-
Thread-Level Parallelism시스템 프로그래밍 2022. 5. 26. 14:58728x90
지금까지 우리는 I/O delay를 줄이기 위해 thread를 사용해 왔습니다.
대부분의 하드웨어는 multicore로 되어있습니다. 그리고 여러개의 process로 구성됩니다.
또한 Hyperthreading이 가능한 CPU가 존재합니다. 즉, CPU가 여러개의 core를 가진것 처럼 보입니다.
예를 들면 core가 4개면 thread가 8개인것 처럼 작동하게 됩니다.
하지만 thread들 끼리 공유하는 data가 있다보니 완전히 병렬적으로 실행하기 어려운 부분이 있습니다.

위의 그림과 같이 단일 칩 안에 여러개의 core가 존재합니다.
L1, L2 캐시는 private한 공간으로 해당 core안에서 공유되고
L3 캐시는 shared한 공간으로 여러 core가 접근가능합니다.
register에 가까울 수록 메모리 data에 대한 접근 속도가 빠릅니다.
EX) Parallel Summation
0부터 n-1 까지 더하는 프로그램을 만든다고 가정해봅시다.
1부터 n-1까지 partition을 만들어 각 partition을 해당 thread가 각각 계산해 마지막에 모두 더해줄 수 있습니다.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10
1) 첫번째 시도
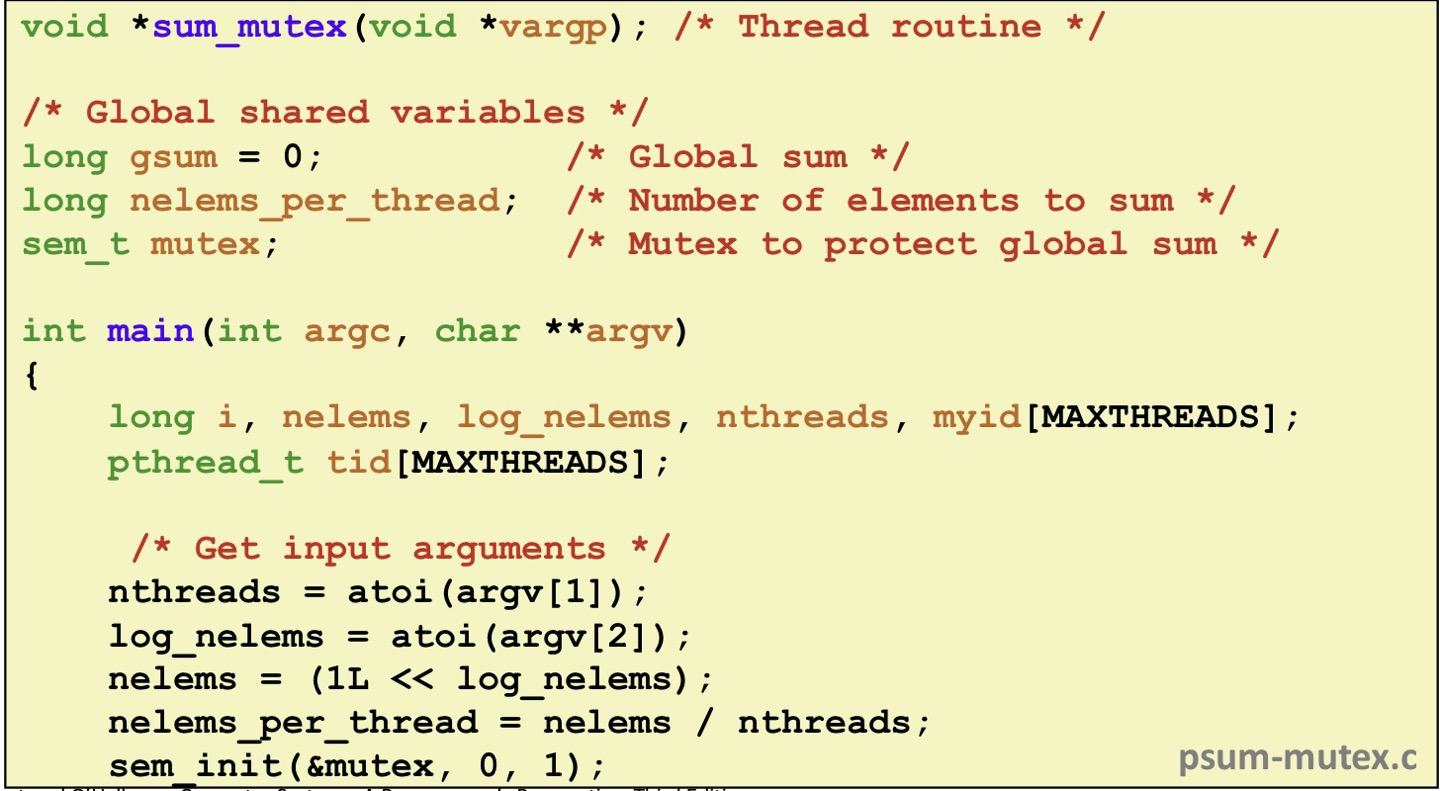
전역변수 gsum에 다가 모든 partition의 합을 더해줘 최종 답이 됩니다.
nelem_per_thread = nelems / nthreads;
nthread는 thread의 갯수
nelems는 전체적으로 더할 숫자의 갯수입니다.(0 ~ n-1)
따라서 nelem_per_thread는 한 thread당 더할 숫자의 갯수 입니다.

