-
File System운영체제(OS) 2022. 12. 15. 17:20728x90
What is File System?
우리가 평소 사용하는 application은 process address space에 data를 저장할 수 있습니다.
이것이 과연 충분할까???
data의 크기는 virtual address space에 제한받고, data는 application이 사라질 때 잃게 되고,
다수의 process들은 똑같은 data에 access하기를 원할지도 모릅니다.
이를 위해 영구적인 정보들을 위한 몇가지 기준이 생겼습니다.
먼저 매우 큰 정보들을 저장할 수 있어야 합니다.
두번째로 정보는 process가 사용하는 동안 무조건 살아있어야 합니다.
세번째로 여러 process에 동시에 access할 수 있어야 합니다.
이를 해결할 수 있는 것이 File입니다.
File은 논리적인 저장 단위로, 관련된 정보 자료들의 집합에 이름을 붙인 것입니다.
file은 OS에 의해 물리 장치들로 맵핑되고, 일반적으로 비휘발성 특성을 지니기 때문에, 전원이 끊어진 상황에서도
정보들을 영구히 보존할 수 있습니다. 보통 disk에 저장됩니다.
File system은 OS와 모든 data, 프로그램의 저장과 access를 위한 기법을 제공합니다.
시스템 내의 모든 file에 관한 정보를 제공하는 계층적 디렉토리 구조이고, file 및 file의 metadata, 디렉토리 정보 등을
관리 합니다.
File System Framework

File and File Structure
File
file은 secondary storage에 기록된 관련 정보 모음입니다.
user 관점에서 file은 논리적 secondary storage의 가장 작은 unit 입니다.
즉, file 내에 있지 않으면 데이터를 secondary storage에 write할 수 없습니다.
File Structure
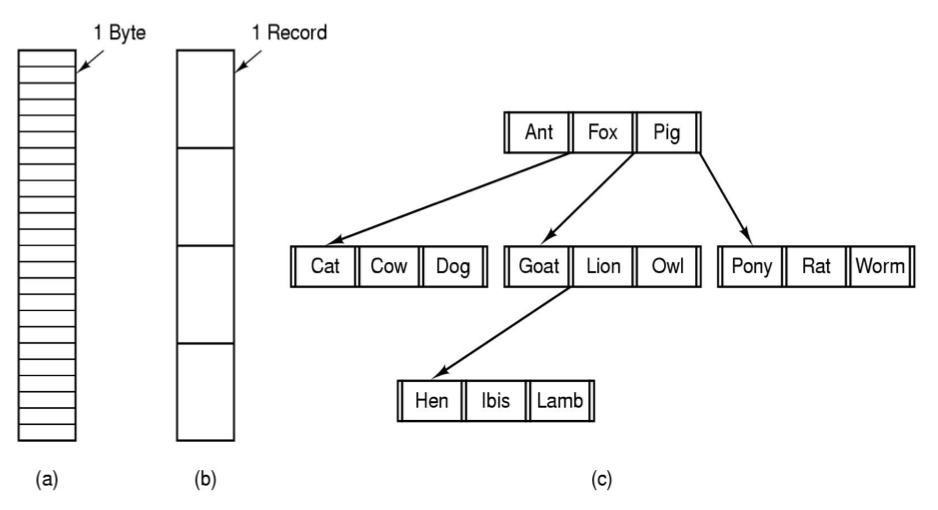
(a), (b), (c)는 file의 구조 들입니다.
(a)는 체계가 없는 byte sequence 입니다.
(b)는 record sequence입니다. record에서의 r/w, sector 크기와 관련
(c)는 복잡한 구조로 되어있습니다.(tree)
File Name and Extension
File Name
file은 disk에 저장된 정보를 abstract(요약) 합니다.
우리는 block이나 sector를 기억할 필요가 없으며, 대신 사림이 읽을 수 있는 이름을 원할 수 있습니다.
process는 file을 생성하고, 이름을 지정합니다.
다른 process들은 해당 이름으로 file에 access할 수있습니다.
naming 규칙들은 OS에 달려있습니다.
일반적으로 255자 까지의 이름을 사용할 수 있습니다.
숫자와 특수 문자가 허용되는 경우도 있습니다.
File Extension
파일 이름은 일반적으로 이름 + 확장자의 두부분으로 나뉩니다. (ex : kangyuseok.txt)
Unix에서 확장자들은 OS에 의해 강제되지 않습니다.
일부 application(ex: C 컴파일러)은 확장자를 고집할 수 있습니다.

