 번째 줄을 보면 listenfd가 3이라고 하면
27번째 줄에서 init_pool을 통해 3번째 bit에 1로 setting 해줍니다.

init_pool 함수를 살펴봅니다.
11번째 줄에서 fd_set 자료형인 read_set을 0으로 초기화 합니다.
12번째 줄에서 listenfd 값인 3을 read_set에 setting 해줍니다.

다시 main함수로 돌아와 살펴보겠습니다.
while문을 돕니다. 맨 처음 위에서 봤던 while문과 비슷합니다.
마찬가지로 변수 pool.ready_set에 다가 pool.read_set을 할당해 줍니다.
35번째 줄을 보면 listening descriptor가 FD_ISSET 을 통해 준비 상태가 되있으면
38번 째 줄의 add_client 해줍니다.
42번째 줄을 보면 check_client 함수를 통해 pending input에 뭐가 들어와 있는지 체크하고
echo 해줍니다.

add_client 함수를 살펴봅니다.
12번째 줄을 보면 connfd를 read_set에 setting 해줍니다.

check_client 함수입니다.
Pros and Cons of Event-based Servers
장점
logical control flow가 단 하나입니다.
디버깅 할때도 단일 address space에 logical control flow도 하나이기 때문에 수월합니다.
따라서 고성능 웹서버나 검색엔진에 사용됩니다.
단점
코딩하기가 복잡합니다.
fine-graind concurrency를 제공하지 않습니다. server에 접속한 client를 처리하다가 중간에 다른 fild descriptor에
온 pending input을 처리할 수 없습니다. 따라서 coarse-grained 하게 처리합니다.
multi-core 기능을 적극적으로 활용못합니다.
Approach #3 : Thread-based Servers

CPU와 main memory(DRAM)의 모습입니다.
먼저 Process A는 code(code, data), Stack, Heap 을 가지고 있고 main memory 주소에 해당하는 물리적 위치에
저장됩니다.
Process A의 code부분을 1줄씩 읽어내면서 CPU의 Register에 Instruction Fetch(IF) 합니다.
그러면 register 내부에서 Instruction Decoding(ID)와 Excution(실행)을 합니다.
다시 instruction을 받기 위해 CPU는 main memory에게 write back합니다.
이러한 과정을 Excution Flow(EF)라고 합니다.
Process A는 fork를 통해 Process B를 만들고 Process B는 Process A의 heap, stack, code를 모두 복사해옵니다.
다른점은 메모리 주소만 다릅니다.
이때 thread 개념은 process code부분의 실행단위라고 할 수 있습니다. 각각의 Excution Flow를 가집니다.
즉, 어느 process라도 무조건 최소 1개이상의 thread가 존재합니다.
이러한 한 process에서 thread를 많이 가지면 멀티 thread라고 합니다.
thread는 stack을 제외하고 나머지 부분을 공유합니다.
이러한 thread를 가지고 server를 구축 할 수 있습니다.
process-based와 매우 유사하지만 thread를 사용한다는 점에서 차이점이 있습니다.
Traditional View of a Process

process의 구성요소 입니다.
Alternate View of a Process

Thread의 구성요소입니다.
process와 다른점은 process의 stack과 program context를 thread로 봅니다.
main thread를 fork를 한다고 하면 stack과 thread context만 복사되고 나머지 부분은 공유자원으로 남습니다.
A Process With Multiple Threads

하나의 process와 여러개의 thread가 공존할 수 있습니다.
각 thread는 각자의 logical control flow를 가집니다.
각 thread는 같은 code, data 그리고 kernel context를 공유합니다.
각 thread는 각자의 지역변수를 위한 stack을 가지고 있습니다.
(그러나 다른 thread로 부터 이것을 지킬 수 없습니다.) OS가 Process 단위로 메모리를 할당하므로
같은 process 소속의 thread들은 메모리를 공유합니다.
각 thread는 각자의 thread id (TID)를 지닙니다.
Logical View of Threads

