-
Exceptional Control Flow : Exceptions and Processes시스템 프로그래밍 2022. 3. 10. 14:50728x90
Control Flow (제어 흐름)
process(CPU)는 사용자가 전원을 키고 끌때 까지 단순히 메모리에 있는 instruction들을 순차적(seqential)으로
차례대로 한번에하나씩 실행합니다. 이러한 flow를 Control Flow라고 합니다.
Altering the Control Flow
그러나 우리는 하나의 프로그램만을 실행하는 것이 아니라 여러개의 프로그램을 동시에 실행할 수 도 있습니다.
그렇게 되면 CPU 입장에서는 순차적으로 instruction들을 수행하지 못할 수 있습니다.
따라서 순차적으로 진행하는 control flow를 바꿔줄 필요가 있습니다.
예를 들어 Jump나 branch같은 분기 명령어나, 함수 Call, go to문, 함수 return등 을 통해
Program state를 변경해 줍니다.
그러나 program state를 변경하기 어려운 경우가 있습니다.
1) disk or network adapter에서 data를 가져올 경우
2) 0으로 나누라는 instruction이 발생한 경우
3) Ctrl + C 를 키보드에서 누를 경우
4) 시스템 timer가 만기 된 경우
이러한 경우 program state를 변경하는게 아닌 system state를 변경해 주어야 합니다.
이러한 경우를 exception이라고 합니다.
따라서 이와 같은 상황 발생시 control(제어권)을 사용자의 process가 아닌 OS에게 넘겨주어야
합니다.
Exception
위에서 본것같이 system state를 변경해야하는 경우를 exception이라고 합니다.
exception이 발생하면 OS입장에서 control flow를 변경할 필요가 있습니다.
이때 OS에 있는 exception handler가 수행됩니다.
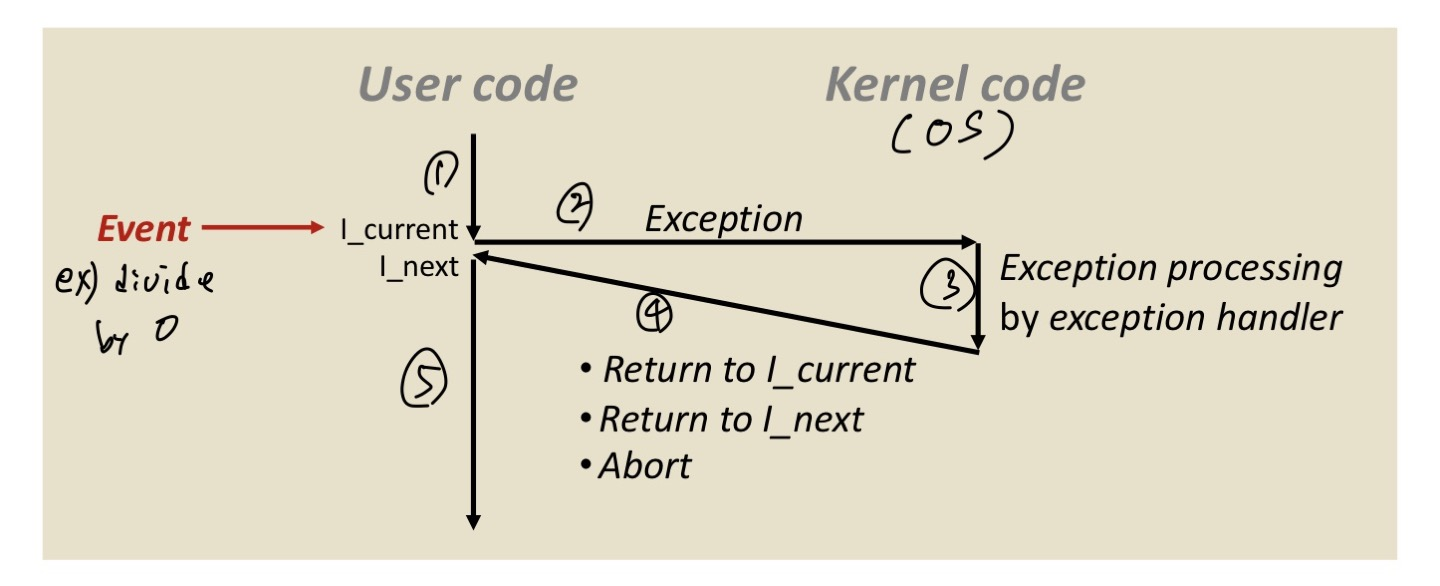
1) I_current 에서 exception event가 발생합니다.
2) exception이 발생하여 제어권을 Kernel code(OS)로 옮깁니다.
3) OS에서 exception handler를 통해 예외 처리를 해줍니다.
4) 다시 제어권을 사용자의 processor로 옮기는데 3가지 명령이 존재합니다.
1. 다시 I_current로 돌아가기
2. I_next로 돌아가기
3. 종료하기
Exception Tables

