-
Chapter 2 : Instructions : Language of the Computer컴퓨터 아키텍쳐 2022. 3. 24. 00:53728x90
Instructions
일의 기본 단위입니다.
CPU에서 실행되는 동작 또는 동작코드입니다.
instruction은 순차적으로 실행됩니다.
즉, CPU가 다음을 loop를 돌면서 실행합니다.
1. Fetch instrucion (명령어 가져오기)
2. Decode Instruction (명령어 해석)
3. Read source operands (명령어 소스 연산 읽기)
4. Execute (실행)
5. Write destination operand (연산의 목적지 쓰기)
6. Compute next PC (다음 PC를 계산)
Assembly and Binary code
Assembly
binary 코드가 텍스트 형식
컴퓨터 하드웨어는 이해하지 못함
순차적인 instruction

Binary code
순차적인 instruction들이 기계들이 읽을 수 있는 binary형식
IC 회로로 해석

Instruction Set Architecture
컴퓨터에서 사용되는 instrcution의 모음입니다.
소프트웨어와 하드웨어간의 계약/인터페이스
operations 와 storage 장소의 기능을 정의(레지스터)
소프트웨어가 하드웨어의 operation 및 storage를 호출하고 access하는 방법에 대한 정확한 설명
즉, instruction, register, memory, I/O등을 포함한 기계어 프로그램을 작성하기 위한 필요한 모든 정보를
가리킵니다.
이 정보를 Hardware에게 주면 hw가 이것을 실행합니다.
ISA는 어셈블리의 문법과 의미를 지정합니다.
ISA는 새로운 abstration(추상화)입니다.
즉, 다양하고 가격이 제각각이 하드웨어에서 동일한 소프트웨어를 구동할 수 있게 가능하게 합니다.
ISA는 instruction, 레지스터, data type, 메모리 주소 지정 모드에 관한것입니다.
The MIPS Instrucion Set
MIPS Instrucion set은 전형적인 현대 ISA이며 큰 시작을 이루고 있습니다.
embeded core 시장에서 높은 점유율을 가지고 있습니다.


Arithmetic Operations
두개의 source와 한개의 destination이 존재합니다.
ex) add a, b, c (a에 b+c의 값을 저장) 이때 a가 destination, b, c가 source 입니다.
모든 arithmetic 연산들은 이와 같은 형태를 지닙니다.
Design Principle 1(설계 원칙 1) : Simplicity favors regularity(간결성은 규칙성을 선호한다)
- 규칙성(regularity)은 구현을 간단하게 해줍니다.
arithemetic instruction은 오직 한개의 연산만 수행합니다.
정확히 3개의 변수만 가집니다.
- 간결성(simplicity)은 낮은 cost에서도 높은 성능을 가능하게 합니다.
피연자의 수가 일정하면 하드웨어가 변수의 개수에 비해 단순해지기 때문입니다.
EX)
C code: f = (g + h) - (i + j);
이것을 MIPS 코드로 컴파일하면
add t0, g, h # temp t0 = g +h
add t1, i, j # temp t1 = i +j
sub f, t0, t1 # temp f = t0 - t1
※ t0, t1은 레지스터입니다.
위의 예제에 나오는 변수들은 MIPS연산이 아닙니다.
실제 MIPS는 변수를 사용하지 않습니다. 모든 연산은 레지스터에 들어간 값들로 이루어집니다.
Register Operands
Arithmetic instruction들은 register operand를 사용합니다. (레지스터를 연산처리기로 사용)
레지스터는 매우 빠르고 작은 메모리 공간입니다. 레지스터는 CPU내에 특별한 위치에 위치하고 있습니다.
MIPS는 32개의 32-bit register file을 갖습니다.
- 자주 access하는 데이터를 위한 고속저장소
- 0 ~ 31 까지 번호로 매겨집
- 32-bit 데이터는 "word"라 불려집니다.
Assembler 이름들
- 임시값(temporary value)에 사용 $t0, $t1, ...., $t9 라는 이름의 레지스터
- 저장된 변수들(saved variable)에 사용 $s0, $s1, ,,,,,$s7 이라는 이름의 레지스터
Design Prinsiple(설계 원칙) 2 : Smaller is faster (작을수록 빠름)
메인 메모리는 수백만개의 구역을 가집니다. 하지만 레지스터는 32-bit가 32개일 뿐 엄청 작은 저장소입니다.
용량이 적어지면서 속도는 빠르게
EX)
C code : f = (g + h) - (i + j);
여기서 변수 f, g, h, i, j는 $s0, $s1, $s2, $s3, $s4에 담겨질것입니다.(mapping)
Compiled MIPS code:
add $t0, $s1, $s2 # temp t0 = g + h;
add $t1, $s3, $s4 # temp t1 = i + j;
sub $s0, $t0, $t1 # f = t0 - t1;
위 코드가 실제로 번역되는 MIPS 코드입니다.
Memory Operands in Data transfer Instructions
모든 데이터들은 register에 저장할 수 없습니다. register에는 오직 32개의 저장공간만 있을 뿐입니다.
main memory에는 배열, 자료구조, 동적 데이터(dynamic data(malloc, free)) 등이 저장됩니다.
arithmetic operation(산술 연산)을 하려면 data transfer instruction이 필요합니다.
load연산은 메인 메모리에 있는 value를 register로 전송하는 것입니다.
store연산은 register로부터 결과를 메인 메모리에 저장하는 것입니다.
메모리는 byte단위로 이루어집니다.
주소 한칸은 1 byte(8 bit)로 이루어집니다.
word 단위로 메모리에 정렬됩니다.
주소들은 4칸 단위로 묶입니다. (word = 4 byte = 32 bit)
예를들어 lw $t0, 8($zero)
lw는 load word의 약자로 메인메모리의 value를 regiser로 가져옵니다.
이때 8($zero)의 의미는 base address $zero에서 8 byte떨어진 위치에 접근한다는 의미입니다.
이때 8을 offset이라 하고 $zero는 base register라고 합니다.