Access Methods
시스템이 제공하는 file 정보의 access 방식으로는 sequential access(순차 접근)과 direct access(직접 접근)으로
나뉠 수 있습니다.
Sequential Access
file의 정보가 record 순서 대로 처리됩니다.
현재 위치에서 read하거나 write하면 offset이 자동으로 증가하고, 뒤로 돌아기기 위해서는
지정한 offset만큼 rewind(되감기)해야 합니다.
(테이프 와 같습니다.)
Direct Access
file의 record를 임의의 순서로 접근할 수 있습니다.
read 또는 write의 순서에 제약이 없으며 현재 위치를 유지할 수 있다면 이를 통해 sequential access기능도
구현할 수 있습니다.
대규모 정보를 즉각적으로 접근하는 데 유용하여 데이터 베이스에 이용됩니다.
File Attributes
file은 몇가지 속성을 가지고 있습니다. 즉, metadata를 가지고 있는데 이는 file을 관리하기 위한
각종 정보들입니다. file자체의 내용은 아닙니다.
file 이름, 유형, 저장된 위치, 크기, 접근 권한, 소유자, 시간(생성/변경/사용) 등 file에 대한 전반적인 정보들입니다.
Name : 사림이 읽을 수 있는 형태로 유지되는 유일한 정보
Identifier : file 시스템 내에서 file을 식별하는 고유의 번호 PK
Type : 여러 type의 file을 제공하는 시스템을 위해 필요
Location : 장치 내에서 file의 위치를 가리키는 포인터
Size : file의 현재 크기
Protection : 접근 제어 정보
Time, date, user identification : 생성, 최근 변경, 최근 사용에 대한 정보
모든 file에 대한 정보는 secondary storage에 상주하는 directory structure 내에 유지됩니다.
file과 directory 모두 비휘발적 성질을 가져야 하므로, 저장 장치 상에 저장되고, 필요할 때 조금씩 메모리로
가져와야 합니다.
Directory Structure
file을 만들 때 해당 FCB(File Control Block)도 하나 만들어 집니다.
FCB는 일반적으로 file attribute를 포함합니다.
file에 대한 정보는 FCB의 정보 또는 FCB로의 포인터를 포함하는 디렉토리 구조에 보관 됩니다.

디렉토리 구조, FCB 및 file이 disk에 상주합니다.
또한 성능을 향상시키기 위해 메모리에 cach 됩니다.
File / Directory Operations
OS는 file과 디렉토리를 관리하고 연산하기 위해 여러 system call을 제공합니다.
Create : 사용할 수 있는 공간을 찾고 file을 할당합니다. 또한 file이 디렉토리 에 만들어져야 합니다.
Delete : 지명된 file을 디렉토리에서 찾습니다. 발견하면 file이 차지하는 공간을 방출하고 디렉토리 항목을 삭제합니다.
Read : file이름과 file이 읽혀 들어갈 block의 위치를 명시하는 system call을 호출합니다.
Write : file이름과 기록될 정보를 명시하는 system call을 호출합니다.
Seek : file안에서의 위치를 재설정합니다. 디렉토리에서 적합한 항목을 탐색하고, 현재 file 위치를 주어진 값으로
설정합니다.

Truncate, ftruncate : file의 크기를 변경합니다.

디렉토리의 연산은 다음과 같습니다.
Search : 특정 file에 해당하는 항목을 찾기 위해 탐색이 가능해야 합니다. 특정 패턴과 일치하는 이름을 갖는
모든 file을 찾을 수 있어야 합니다.
Create : 새로운 file들을 생성하여 디렉토리에 추가합니다.
Delete : 디렉토리에서 file 제거
List : 존재하는 file들을 나열하고 내용 보여주기
Rename : 이름 바꾸기
Traverse the file system : file system의 모든 디렉토리를 순회하면서 모든 file들을 access할 필요가 있습니다.
전체 file system을 주기적으로 백업할 때
How to Organize a Directory?
Efficiency : file 빨리 찾기
Naming : user에게 편리함
ex) 두명의 user가 같은 이름의 다른 file을 가질 수 있다.
같은 file이 몇개의 다른 이름으로 존재
Grouping : 같은 특성의 file 끼리 논리적 그룹핑
논리적 구조를 이루는 디렉토리는 다음과 같습니다.
Single level directory
Two level directory
Tree structured directory
Acyclic graph directory
General graph directory
Single-Level / Two-Level Directory
Singlel-Level
1단계 디렉토리는 모든 file들이 디렉토리 밑에 존재하는 형태 입니다.
file들은 서로 유일한 이름을 가지고 서로 다른 사용자라도 같은 이름을 사용할 수 없습니다.
지원하기도 쉽고, 이해하기도 쉽지만, file이 많아 지거나 다수의 사용자가 사용하는 시스템에서는
심각한 제약을 갖습니다.