exception의 종류는 너무 많기 때문에 exception handler는 numbering을 통해 각각의 exception들을
table 형태로 관리합니다. 따라서 exception이 발생할 때마다 해당 table에 접근해 수행합니다.
각 table 마다 exception handler를 가리키는 포인터가 존재합니다.
Classes of Exceptions (exception의 구분)

Asynchronous exception(비동기)
외부적 요인에 의해 발생하는 exception입니다. 보통 Interrupt라고도 합니다.
외부의 exception이기 때문에 정해진 기준이 없고 예측이 불가능합니다.
우리는 보통 키보드로 Ctrl +C 나 Ctril + alt + del 같은 사용자가 주는 exception은
CPU가 매번 exception을 발생할것에 대해 대비하지 않습니다.
발생빈도가 낮은 exception에 대비하는것은 성능저하를 야기할 수 있기 때문입니다.

PIC Cotroller 프로그램이 실행되고 instruction fecth할때 interrupt를 체크합니다.
이때 33/34 pin에 INT0/INT1이라고 써져있는것이 보입니다. 이 PIN을 통해 Interrupt의 발생여부를
체크합니다. pin이 high가 되면 이에 맞는 interrupt handler를 호출해 해결하고 next instruction으로
return 합니다.

Synchronous exception(동기)
예측 가능하고 주기적으로 발생할 수 있습니다.
synchronous exception은 크게 세가지로 나눌 수 있습니다.
1) Trap
instruction의 결과로 발생하는 의도적인 exception입니다.
interrupt handler와 마찬가지로 트랩이 발생한 instruction의 next instruction으로 return 합니다.
trap의 가장 중요한 용도는 System call로 알려진 사용자 프로그램과 Kernel 사이에 interface를
제공하는 것입니다.

사용자 프로그램은 종종 read, fork, execve, exit 같은 서비스를 Kernel로 부터 요청해야 합니다.
이러한 커널 서비스에 대한 제어된 접근을 허용하기 위해 Processor는 사용자 프로그램이
서비스 n을 요청할 때 실행할 수 있는 특별한 syscall n 명령어를 제공합니다.
syscall 명령을 실행하면 exception handler가 trap을 발생시켜 argument를 decoding하고
적절한 커널 루틴을 호출합니다.

예를 들어 open 함수를 실행하고 싶으면 Kenel로 요청합니다.
open도 일종의 I/O 이기 때문에 exception이 될것이고, 필요할 때만 사용하기 때문에 trap으로
처리가 가능합니다.
user calls : open(filename, options)
Calls __open function, 이것은 system call 명령어인 syscall을 통해 발생합니다.
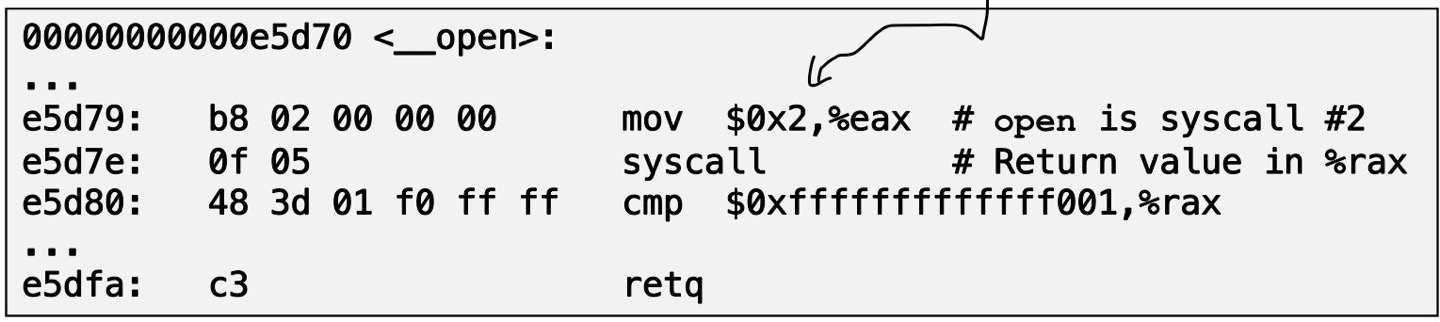
open 함수의 템플릿입니다. 
2) Fault
의도적이지 않지만 회복이 가능한 exception 입니다.
return 값으로는 fault가 발생한 지점으로 되돌아올 수 있고 또는 중간에 abort 될 수 도 있습니다.