왼쪽은 thread 가 fork 되는 그림이고 오른쪽은 process가 fork되는 그림입니다.
Concurrent Threads

thread 관점에서 보면 두 개의 thread는 그들의 excution flow가 시간에 따라 겹칠 수 있어 concurrent 하다고 합니다.
위의 그림을 보면 thread A &B , A & C과 concurrent입니다.
B & C는 sequential 입니다.
Concurrent Thread Execution

왼쪽은 single core, 오른쪽은 멀티 core입니다.
Thread vs Process
thread는 process와 달리 code와 data, heap부분을 공유하기 때문에
동시에 여러작업을 할때, 멀티 thread가 시스템 자원을 더 적게 사용합니다.
20번 cycle 돌걸 thread는 10번 cycle을 돕니다.
thread의 경우 공유 자원에 대한 동기화(Synchronize) 이슈 발생
Posix Threads (Pthreads) Interface
pthreads는 C 프로그램에서 제공하는 thread를 다루는 대략 60개의 기본 함수들입니다.
Creating and reaping threads
- pthread_create() ≒ fork()
- pthread_join() ≒ wait()
Determining your thread ID
- pthread_self() ≒ getpid()
Terminating threads
- pthread_cancel()
- pthread_exit()
- exit() [모든 thread를 종료시킵니다.]
Synchronizing access to shared variables (공유 변수가 있다면 synchronizing 해야합니다)
- ptherad_mutex_init
- pthread_mutex_[un]lock
The Pthreads "hello, world" Program
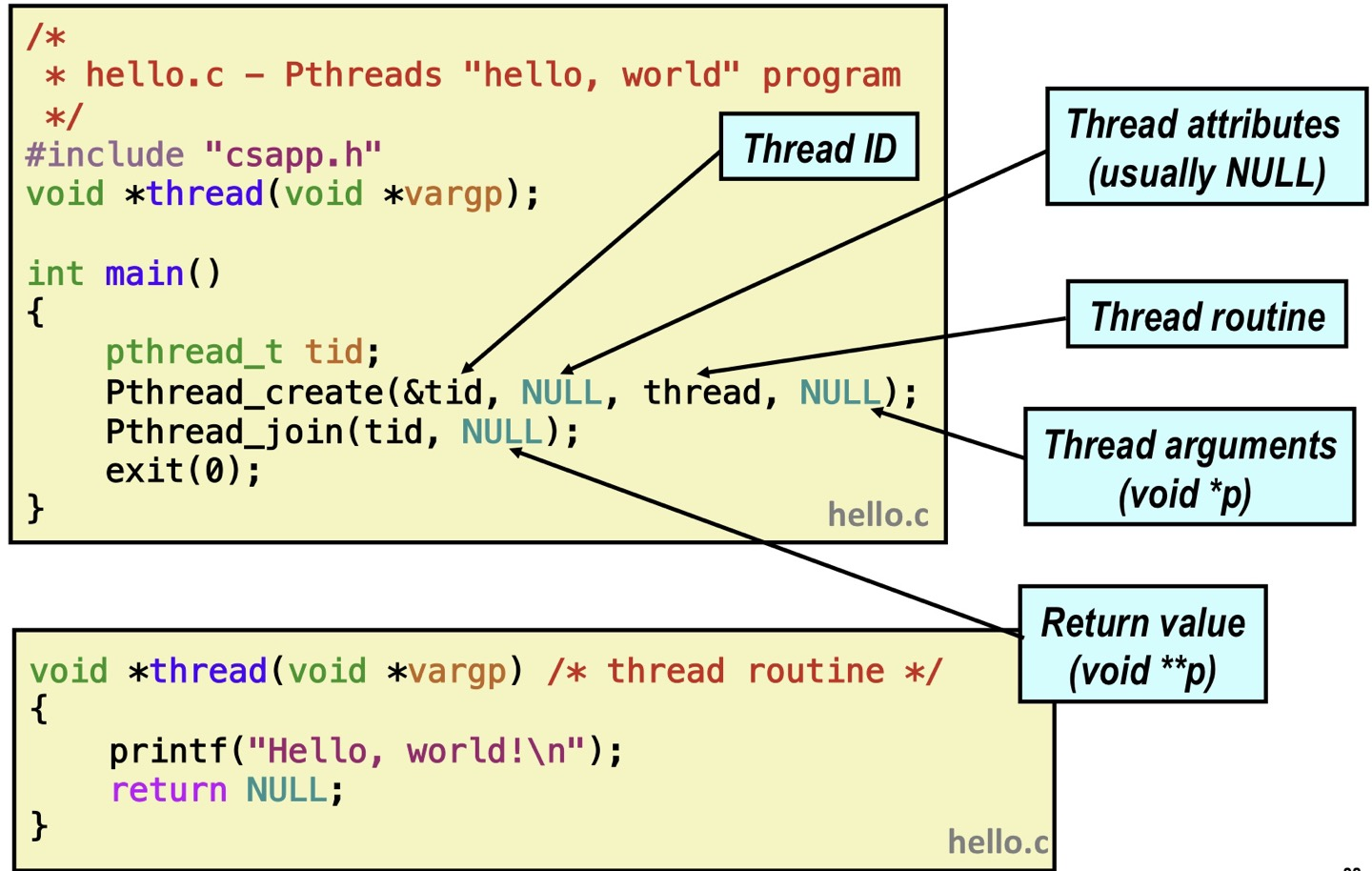
main 함수 내의 Pthread_create를 통해 새로운 thread(exection flow)를 만듭니다.
인자로 thread id를 받고 thread가 실행할 함수를 넣어줍니다.
Execution of Threaded "hello, world"