Two-Level
2단계 디렉토리는 각 사용자별로 별도의 디렉토리를 갖는 형태입니다.
서로 다른 사용자가 같은 이름의 file을 가질 수 있고, 효율적인 탐색이 가능합니다.
하지만 grouping이 불가능하고, 다른 사용자의 file에 접근해야 하는 경우에는 단점이 있습니다.

master file directory : 사용자의 이름과 계정 번호로 indexing 되어 있는 디렉토리,
각 항목은 사용자의 user file directory를 가리킵니다.
user file directory : 자신만의 사용자 file 디렉토리
Tree-Structured Directories
two-level 디렉토리를 확장하여 다단계 tree구조로 만들 수 있습니다.
사용자들이 자신의 sub-directory를 만들어서 file을 구성할 수 있습니다.
하나의 root directory를 가지며, 모든 file은 고유한 경로(절대 경로/상대 경로)를 가집니다.
이를 통해 효율 적인 탐색이 가능하고, grouping이 가능합니다.

Acyclic-Graph Directories
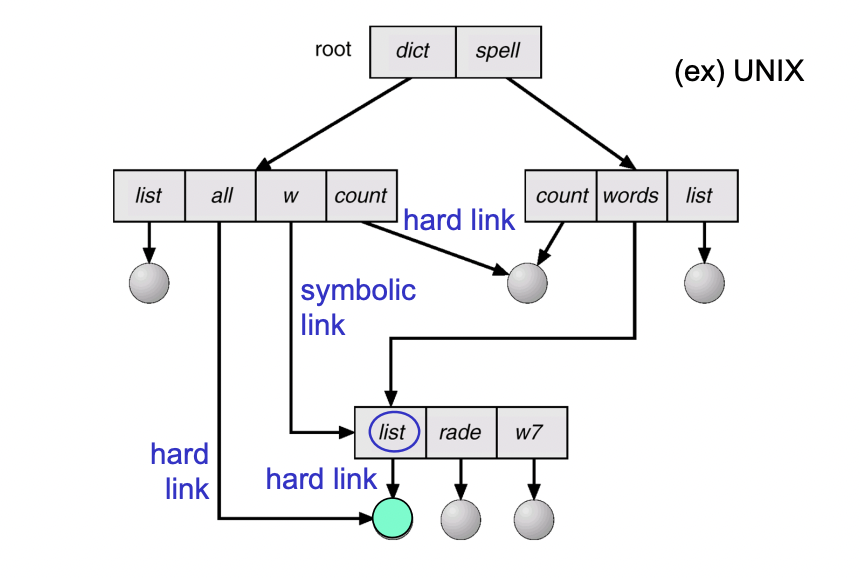
디렉토리들이 link를 사용해 sub-directory들과 file을 공유할 수 있도록 합니다.
tree 구조의 directory를 일반화한 형태입니다.
단순한 tree 구조 보다는 더 복잡한 구조이기 때문에 몇몇 문제가 발생할 수 있습니다.
file이 여러개의 경로명을 가질 수 있기 때문에 file을 순회하거나 할 때, 동일한 file을 중복적으로 탐색하는 경우가
생길 수 있습니다. (ailasing problem)
file을 무작정 삭제하게 되면 현재 file을 가리키는 포인터는 대상이 사라지게 됩니다. (soft link = symbolic link)
한 디렉토리에서 공유된 file을 삭제할 경우, 고아 포인터가 발생하는데, 이는 바로가기를 눌렀을 때 해당 file이
없다는 문구가 뜨는것을 생각하면 됩니다.
따라서 참조되는 file에 참조 계수를 두어서, 참조 계수(reference count)가 0이 되면
file을 참조하는 link가 존재하지 않는 다는 의미이므로 그때 file을 삭제할 수 있도록 합니다.(hard link = non symbolic link)