thread를 nthread 만큼 만들고 sum_mutex라는 thread가 실행하는 함수와 ID를 넘겨줍니다.
마지막에 gsum을 출력해줍니다.

gsum을 주기적으로 update해줍니다.
따라서 모든 theread가 각자 실행해야 하는 범위가 지정됩니다.
mutex로 선언해 한꺼번에 동시에 접근하지 않도록 만듭니다.

mutex는 사실 비용이 많이드는 함수입니다.
위의 표를 보면 thread들이 많아질 수 록 오히려 더 느려지는 것을 확인할 수 있습니다.
thread가 1개 였어도 느리지만 thread가 많아질 수 록 너무 느려집니다.
2) 두번째 시도
mutex lock를 사용하게 되면 많은 비용이 들고 속도가 느려집니다.
따라서 각 thread들이 계산한 결과를 각각 배열의 index에 저장하면 다른 thread들이 접근하지 못하고 계산을
할 수 있습니다.


이전것과 달리 thread들이 늘어나면서 속도가 많이 좋아졌습니다.
3) 세번째 시도
레지스터를 사용하는 것입니다. 즉, 전역변수가 아닌 지역변수(local)을 사용해 메모리로 접근하는 시간을
줄이는 것입니다.

전역변수인 psum배열에 매번 접근하는 것이 아니라
지역변수인 sum에다가 계속 접근해 합을 구하고 마지막에 1번만 psum배열에 sum을 넣어주면 됩니다.

배열을 사용했던 것보다 훨씬 시간이 줄어들어 빨라졌습니다.
Characterizing Parallel Program Preformance
p개의 core가 k개의 core를 사용해 running time을 측정하면 Tk가 됩니다. (p >= k)
speedup(속도) : Sp = T1 / Tp
Efficiency(효율성) = Ep = Sp / p = T1 / (pTp)
예를들어 T1 = 1이고 T4 = 0.25라면
S4 = 1 / 0.25 = 4
E4 = 4 / 4 = 1 (100%)
efficiency가 1이라면 효율성이 최대라는 것입니다.
즉 thread 1개가 속도가 1이라면 thread 2개는 속도가 0.5가 됩니다.
효율성이 1 (100%)보다 작으면 손실이 있는 것입니다.
Performance of psum-local
위에서 봤던 psum-local의 성능을 보겠습니다.

S1 즉, CPU가 1개 일때 효율성은 100이므로 손실이 없습니다.
S2는 CPU 2개를 돌렸을 때 입니다. 효율성은 87로 떨어졌습니다.
위의 표를 보면 CPU가 많아질 수록 효율이 떨어지는것을 확인할 수 있습니다.
Memory Consistency

메인 메모리에는 변수 a, b가 존재합니다.
thread1은 a를 2로 바꾸고 b를 출력합니다.
thread2는 b를 200으로 바꾸고 a를 출력합니다.
따라서 program execution order는 각 thread마다 W를 하고 R을 해야합니다.
하지만 thread간의 interleaving할 수 있기 때문에 실행되는 순서에 따라 결과가 달라질 수 있습니다.

위와 같이 순서의 경우의 수가 존재합니다.
출력순서가 (1, 100) 또는 (100, 1)은 불가능합니다.
Non-Coherent Cache Scenario

캐시가 들어가게 되면 main memory에 있는 값을 thread에 있는 캐시에 복사해와서 값을 맘대로
바꿀 수 있습니다.
그렇게 되면 캐시에 있는 값과 main memory의 값이 다른 경우가 생길 수 있습니다.
이 상태에서 thread 1이 b를 출력하면 100을 출력하게 되어서 thread 2의 b = 200값을 출력하지 못하게 됩니다.
즉, 캐시가 private 하기 때문에 서로 변경된 값을 알지 못하게 됩니다.

Snoopy Caches
이를 개선하기 위해 snopopy chach를 사용합니다.
각각의 Core에서 돌아가고 있는 메모리에 tag를 붙이는 것입니다.
Invalid : 사용할 수 없는 값
Shared : readable copy
Exclusive : writeable copy

변경된 data에 tag를 붙인 모습입니다. 따라서 변경됐다는 것을 알 수 있습니다.

thread 2번이 1번을 접근하는 경우 thread 2번이 다른 core의 값을 읽을 때 E -> S로 바꾸어서 읽게 됩니다.
그렇게 되면 서로 어떤 tag를 가지고 있는지 확인하는 방법이 하드웨어적으로 구현되어 있습니다.
'시스템 프로그래밍' 카테고리의 다른 글
Dynamic Memory Allocation : Advanced Concepts (0) 2022.06.19 Dynamic Memory Allocation : Basic Concepts (0) 2022.05.31 Synchronization : Advanced (0) 2022.05.13 Synchronization : Basics (0) 2022.04.20 Concurrent Programming (0) 2022.04.16