예시로 Page Fault가 있습니다.
간략히 말하면 page는 가상메모리의 크기를 말하며, frame은 물리메모리의 크기를 말합니다.
여기서 보통 데이터를 저장할 때 물리적 메모리의 공간이 부족하면 가상 메모리를 사용하게 됩니다.
근데 여기서 물리 메모리와 가상 메모리의 크기 차이가 발생하여 가상메모리의 데이터가 물리 메모리에
부재하는 상황을 Page Fault 라고 합니다. page fault의 자세한 부분
int a[1000]; main(){ a[500] = 13; }
a라는 배열을 전역 배열로 선언하고 이중 지역 변수로 값을 넣는다고 가정해보자 (movl)
우리가 배열의 크기 1000으로 잡아놓은 공간이 메모리가 아니라 disk에 있으면 disk에 있는 배열을 메모리로 load하는
과정이 필요합니다. 이러한 과정 자체가 page fault입니다.
하지만 이러한 경우 disk로 부터 page를 만들어 다시 메모리 배열에 값을 넣어주는 작업을 수행합니다.
그래서 movl 작업은 총 2번 일어나게 됩니다.
따라서 page fault의 경우 return 값이 fault가 발생한 지점으로 되돌아옵니다.

반대로 return 값이 abort로 가는 경우가 있습니다. 이러한 경우 segmentation fault라고 합니다.
int a[1000]; main(){ a[5000] = 13; }
1000이 할당되어있는 상태에서 5000 번째 주소에 값을 넣으려 합니다.
위의 경우와 동일하게 page fault가 발생합니다. 마찬가지로 배열에 해당하는 page를 할당해보니
주소가 맞지 않습니다. 이때 exception hadler는 SIGSEGV signal을 user process에 보냅니다.

3) Abort
의도적이지 않으면서 회복할 수 도 없는 exception 입니다.

Process
프로그램은 instruction과 data들의 집합입니다. 우리는 프로그램을 실행시켜주기 위해 해당 프로그램내의
instruction들을 메모리에 load를 시켜주어야 합니다. 이때 CPU에서 메모리까지 Interface를 제공하는 것이
process 입니다. 따라서 process가 존재해야 프로그램이 작동합니다.
Process = {code, data(전역변수), heap(malloc), stack(지역변수)} 로 구성됩니다.
process는 실행하는 동안 프로그램의 state 혹은 system state를 바꿀 수 있기 때문에 자체적으로
control flow를 가질 뿐만 아니라 자신만의 memory공간을 가집니다.
이러한 process는 프로그램에게 2가지 abstraction을 제공합니다.
1) Logical control flow (CPU 관점)
각각의 프로그램들은 마치 CPU를 독점으로 사용하는 것 처럼 보입니다.
이는 Context switchng을 통해 OS Kernel 메카니즘에 의해 제공 됩니다.
2) Private address space (메모리 관점)
각각의 프로그램들은 마치 메인 메모리를 독점으로 사용하는 것 처럼 보입니다.
이는 가상 메모리를 통해 OS Kernel 메카니즘에 의해 제공 됩니다.
Multiprocessing