예를 들어 dict가 count를 삭제하는 경우 (dangling pointer problem)
Hard Link vs Soft Link in UNIX
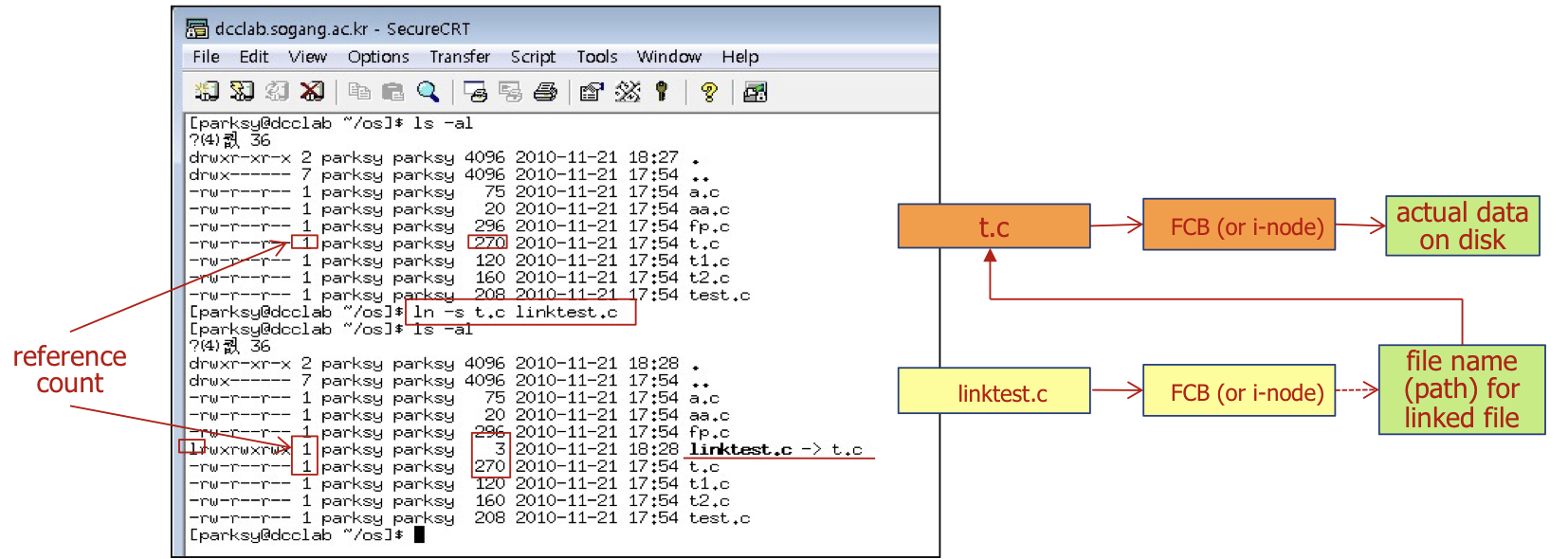
Hard link( = non symbolic link)는 ln 이라는 명령어로 생성될 수 있습니다.
예를 들어 ln t.c linktest.c를 하면 t.c에 대한 hard link가 linktest.c를 가리킵니다.
file에 대해서만 가능하고, 한 file system에서만 가능합니다. hard link는 원본 file과 직접 연결된 복사본을
생성하는 것과 같습니다. 즉, hard link를 통해 file을 수정하면 원본 file도 수정됩니다.
동일한 FCB를 사용하고, reference count를 늘립니다.
rm 명령어는 reference count가 0일 경우에만 실제 file을 삭제합니다.
dangling pointer 문제를 걱정할 필요가 없습니다.

Soft link ( = symbolic link) ln -s 명령어로 생성될 수 있습니다.
예를 들어 ln -s t.c linktest.c를 하면 t.c에 대한 soft link가 linktest.c를 가리킵니다.
file 또는 디렉토리에 대한 포인터로, soft link를 삭제해도 이는 file에 영향을 주지 않습니다.
window에서 일반적으로 사용하는 바로가기 아이콘과 같습니다.
다른 FCB를 사용합니다.
다른 filesystem에서도 생성이 가능합니다.
dangling pointer 문제를 겪을 수도 있습니다.
General Graph Directory
cycle을 허용하는 그래프 구조입니다.
이러한 경우 무한 loop에 빠질 수 있습니다. 따라서 하위 디렉토리가 아닌 file에 대한 link 만 허용하거나
garbage collection을 통해 전체 file system을 순회하고, 접근 가능한 모든것을 표시합니다.
garbage collection은 전체 file system을 순회해 접근할 수 있는 file에 표시하고, 두번째 탬색에서는
표시하지 않은 메모리를 사용가능 메모리 list에 추가합니다.