MIPS는 Big Endian 입니다.
MSB가 word(4 byte)의 least address(가장 작은자리(오른쪽)의 주소)에 위치합니다.
즉, byte 단위로 뒤집혀서 들어갑니다.
반대로 Little Endian은 LSB가 least address에 위치합니다.
Byte Ordering
Mult-byte 데이터를 메모리에 저장하는 방법입니다.
크게 Big Endian, Little Endian 이 있습니다.예를들어 value값이 10인 int형 데이터를 메모리에 저장하려면
0000 0000 0000 0000 0000 0000 0000 1010 으로 저장됩니다.
이 때 첫 8 bit를 MSB, 맨 뒤 8 bit를 LSB라고 합니다.
0000 0000 0000 0000 0000 0000 0000 1010
컴퓨터는 메모리를 1 byte씩 읽습니다.
Big Endian
MSB가 lower위치에 옵니다.
0000 0000 0000 0000 0000 0000 0000 1010
Little Endian
LSB가 lower위치에 옵니다.
1010 0000 0000 0000 0000 0000 0000 0000
예를들어
int x = 0x1234567 이라면
주소값 &x는 0x100 이라고 가정하면

Big Endian에는 MIPS, Power PC, Mac 등 사용되고
Little Endian에는 x86, ARM CPU를 사용하는 Android, iOS, Windows 등 사용됩니다.
Little Endian 방식을 사용하는 컴퓨터에서 data 값을 전송하는데 받는 컴퓨터가 Big Endian이면
이상한 값이 전송됩니다. 따라서 컴퓨터간 통신을 할때에는 data를 읽는 방법을 규정해야합니다.
보통 Network API/LIB을 사용하여 Little Endian 데이터를 Big Endian으로 전환하는 과정을 거칩니다.
Memory Operand Example
1)
C code : g = h + A[8];
g는 $s1, h는 $s2, A의 base address는 $s3
Compiled MIPS code :
index 8은 32 byte(4 * 8 : 0, 4, 8, 12, 16, 20, 24, 28, 32)의 offset을 필요로 합니다.