cmd 창에서 몇개의 process가 현재 진행중인지 확인했습니다. 총 123개의 process가 진행중입니다.
cpu는 1개인데 어떻게 많은 process들을 수행하는 것일까?
결론부터 말하면 OS는 하나의 CPU로 여러개의 process를 구동하기 위해 time sharing 방식을 사용합니다.
어떤 process를 먼저 혹은 길게 사용할 것인지는 CPU 스케줄링기법에 따라 달라집니다.
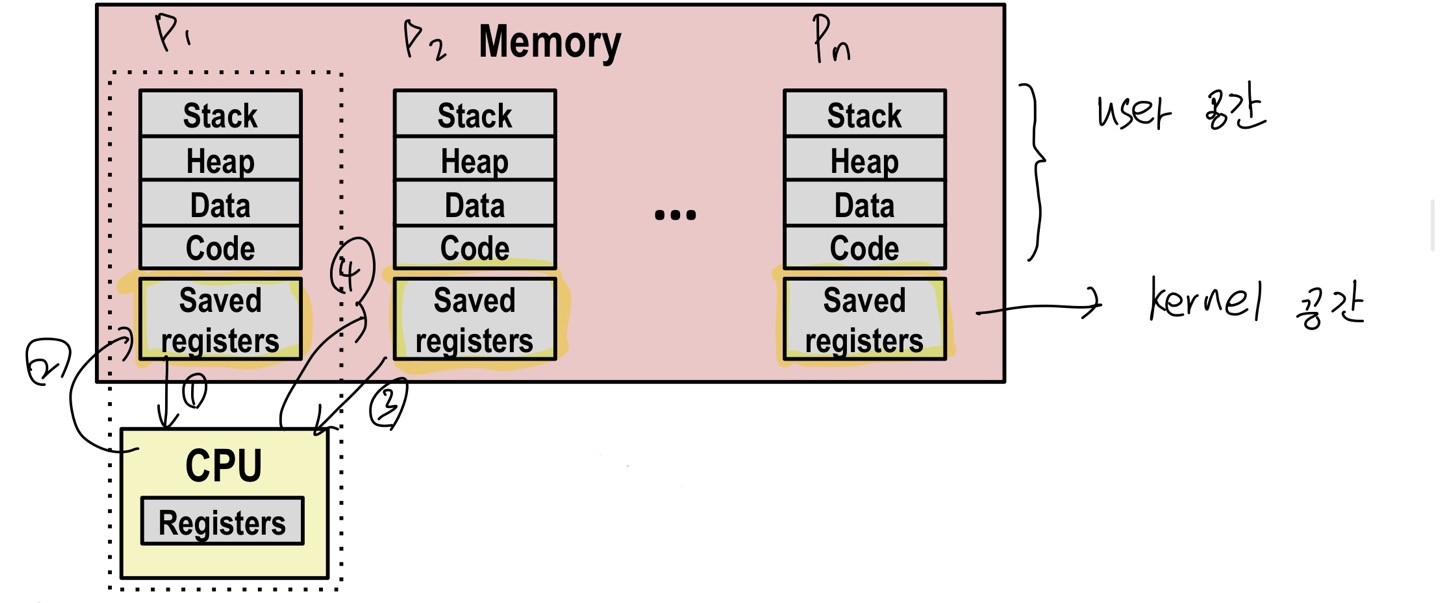
1. 가장 먼저 우선순위에 있는 procsee 1 을 CPU가 먼저 처리합니다.
2. 스케줄링에 의해 할당된 시간이 다 지나면 지금까지 처리한 부분까지 OS Kernel 공간에 saved register을
load 하고 주소 공간을 switch합니다 (context switch)
3. 다음 process 2 로 접근해 똑같이 처리합니다.
4. process 2 의 할당된 시간이 지나면 똑같이 2번처럼 처리합니다.
1, 2, 3, 4 반복
최근에는 Multicore라고 cpu가 1개가 아니라 여러개인 하드웨어가 나와서 더욱 효율적으로 처리하는 방법이
생겼습니다.
Concurrent Process
두개 이상의 process 들이 동시에 실행되는 경우입니다.

sequential

concurrent process는 물리적 시간이 지남에 따라 분리 됩니다.
그러나 우리는 concurrent process가 서로 동시에 실행되는것으로 생각할 수 있습니다.
이에 대한 답은 바로 Context Switching 입니다.
Context Switching
process들을 Kernel에 의해 관리되어집니다.
Kernel은 별도의 다른 process가 아니라 현재 진행되고 있는 기존 process의 일부로서 작동합니다.
process A 에서 process B로 넘어갈때 context switch를 통해 이동합니다.