Protection
file 접근에는 몇가지 유형이 있습니다.
Read
Write
Execute
Append(추가)
Delete
List
Access Control List
많은 사용자들은 각 file 또는 디렉토리에 다른 유형의 access를 사용하기를 원합니다.
이는 ACL(Acess Control List) 각 file 또는 디렉토리의 access 권한의 정보가 담겨있는 리스트입니다.
ACL의 장점에는 복잡한 접근을 가능하게 합니다.
단점은 고정 크기 였던 디렉토리 항목은 이제 가변 크기가 되어, 결과적으로 공간관리가 더 복잡해 집니다.
Window 7
window 7의 ACL 입니다.

UNIX
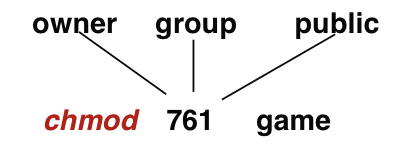
3가지 mode로 되어있습니다. (read, write, execute)
3가지 사용자 class가 있습니다
1. owner : file의 생성자
2. group : file을 공유하며 owner와 유사한 접근이 필요한 user들의 집합
3. public : 시스템에 있는 모든 user들

위의 예시를 보면 owner는 현재 read, write, execute 모두 권한을 가질 수 있습니다.
group은 read, write는 권한을 가지지만 execute권한을 가질 수 없습니다.
public은 오직 execute권한만을 가질 수 있습니다.
예를 들어 'game' 이라는 file을 만들어 권한을 부여할 때 다음과 같은 명령어를 사용합니다.

Sample Directory Listing in UNIX Partitions
partition은 연속된 저장공간을 하나 이상의 연속되고 독립적인 영역으로 나누어 사용할 수 있도록 정의한 규약
입니다.
disk를 여러 partition으로 분할 하거나 partition을 여러 disk에 걸쳐 분할할 수 있습니다.
즉, 물리적인 disk를 논리적 저장 영역으로 구별한것입니다.
각 partition은 날것입니다.(swap 공간 또는 데이터베이스 등 을 포함하지 않음)
또한 file system을 포함하여 변형될 수 있습니다. (사용자가 접근할 partition을 포멧 해야함)

volume은 단일 file system을 사용해 접근할 수 있는 저장공간입니다.
즉, file system으로 포멧된 disk상의 저장영역입니다.
하나의 partition당 하나의 volume
File System Layout
file system은 disk에 저장됩니다.
disk는 1개 또는 여러개의 partition으로 분할 되어있습니다.
disk의 0번 sector는 MBR(Master Boot Record)이라고 불립니다.
MBR의 끝에는 partition table(partition의 시작 및 끝 주소)이 있습니다.
각 partition의 첫번째 block에는 boot block이 있습니다.
MBR에 의해 load되고 부팅 시 실행됩니다.

Mounting
mounting은 다른 file system을 root 디렉토리의 하위에 새로운 file system을 붙이는 것으로
서로 다른 file system을 접근할 수 있게 해주는 것입니다.
file system은 사용되기 전에 반드시 mount되어야 합니다.
디렉토리 구조는 file system내의 name 공간 내에 mount되어야 하는 여러 volume으로 구성될 수 있다.
OS kernel을 포함하는 root partition은 부팅 시 mount 됩니다.
다른 partition은 부팅 시 자동으로 mount 되거나, 나중에 수동으로 mount할 수 있습니다.

Virtual File System (VFS)

