-
728x90
위 게시물은 Computer Organization and Design -The hardware / software interface"
by Patterson and Hennessy, 5th edition, 2013 을 참고하여 작성했습니다.
Understanding Program Performance
프로그램의 성능을 이해하는데 있어서 크게 4가지 요건이 있습니다.
1) 알고리즘 : 연산 횟수를 결정합니다.
2) 프로그래밍 언어, 컴파일러, 구조 : 작업당 실행할 기계 명령 수를 결정합니다
3) Processor 그리고 메모리 시스템 : 얼마나 빠르게 명령을 처리할지 결정합니다.
4) I/O 시스템 : 얼마나 빠르게 I/O 작업을 할 수 있는지 결정합니다.
Below Your Program
우리가 사용하는 응용프로그램들은 수백만 줄의 코드로 작성되며 복잡하고 정교한 소프트웨어 라이브러리에 의존할 수 있습니다.
하지만 컴퓨터 하드웨어는 매우 간단하고 low-level의 명령만 실행할 수 있습니다.
따라서 복잡한 응용프로그램에서 간단한 명령어로 전환하기 위해서 high-level operation을 간단한 컴퓨터 명령어로
해석하거나 변환하는 여러 계층의 소프트웨어가 수반되는데, 이는 훌륭한 abstraction의 예시 입니다.

위 그림은 이러한 소프트웨어 계층이 주로 계층적 방식으로 구성되어 있음을 보여줍니다.
Appilcation software : 일반적으로 High-level로 작성된 프로그램을 의미합니다. 우리가 흔히 바탕화면에 깔린
프로그램이라고 생각하면 됩니다.
Systems software : 많은 종류가 있지만, 운영 체제와 컴파일러 두 종류의 시스템 소프트웨어가오늘날 모든 컴퓨터 시스템의 중심입니다.
운영 체제는 사용자의 프로그램과 하드웨어 사이를 연결하고 다양한 서비스와 감독 기능을 제공합니다.
기본 입력 및 출력작업을 처리
저장공간과 메모리 관리
동시에 사용하는 여러 application 간의 컴퓨터 보호 공유 제공 (Schedullong task & sharing resoucers)
오늘날 예를들면 리눅스, 윈도우, ios 등등 이 있습니다.
컴파일러는 C, C++ JAVA 같은 high-level로 작성된 프로그램은 machine code로 변환합니다.
Hardware : CPU(Processor), 메모리, I/O controllers 등 이 있습니다.
From a High-Level Language to the Language of Hardware
우리의 컴퓨터는 전자제품이기 때문에 전원을 키고 끌 수 있습니다.
따라서 컴퓨터가 가장이해하기 쉬운 신호는 켜짐과 꺼짐이고 우리는 이를 2진법으로 생각하기로 했습니다.
컴퓨터는 instruction(명령어)라고 불리는 우리들의 노예입니다.
결국 컴퓨터가 이해하고 따르는 bit의 집합인 명령은 숫자로 생각할 수 있습니다.
예를 들어, 비트 1000110010100000은 한 컴퓨터에 두 숫자를 더하라고 지시합니다.
하지만 이러한 이진법으로 명령을 내리는건 불편함을 느껴 어떠한 symbolic 표기법에서 이진법으로 표기하는 프로그램을 만들었는데 이것이 assembler 입니다.
ex) add A, B -> 1000110010100000
(add A, B) = A와 B를 더하라는 어셈블리 언어 입니다.
1000110010100000 = machine language 입니다.
하지만 이러한 어셈블리 언어도 불편함을 느껴 오늘날 high-level 프로그래밍 언어가 나오게 됩니다.
High-level 언어는 인간이 읽고 작성할 수 있으며 어떤 CPU나 운영체제에서 동일하게 사용 가능합니다.
이러한 HHL은 몇가지 이점을 지닙니다.
1) 영어 단어와 숫자 대수 표기법 등을 사용하면서 자연스러운 언어로 생각하여 의도된 용도에 따라 프로그램을
설계할 수 있습니다.
2) 프로그래머의 생산성이 향상됩니다.
3) 프로그래밍 언어가 프로그램들이 개발되었던 컴퓨터로부터 독립할 수 있습니다.
이러한 장점들 때문에 오늘날 어셈블리 언어로 프로그래밍이 거의 이루어 지지 않습니다.