예를들어 set time부터 process A가 실행되면 10ms 동안 작동하고 10ms가 끝나면 timer interrupt가 발동합니다.
exception이기 때문에 interrupt handler (Kernel)이 실행되고 스케줄에 의해 context switch가 실행됩니다.
이러한 과정 사이를 context switch overhead라고 합니다.
Process Control
모든 컴퓨터는 처음 시작하면 init이라는 process 로부터 tree형태로 각각의 process가 발생합니다.
예를들어 처음 컴퓨터를 키고 shell 프로그램을 실행시키고 명령어 ls를 입력하면
shell은 ls의 parent process가 되고 ls는 shell의 child process가 됩니다.

프로그래머의 입장에서 우리는 process를 3가지 형태로 생각할 수 있습니다.
Running : process가 현재 실행되거나, 실행되기위해 기다리는 상태입니다.
Stopped : process 실행이 중지되거나 signal이 올때까지 schedule 되지않은 상태입니다.
Terminated : process가 영구적으로 멈춘 상태입니다.
process가 종료되는것은 총 3가지 이유가 있습니다.
1) 종료시키는 signal을 받음
2) main 함수에서 return됨
3) exit 함수를 호출
exit함수는 한번만 호출되지만 절대 return하지 않습니다.
Creating Process
parent process는 fork라는 함수를 호출함으로써 child process를 만들 수 있습니다.
int fork(void)
child process에 0을 return하고 parent process에 child의 PID를 return합니다.
child는 parent와 동일한 코드를 가지게 되고 stack도 동일합니다. 따라서 child는 parent의 가상주소 space를
복사합니다. 물론 위치는 분리되있습니다. 또한 child는 parent의 file descriptor들도 복사합니다.
다른점은 child와 parent는 다른 PID를 갖는다는것입니다.
즉, fork함수는 한번 호출하지만 return값은 2개입니다.

fork 예시입니다.
parent가 먼저 출력될지 child가 먼저 출력될지
알지 못합니다.
실행할 때 마다 다를 수 있습니다.


출력 화면입니다.
마찬가지로 parent와 child의 순서는 실행할때마다 다릅니다.
Modeling fork with Process Graphs
위의 fork함수의 실행과정을 보기좋게 그래프 형식으로 나타낸것입니다.
parent와 child가 동시에 일어나기 때문에 그래프를 보는것은 유용한 도구입니다.

fork함수의 Process Graph입니다.

위의 그래프를 labeled형식으로 한 그래프입니다.

fork Example : Two consecutive forks


fork Example : Nested forks in parent

fork Example : Nested forks in children

Reaping Child Process
process가 종료될 때 user 메모리안에서는 종료되었지만 아직 process가 OS kernel에 남아
system resource들을 소비하고 있을 수 있습니다. 이러한 process를 zombie 라고 부릅니다.
따라서 우리는 메모리 효율과 컴퓨터 성능을 위해 이러한 zombie를 제거해주어야 합니다.
이를 Reaping이라고 부릅니다.

process A가 fork를 통해 Process B를 create한후 B가 종료 되면 user 메모리 상에서는 종료됩니다.
하지만 OS kernel 부분에서는 아직 B의 OS 정보나 각종 code들이 살아 있습니다.
먼저 parent인 process A가 wait 또는 waitpid를 통해 syscall을 걸고 OS kernel에 process B가 종료됐다고
signal을 보냅니다. 그럼 OS kernel이 child process인 process B를 삭제합니다.
만약 Reaping을 안한다면 어떻게 될까?

위와 같은 코드는 child 는 exit으로 종료되었지만 parent는 while(1) 무한루프를 돌고 있습니다.
따라서 좀비로 남아있습니다.