여러 file system을 투명하고 균일하게 지원하는 file system 추상화 계층입니다.
VFS interface를 정의하여 file system 계층 작업을 구현과 분리합니다.
다른 유형의 file system에 동일한 system call interface(API) 를 사용할 수 있습니다.
VFS는 vnode라고 하는 file 표현 구조를 기반으로 합니다.
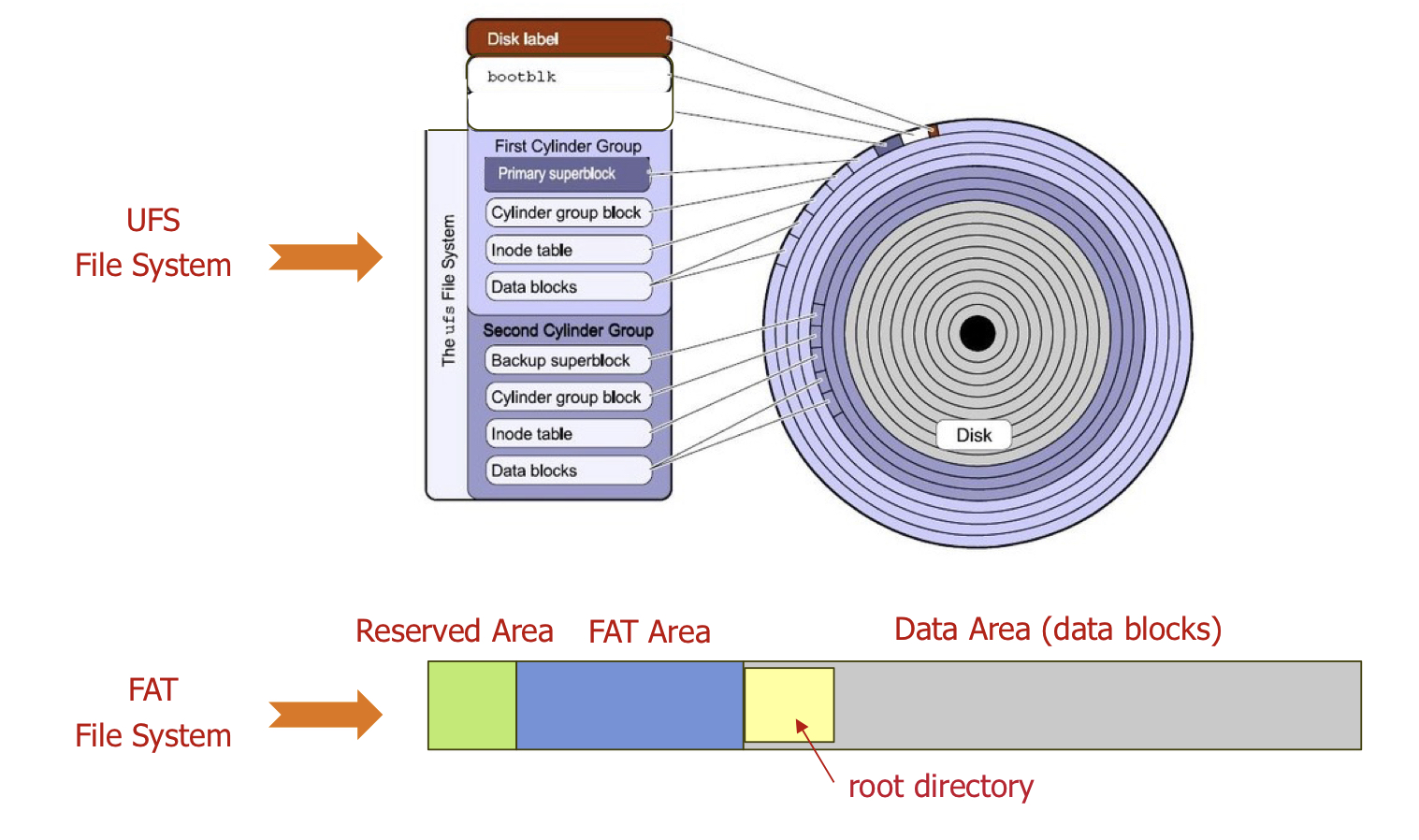
On-Disk Data Structures
file system은 secondary storage에 저장되있습니다.(disk)
구현을 위해 file system은 disk 구조와 memory 구조를 모두 가지고 있습니다.
On-disk
Boot Control Block
시스템이 partition에서 부팅 하는데 필요한 정보가 포함되어 있습니다.
일반적으로 partition의 첫번째 block
boot block(UFS) 또는 partition boot sector(NTFS)
Volume Control Block
partition의 block 수와 크기, 사용가능한 block 수와 pointer, 사용 가능한 FCB(File Control Block)의 수
등 과 같은 partition 세부 정보를 포함합니다.
super-block(UFS) 또는 master file table(NTFS)라고도 합니다.
Directory structure
File Control Block(FCB)
flie의 많은 세부정보가 포함되어 있습니다.
inode(UFS)라고도 합니다.
In-Memory Data Structures
caching을 통해 file system관리 및 성능 향상에 모두 사용됩니다.
In-memory mount table
mount된 각 volume에 대한 정보가 포함되어 있습니다.
In-memory directory structure
최근 access한 디렉토리의 정보가 들어 있습니다.
System-wide open-file table
open file의 FCB 복사본이 포함되어있습니다.
Per-process open-file table
시스템 전체 open file table의 해당 항목에 대한 pointer가 포함되어 있습니다.
Buffers
disk에서 read 또는 write할 떄 file system block을 보유합니다.