process가 fork하고 wait하는 과정과 매우 유사합니다.
만약 CPU가 한개라면 각 thread의 실행 사이의 context switch가 이루어집니다.
Thread-Based Concurrent Echo Server

main thread의 stack 영역에 connfdp가 들어가 있습니다. 이 connfdp는 heap의 저장되있는 data를 가리키는
포인터입니다.
client가 connection 요청이오면 server에서는 listenfd를 통해 받고 accept을 하면
connfd를 통해 fork를 해 client와 연결해줍니다.
마찬가지로 thread 기반의 echo server는 Pthread_create을 통해 peer thread를 만들어줍니다.
넘길 때는 connfdp의 주소값을 넘겨줍니다. 예를 들어 connfdp의 주소값이 0x8000이라고 한다면
peer thread는 0x8000을 통해 heap의 data로 접근이 가능합니다.

peer thread가 실행하는 함수입니다.
Pthread_detatch 함수는 다른 thread와 독립적으로 하면서 현재 thread가 종료되면 kernel이 자동적으로
reaping할 수 있게합니다.
echo를 해주고
마지막에 connfd를 close해줍니다. (메모리 누수 방지)
Thread-based Server Execution Model

connection 요청이 들어오면 각각의 thread를 만듭니다.
이 thread들은 pid는 다르지만 하나의 process안에 있기 때문에 code, kernel, data, heap을 공유합니다.
Issues With Thread-Based Servers
"detached"는 메모리 누수를 막기위해 꼭 필요합니다.
thread는 join 또는 detatch를 통해 thread의 reaping을 요청할 수 있습니다.