./forks 7 & 로 background로 실행해서 바로 return 값을 보니
parent의 PID = 6639, child의 PID = 6640 입니다.
ps 명령어를 통해 현재 사용하고 있는 process들을 보니 아직 6640과 6639가 돌고 있습니다.
아까 parent의 무한루프때문입니다. 따라서 kill 6639를 통해 parent를 죽이니 child도 같이 죽였습니다.

이번에는 child가 while(1)을 통해 무한루프를 돌고 있습니다.

ps를 통해 확인해보니 parent는 완전히 종료되고 아직 child가 죽지않았습니다.
따라서 kill 6676을 통해 완전히 제거해줍니다.
parent는 wait 함수를 통해 child를 제거합니다.
int wait ( int *child_status )
child가 종료될때 까지 현재 process를 중지하는 것입니다.
종료된 child process의 PID가 return됩니다.
child_status가 NULL이 아니면 child의 종료된 이유와 종료 상태를 나타내는 값으로 설정할 수 있습니다.
이는 wait.h 에 메크로로 저장되있습니다.

정상적인 reaping의 과정입니다. 먼저 parent가 fork를 통해 child를 만들고 child가 종료되면 parent에게 signal을
보냅니다. 그러면 parent는 wait 함수를 실행하고 OS kernel한테 reaping 요청을하고 OS kernel이 child를 reaping
합니다.
EX)

EX)

N = 10이라 할때 parent가 10개의 child를 생성하고 10번 wait해서 reaping 해주는 작업입니다.
waitpid 함수는 wait함수와 비슷하지만 어떤 특정한 process를 reaping하기 위해 사용합니다.
pid_t waitpid (pid_t pid, int &status, int options) 첫번째 인자인 pid에 해당하는 child process를 reaping 합니다.

마찬가지로 parent가 10개의 child process를 만듭니다. 우리가 앞에서 배운것처럼 fork 함수를 사용할 때
parent와 child중 누가 먼저 실행할지 알 수 없기 때문에 pid 배열에 pid[0] 부터
임의의 child process pid가 들어갑니다.
그 다음 pid[9]부터 pid[0] 까지 waitpid 함수를 실행합니다.
pid[9]은 9번째로 생성된 child process pid가 들어갑니다.
execve
int execve ( char *filename, char *argv[], char *envp[] )
현재 실행가능한 파일인 filename의 실행코드를 현재 process에 load하여 기존의 실행코드와 교체하여
새로운 기능으로 실행합니다. 즉, 현재 실행되는 프로그램의 기능은 없어지고 filename 프로그램을 메모리에
load하여 처음부터 실행합니다.
filename
교체할 실행파일 / 명령어
이런 형태로 인자를 받습니다
#include <stdio.h> #include <unistd.h> int main(int argc, char *argv[]){ char *path = "/bin/ls"; //filename char *argv[] = {"/bin/ls", "-al", NULL}; char *envp[] = {NULL}; //setting execve(path, argv, envp); printf("hello"); }위의 코드를 보면 printf를 실행하지 않습니다. path의 프로그램을 메모리에 load하고 처음부터 실행하기 때문입니다.
filename은 실행가능한 binary이거나 shell이어야 합니다. 그리고 path가 설정되있는 directory라고 하더라도
절대경로나 상대 경로로 정확한 위치를 지정해야합니다.

shell process가 fork를 통해
child process를 만들고 거기에다가
execve(ls -al)을 통해 shell 프로그램이
실행됩니다.
기존프로그램의 code, data, stack를 무시하고 덮어씁니다. 반면에 PID, open file, signal context는 유지합니다.
execve는 1번 호출되고 절대 return하지 않습니다.
EX)
"/bin/ls -lt /usr/include" 가 child process에서 실행한다고 가정해보자
execve("/bin/ls", myargv, environ);

'시스템 프로그래밍' 카테고리의 다른 글
Concurrent Programming (0) 2022.04.16 Network Programming : Part 2 (0) 2022.04.14 Network Programming : Part 1 (0) 2022.04.12 System-Level I/O (0) 2022.04.05 Exceptional Control Flow : Signals and Nonlocal Jumps (0) 2022.03.29