위 그림은 프로그램과 언어들 사이이 관계를 보여줍니다. 이것은 abstraction(간단하게 만들기)의 힘의 예시입니다.
Underlyng Hardware
컴퓨터의 기본 하드웨어는 데이터 입력, 데이터 출력, 데이터 처리, 데이터 저장 과 같은 기본 기능을 수행합니다.
컴퓨터의 두 가지 핵심 구성 요소는 입력 장치와 출력 장치 입니다.

The organization of a computer, showing the five classic components 컴퓨터의 5가지 classic 구성요소는 input, output, memory, data path(데이터 경로) 그리고 control(제어) 입니다.
data path와 control은 때때로 Processor라고 불립니다.
위 구성요소는 어떠한 컴퓨터(데스크 탑, 서버, 임베디드 등) 동일하게 적용됩니다.
디자인이나 설계를 개선하기 위한 가장 좋은 방법은 Abstraction(추상화)(간단하게 만들기) 입니다.
Abstraction은 낮고 세세한 부분을 숨겨 줍니다. 즉, 구체성은 배제하고 일반적인 사항을 다룹니다.
예를들어 우리는 자동차를 운전할 때 자동차의 엔진 구조와 작동원리를 알 필요가 없습니다.
또는 우리가 웹개발을 할때 홈페이지에 음악이 흘러나오게 하려면 Html 테그를 사용하면 됩니다.
굳이 하드웨어 세부적인 구조와 음악 응용 장치를 알 필요는 없습니다.
가장 중요한 abstraction중 하나는 하드웨어와 최하위 소프트웨어 사이의 Interface 입니다.
즉 최하위 소프트웨어와 하드웨어의 연결다리라고 생각하면 됩니다.
이러한 중요성 때문에 interface는 ISA(Instruction Set Architecture 명령어 집합 아키텍쳐) 라고 불립니다.
ISA는 명령어, 입출력 장치, 이진 machine language 등 을 올바르게 작동 시키기 위해 프로그래머가 알아야 할 모든것을
포함합니다.
일반적으로 운영체제는 입출력, 메모리 할당, 기타 낮은 수준의 시스템 기능의 세부 사항의 기능을 모두 포함하므로
프로그래머들은 이러한 세부 사항에 대해 걱정할 필요가 없습니다.
ABI(Applicatinn Binary Interface)는 ISA + OS interface의 조합니다.
ISA는 컴퓨터 설계자들이 수행하는 하드웨어와는 독립적으로 이야기 할 수 있게 합니다.
하드웨어와 소프트웨어 모두 abstraction를 사용하는 계층으로 구성되며 각각의 하위 계층은
위의 수준으로부터 세부 사항을 숨깁니다.
추상화 수준 간의 핵심 인터페이스 중 하나는 하드웨어와 low 레벨 소프트웨어 간의 인터페이스인 ISA입니다.
ISA를 통해 다양한 비용과 성능의 하드웨어 들이 동일한 소프트웨어를 실행할 수 있게 합니다.A Safe Place for Data
Volatile main memory(휘발성 메모리) : 전원이 꺼지면 명령어들과 데이터가 날라갑니다. (DRAM)
Non-volatile secondary memory : 전원이 꺼져도 명령어들과 데이터가 남아 있습니다. (hard disk, flash memory, dvd)
Communicating with Other Computers (Network)
네트워크의 장점
1) Communication : 정보가 빠른 속도로 컴퓨터 끼리 교환된다.
2) Resource sharing : I/O 장치를 여러 컴퓨터가 공유할 수 있습니다.
3) Nonlocal access : 먼 거리의 컴퓨터를 연결함으로써 가까이서 컴퓨터를 이용하지 않아도 됩니다.
Local area network (LAN) : Ethernet (같은 건물 내에서 통신)
Wide area network (WAN) : Internet
Wireless network : WIFI, 블루투스
Performance
컴퓨터의 성능이 좋다? 무슨말일까?
속도가 빠른것? 메모리의 용량이 큰것?