join은 다른 thread에 의해 reaping 될 수 있습니다.
thread는 다른 thread에 의해 reaping이 될 수 없습니다. 자동적으로 reaping 됩니다.
기본형은 join입니다.
unintended sharing을 피해야합니다.
thread들 끼리 서로 공유되므로 충돌이 발생합니다.
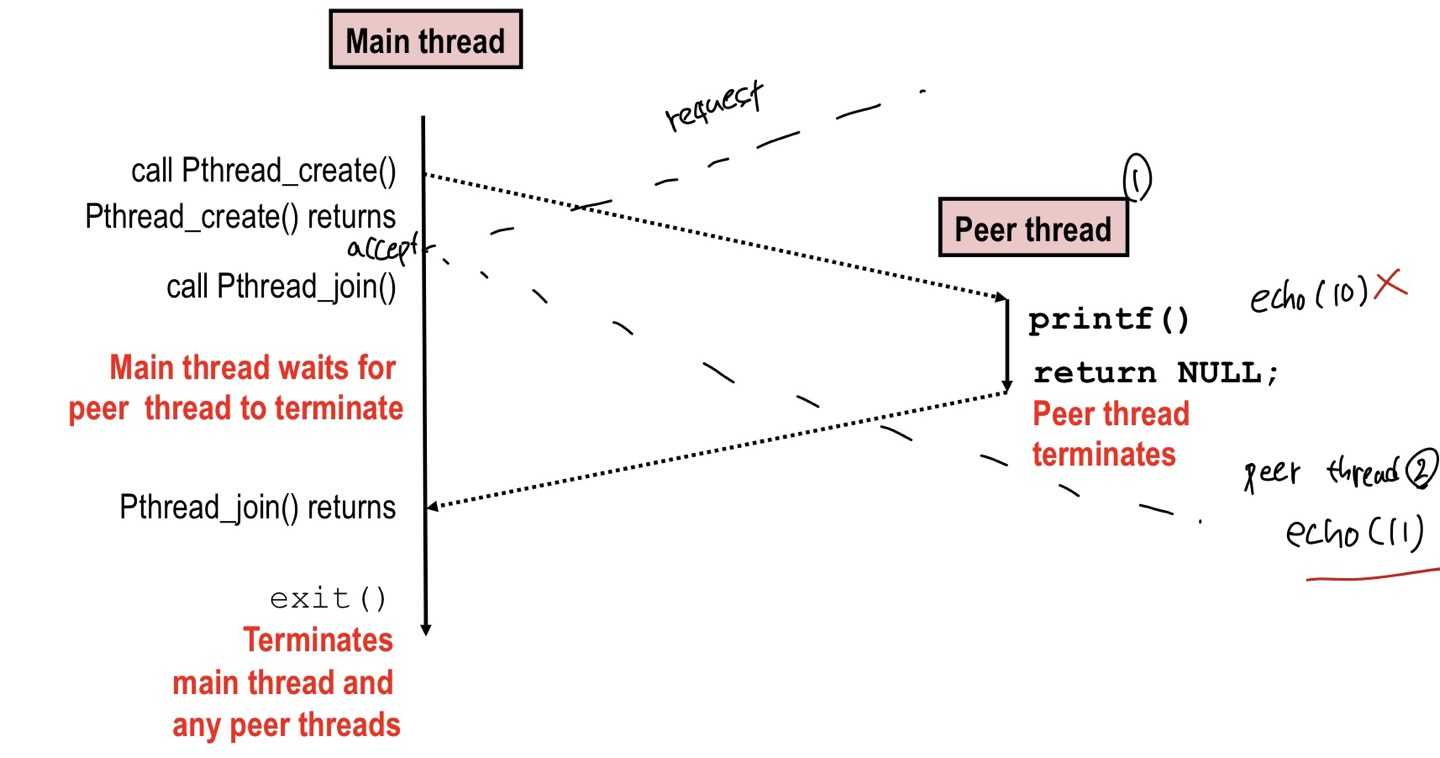
어느 한 client로 부터 connection 요청이 오면 accept하면 peer thread 1이 만들어집니다.
근데 그 사이에 또 다른 client로 부터 connectionl 요청이와 accept 하게 되면 peer thread 2가 만들어집니다.
이제 peer therad는 connfd를 echo 해야하지만 공유되는 connfd는 peer thread 2를 만들게 되면서 10이 아니라
11이 되어 있습니다. 따라서 peer 1은 10을 출력하지 않고 11을 출력하고 peer 2 는 정상적으로 11을 출력하게
됩니다.
Pros and Cons of Thread-Based Design
장점
thread들 끼리 서로 공유하고 있어서 data share가 쉽습니다.
context switch overhead도 줄어듭니다.
단점
의도하지 않은 data sharing이 일어날 수 있습니다.
'시스템 프로그래밍' 카테고리의 다른 글
Synchronization : Advanced (0) 2022.05.13 Synchronization : Basics (0) 2022.04.20 Network Programming : Part 2 (0) 2022.04.14 Network Programming : Part 1 (0) 2022.04.12 System-Level I/O (0) 2022.04.05