Directory Implementation
Array
디렉토리 항목에 대한 배열
Linear List
data block에 대한 pointer가 있는 file 이름의 선형 목록
simple to program
time-consuming to execute
하지만 file을 탐색하는데 선형시간이 걸립니다.
Hash Table
hash 자료구조로 된 선형 목록
디렉토리 탐색 시간 낮아짐
두 개의 file 이름이 hash를 통해 같은 위치에 저장될 수 있는 collision 발생 가능
문제점은 고정된 크기 때문에 새로운 file이 들어오면 table에 새로운 항목을 만들기위해
새로운 hash function과 디렉토리를 reorganizing 해야 합니다.
Block Allocation
file system은 track/sector 대신 block(다수의 sector)을 사용하여 disk의 주소를 지정합니다.
block 할당 방법은 file에 disk block을 할당하는 방법을 의미합니다.
크게 3가지 방법이 있습니다.
Contiguous allocatoin
Linked allocation
Indexed allocation
Contiguous Allocation (연속 할당)

각 file은 disk의 contiguous(연속) block 집합을 차지합니다.
시작 위치(block 번호) 와 길이(block 수)가 필요합니다.
장점은 빠른 I/O를 갖습니다.
한번의 탐색으로 많은 양의 transfer가 가능합니다.
direct access(random access)가 가능합니다.
단점은 external fragmentatoin이 발생할 수 있고, file grow에 제약이 있습니다.
file grow란 14 ~ 16을 6개의 block으로 늘리면 불가능한것을 의미합니다.
미리 빈공간을 어느정도 확보하면 grow를 해결할 수 있지만 internal fragmentation이 발생할 수 있습니다.
Linked Allocation

각 file은 disk block의 linked list입니다. block은 disk의 모든 곳에 흩어져 있을 수 있습니다.
오직 start 주소만 필요합니다.
Free-space management를 통해 공간 낭비가 없습니다.
장점에는 external fragmentation이 발생하지 않습니다.
단점은 direct access(random access)가 불가합니다.
또한 중간 sector가 고장나면 pointer가 유실 되어 link된 list들이 연달아 유실 됩니다.
또한 pointer를 위한 공간이 block의 일부가 되어 공간 효율성을 떨어뜨립니다.
하지만 이는 FAT(File Allocation Table)에 보관하여 문제를 해결할 수 있습니다.
File-Allocation Table (FAT)


data block의 개수만큼 각 block의 다음위치에 대한 정보를 담고 있습니다.
디렉토리가 file의 이름과 file의 metadate 정보와 file의 start block 번호를 담고 있습니다.
direct access가 가능합니다.
FAT는 table이라 메모리에 올라가 있습니다. 실제 file을 까봐서 다음 access로 가는 것이 아니라 바로 access가
가능합니다.
Indexed Allocation

모든 pointer를 index block으로 가져옵니다.
장점은 random access가 가능합니다.
또한 external fragmentation이 발생하지 않습니다.
단점은 file이 너무 작은 경우도 block이 적어도 2개는 필요합니다.
file 이 굉장히 큰 경우 하나의 block으로 index를 저장하기 부족합니다.
Combined Scheme : UNIX
UNIX에서의 file system구조를 보여줍니다.


Example - Accessing the Block
block 의 크기 = 1024 bytes, 10 direct, indirect/double/triple = 1

Case 1 : acess byte offset 9000 of a file
9000 / 1024 = 8.xxx 이므로 8번째 block에 있을 것입니다.
8번째 direct는 367입니다.
9000 - 1024 * 8 = 808
즉, 8번째 block의 808번째로 가면 됩니다.
Case 2 : access byte offset 350,000 of a file
먼저 offset이 매우큽니다.
direct영역은 1024 * 10 = 10 * 2^10 = 10KB 입니다.
따라서 direct영역은 넘어갑니다.
single 영역은 pointer 하나 당 4byte를 차지 하므로 한 data block를 가리키는 pointer의 개수를 구해야합니다.
pointer의 개수는 1KB(1024) / 4 = 256입니다.
single = 1KB이므로 1KB * 256 = 256KB
따라서 시작 위치는 350,000 - 10KB + 256KB = 350,000 - 272,384 = 77,616
Example - Maximum File Size


Free Space Management
Linked list (Free list)

빈 block을 linked list로 관리합니다.
list를 순회할 때 모든 block을 read하므로 비효율적입니다.
연속적인 free space를 찾는 것이 쉽지 않습니다.
하지만 공간 낭비는 없습니다.
Bit vector
빈 block을 bit map 또는 bit vector로 관리합니다.
각 block은 1bit로 표현됩니다. (free = 1 / allocated = 0)
free block을 찾는 것이 빠릅니다.