위의 그림은 비행기 모델마다 스펙을 보여줍니다.
어떤 모델이 승객을 많이 태우는지? 어떤 모델이 더 멀리 날아가는지? 어떤 모델이 더 빠른지?
마찬가지로 컴퓨터 또한 성능에 관해 다양한 관점에서 정의가 가능합니다.
컴퓨터의 성능은 크게 Response time과 Throughput으로 나눌 수 있습니다.
Response time(Excution time) : 하나의 작업에 소요되는 시간
(ex : 휴대폰 기기)
Throughput(Bandwidth) : 주어진 시간에 한 일의 총량
(한번에 처리할 수 있는 작업의 양이 많고 처리속도가 빠르면 상승, ex : 서버)
이에 대해 우리는 2가지 질문에 해답을 구할 수 있습니다.
1) Processor를 더 빠른 version으로 교체하면 어떻게 될까?
=> response time과 throughput 모두 상승합니다.
2) Processor를 추가해주면 어떻게 될까?
=> response time은 그대로고 throughput은 증가하게 됩니다.
그러나 결국에는 하나의 일에 대해 processor가 각각 나눠서 분담을 하게 되면 실제로는
response time 또한 줄어들게 됩니다.
즉, 1, 2번 질문의 경우 모두 성능을 향상합니다.
Response time(Excution time)이 짧을 수록 작업이 빨리 끝나므로 성능이 우수하다고 할 수 있습니다.
만약 X와 Y의 성능을 Response time으로 비교해본다고 하면 다음과 같습니다.

X의 성능은 다음과 같이 표시할 수 있습니다.
만약 X가 Y보다 n만큼 성능이 좋다면

다음과 같은 식이 성립합니다.
이제 우리는 얼마나 X가 Y보다 좋은지 알고 싶습니다.
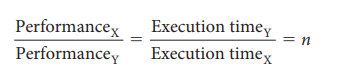
X가 Y보다 n만큼 좋다는 의미입니다.
예를 들어 컴퓨터 A는 프로그램을 실행하는데 10초가 걸리고 B는 15초가 걸린다고 가정하면
A는 B보다 얼마나 빠를까?

A가 B보다 1.5배 더 빠릅니다.
Measuring Excution Time
Elapsed Time :
시작부터 종료까지 총 소요 시간입니다. 시스템의 성능을 정의하지만 다른 요소들도
고려한 값이므로 성능을 측정하기에는 다소 무리가 있습니다.
CPU Time :
오로지 CPU에서 작업을 수행하는 시간입니다. 컴퓨터의 다른 외부 요소를 고려하지 않습니다.
user CPU time(프로그램 내에서 CPU 작동시간) 과 system CPU time(OS 내에서 작동시간)으로 구성되어 있습니다.

CPU는 clock( =cycle, period)이란 것이 존재해 이를 통해 모든 작업을 수행합니다.
Clock frequency(=Clock rate)
cycles per second를 의미합니다.
예를 들어 4.0 GHz = 4000 MHz = 4.0 * 10^9 Hz 이므로 4*10^9 cycle/sec 를 갖습니다.
Clock period
Clock rate의 inverse 개념입니다. 한 cycle의 주기를 의미합니다.
예를 들어 Clock rate = 4.0 GHz 라면 Clock period = 1 / 4.0 = 250ps 가 됩니다.
CPU Time
CPU Time(실행시간)을 줄일 수록 더 좋은 성능을 갖게 됩니다.

위의 식을 아래식으로 표현할 수 있습니다.
cpu 시간을 줄이는데에는 clock cycle를 줄이거나 clock rate를 늘리는 방법이 있는데
두개 중 한개를 줄이거나 늘리면 trade-off(모순관계) 에 직면합니다.
예시문제
A = 2GHz clock rate, 10s CPU Time을 가집니다.
B는 6s CPU Time을 가지길 원하고 clock rate를 증가시키면 1.2배의 clock cycle을 갖게 됩니다.
B의 CPU Time이 6s 가 되려면 B의 clock rate는 얼마가 되어야 합니까?
먼저 B의 Clock rate를 구해야 하므로 식을 살펴보면

다음과 같은 식이 완성됩니다.
따라서 A의 clock cycle만 구하면 식이 완성되므로

이것을 다시 첫번째 식에다가 대입하면

즉 B의 CPU Time이 6s 가 되려면 clock rate는 4GHz가 되어야합니다.
Instruction Count and CPI
위의 공식은 프로그램에 필요한 instruction의 개수에 대한 어떠한 언급도 하지 않습니다.
execution time은 프로그램의 instruction의 개수에 따라 달라져야 합니다.
Instruction Count
명령어의 개수를 의미합니다. 프로그램, ISA, 컴파일러에 의해 달라질 수 있습니다.
CPI(Clock cycle Per Instruction)
각 명령어가 실행하는 데 걸리는 clock cycle의 평균 개수입니다. 각기 다른 명령어들은 그들이 하는
일에 따라 다른 시간이 걸릴 수 있기 때문에 CPI는 프로그램에서 실행되는 모든 명령어들의 평균입니다.
cpu 하드웨어에 따라 달라지고 다른 명령어들이 다른 CPI를 가진다면 평균 CPI는 instruction mix에 영향을 받습니다.
공식을 통해 Clock cycle을 구할 수 있습니다.

위의 식중 CPU 실행시간을 구하는 공식에 대입하면

이를 다르게 표현하면

다음과 같은식이 됩니다.
A 컴퓨터의 cycle time = 250ps 이고 CPI = 2.0 이고
B 컴퓨터의 cycle time = 500ps 이고 CPI = 1.2 일 때
ISA와 프로그램이 같다고 가정하면 A와 B중 어느것이 더 빠르고 얼마나 더 빠르까?
먼저 A의 CPU Time = Instruction count * 2.0 * 250ps 로 나타낼 수 있습니다.
마찬가지로 B의 CPU Time = Instruction count * 1.2 * 500ps로 나타낼 수 있습니다.
A = Instruction * 500ps
B = Instruction * 600ps 이므로
A가 B 보다 1.2배 더 빠릅니다.
만약 다른 명령어 Class 들이 각각 다른 cycle을 가질때는 어떻게 할까?

이를 이용해 평균 CPI를 구할 수 있습니다.

예를 들어 똑같은 컴퓨터에서 똑같은 High-level 언어로 컴파일한 A, B, C 각각의 명령어 Class를
각각 다른 연산이라고 하면

위와 같은 표가 완성됩니다.

sequence1, 2 중에서 어떤 연산이 가장 많이 수행되며 가장 빠를까?
먼저 sequence 1 = 총 (2 + 1 + 2) 5번의 instruction 연산을 수행합니다.
sequence 2 = 총 (4 + 1 + 1) 6 번의 instruction 연산을 수행합니다.
연산 자체로 보면 sequence 2 가 더 많이 수행합니다.
이제 평균 CPI를 구해 누가 더 빠른지 구해보겠습니다.
sequence 1의 clock cycle = (2 * 1) + (1 * 2) + (2 * 3) = 2 + 2 + 6 = 10 cycle
sequence 1의 CPI = 10 / 5 = 2.0
sequence 2의 clock cycle = (4 * 1) + (1 * 2) + (1 * 3) - 4 + 2 + 3 = 9 cycle
sequence 2의 CPI = 9 / 6 = 1.5
따라서 연산의 개수는 seqence 2 가 많았지만 실제 속도는 sequence 1 보다 빠릅니다.
결국 모든것을 종합해보면 CPU Time으로 성능을 평가했습니다.

이는 CPU Time = Instruction count * CPI * Clock period 로 나타낼 수 있습니다.
Performace는 아래표를 보면 영향을 받는 요인들을 적어놨습니다.