bit map은 메모리에 추가적인 공간을 요구합니다.
block 의 크기 = 2^12 bytes = 4KB
disk의 크기 = 2^30 bytes = 1GB
bit map의 크기 n = 2^30 / 2^12 = 2^18 bits (2^18개의 block)
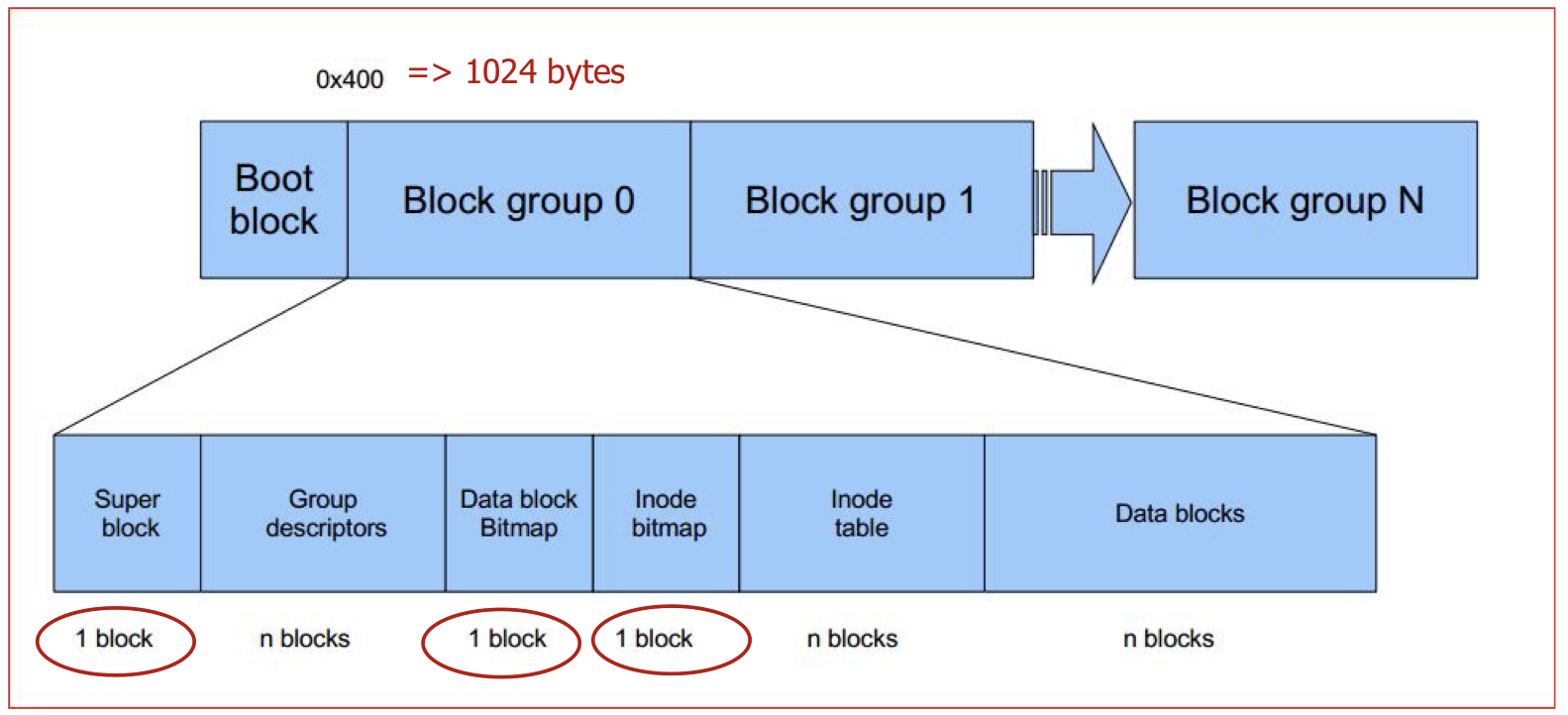
Free Space Management in Linux FS
Example Question
'운영체제(OS)' 카테고리의 다른 글
Chapter 10 (Virtual Memory) (0) 2022.12.10 Chapter 9 (Main Memory) (0) 2022.11.21 Chapter 5 (CPU Scheduling) (0) 2022.10.26 Chapter 6 - 7 (Synchronization Tools and Examples) (0) 2022.10.22 Chapter 4 (Thread and Concurrency) (0) 2022.10.19