The Power Wall
Power Trends

clock rate와 power의 관계를 나타낸 그래프입니다.
2001년을 보면 clock rate는 한계점이 드러나고 그때 power 역시 가장 높았습니다.
2001년 이후 power 하락에 더 중점을 두게 되었습니다.
그러나 clock rate를 유지하되 power를 줄이는 것은 한계가 있습니다.
그럼 performace를 높이기 위해서는 어떻게 해야할까?
Multiprocessor
이러한 문제점을 해결하기 위해 멀티 프로세서(듀얼 코어, 쿼드 코어 등)가 등장하였습니다.
멀티코어는 Parallel(병렬) 프로그래밍을 요구합니다. (cpu당 1개의 프로그램 처리)
병렬 프로그래밍은 3가지 단점이 존재합니다.
1) 성능을 위한 프로그래밍을 하기 어렵습니다.
2) Load balancing 하기 어렵습니다.
3) communication과 synchronization(동기화)의 최적화가 어렵습니다.
예를 들어 하나의 신문을 작성하기 위해 8명의 기자(CPU)가 함께 일하면 빠르게 끝날것 같지만 8명이서
분산작업(subtask)를 나누는 것(load balance)도 힘들고 8명중 1명이 뒤쳐지면 나머지 7명은 혜택을
그만큼 못받습니다. 또한 8명의 기자들은 대화를 많이 해야하므로 고려해야할 부분들이 많아집니다.
SPEC CPU Benchmark
cpu제조사들의 성능 비교를 객관적 이고 공정한 지표를 통해 측정
cpu의 성능을 측정할 땐 I/O를 무시하고 오직 CPU의 성능만 체크합니다.
SPEC Power Benchmark
전력 소모를 측정
Fallacies and Pitfalls
Pitfall : Amdhl's Law
말 그대로 pitfall(함정) 입니다. 컴퓨터의 일부 부품의 성능을 향상시키면 전체 성능이 같은 비율로
올라갈것이라는 착각 입니다.
실제로는 성능이 올라간 부품에 대한 시간과 성능이 그대로인 부품의 시간을 분리해서 생각해 주어야 합니다.

예를 들어 전체 실행시간이 100ms 에서 곱셈연산을 하는데 80ms가 들었습니다. 이때 곱셈연산을 하는 부품을
5배 성능을 향상시켰으면 전체적으로 성능이 올라갈까요?
일단 위의 공식을 그대로 이용하면
이론적으로 전체 성능이 올라갈 시 100ms 에서 5배가 빨라졌으므로 전체성능은 20ms가 되어야합니다.
따라서 20ms = 80 / 5 + 영향받지 않은부분(100 - 80)
=> 20ms = 16 + 20 (식이 성립하지 않습니다)
따라서 일부부품의 성능을 개선하였다 하더라도 전체 성능은 올라가지 않습니다.
Pitfall : MIPS as a Performance Metric
MIPS란 Millions of Instruction Per Second의 약자입니다.
우리는 보통 cpu가 초당 명령을 수행하는 속도의 단위를 IPS라고 합니다.(Instruction Per Second)
만약 이러한 단위가 1초에 1000개를 수행하면 kIPS이고 1백만개를 수행하면 MIPS입니다.
MIPS는 컴퓨터 간의 ISA(명령 집합 구조) 차이나 명령어 간의 복잡도 차이를 고려하지 않습니다.
즉, 앞에서 본 SPEC의 Benchmark를 사용하는게 더 정확할 수 있습니다.
Concluding Remarks
1) 기술의 발전으로 Performance/Cost는 증가하고 있다.
2) abstraction의 계층적인 층 구조 (하드웨어, 소프트웨어 모두)
3) ISA(명령 집합 구조) =>하드웨어/소프트웨어 사이의 데이터/명령 교환(Interface)
4) Execution time : 성능 측정에 최고의 도구
5) Power(전력 소모)를 줄이는 데 한계가 있으며, 성능향상에 제한을 준다
따라서 성능향상을 위해 parallelism(병렬)을 사용해야한다.
'컴퓨터 아키텍쳐' 카테고리의 다른 글
Chapter 5 : Memory Hierarchy (0) 2022.06.15 Chapter 4 : Processor (0) 2022.06.10 Logic Design (0) 2022.04.18 Chapter 3 : Arithmetic for Computers (0) 2022.04.11 Chapter 2 : Instructions : Language of the Computer (0) 2022.03.24