메모리 $s3에 담긴 주소에서 32 byte만큼 떨어진곳(A[8])에서 1 word(4 byte)만큼의 데이터를 레지스터 $t0에 load
2)
C code : h + A[8];
h는 $s2에, A의 base address는 $s3
Compiled MIPS code :
index 8은 32 byte(4 * 8 : 0, 4, 8, 12, 16, 20, 24, 28, 32)의 offset을 필요로 합니다.

sw는 register에서 memory로 데이터를 옮깁니다.
register $t0에 저장된 데이터를 메모리안에 $s3에서 48 byte(A[12]) 만큼 떨어진 곳에 저장합니다.
Register vs Memory
CPU가 메모리에 직접 접근하는 것보다 Register에 접근하는 것이 훨씬 빠릅니다.
메모리의 데이터를 register에서 이용하기 위해 register는 데이터를 메모리로 부터 불러오고(load)
연산을 끝난후 다시 메모리에 저장(store) 하는 방법을 이용합니다.
컴파일러는 가능한 변수들을 register를 활용하여 처리해야합니다.
변수 처리를 위해 메모리에 접근하는 일을 덜 빈번하도록 해야합니다.
register의 최적화는 매우 중요합니다.
최대한 메모리에 접근하는 횟수를 줄여서 load와 store 연산을 줄여야 합니다.
Immediate Operands
즉각 연산입니다. (변수가 아닌 상수로 바로)
instruction에 상수(constant data)를 사용합니다.
ex)
addi $s3, $s3, 4 //s3 = s3 + 4
load, store 연산을 거치지 않고 바로 상수 4를 더해주기 때문에 연산속도가 빨리집니다.
immediate operation에 뺄셈(subtract)은 지원하지 않습니다.
따라서 덧셈에 음수값을 사용합니다.
ex)
addi $s2, $s1, -1 //s2 = s1 + (-1)
Design Prinsiple(설계 원칙) 3 : Make the common case fast(일반적인 경우를 빠르게 해라)
작은 수의 상수 (0, 1, -1 등)는 프로그래밍에 자주 사용됩니다.
큰 수는 자주 사용되지 않습니다. immediate operand가 지원되면 작은 값은 상수로 바로 사용가능합니다.
즉, immediate operand는 load 연산을 줄여줍니다.
The Constant Zero
MIPS register의 0번 register($zero)는 항상 0입니다.
값을 변경할 수 없는 고정된 상수, 읽기만 가능한 레지스터
많은 작업들에 유용합니다. 특히 register 간 이동에 매우 유용하게 사용됩니다.
ex)
add $t2, $s1, $zero // t2 = s1 + 0
$s1의 값을 그대로 $t2에 임시로 저장, 값 복사 합니다.
어차피 0을 더해봤자 상관없기 때문입니다.
다른 register로 값을 그대로 대입할 때 사용할 수 있습니다.
Unsigned Binary Integers
부호가 없는 이진수입니다.
n-bit 이진수라고 하면 범위는 0 ~ (2^n) - 1
32 bit는 0 ~ 4,294,967,295
만약 정수 값이 해당 bit의 개수를 초과하는 값이라면 overflow가 발생합니다.
예를 들어 unsigned 8 bit int형인 uint8_t a = 255라면 a = a + 1을 하게 되면 8 bit에서 256을 표현 불가능
하기 때문에 256이 아닌 0이 저장됩니다.
2s-Complement Signed Integers
2의 보수 방식을 취하는 부호가 있는 정수 표현입니다.
n-bit 이진수라고 하면 범위는 -2^(n-1) ~ 2^(n-1) -1 입니다.
가장 큰 수 : 10000....000
가장 작은수 : 01111...1111
ex) 1100 = -2^3 + 2^2 + 0 + 0 = -8 + 4 = -4
32 bit에서는 -2,147,483,648 ~ 2,147,483,647 입니다.
0 : 0000...0000
-1 : 11111....1111
Sign Extension
수의 bit범위를 확장합니다. (예를들어 8 bit에서 16 bit로 확장)
값은 그대로 보존합니다.
MIPS instruction set
addi : immediate value를 늘립니다. 상수 덧셈 (ex : addi $1, $2, 4)
lb, lh : loaded byte/halfword를 늘립니다.
beq, bne : displacement를 늘립니다. (ex : beq $1, $2, 100 //if($1 == $2) 100으로 이동
bne $s1, $s2, 25 //if($s1 != $s2) 25로 이동)
bit의 범위를 확장할때 부호 bit와 같은 값을 왼쪽으로 늘려주면 됩니다.
ex) 8 bit -> 16 bit
2 : 0000 0010 -> 0000 0000 0000 0010
-2 : 1111 1110 -> 1111 1111 1111 1110
Representing Instruction
instruction들은 binary로 인코딩 됩니다. 이것을 machine code라고 불립니다.
MIPS instruction (RISC instruction)
32-bit word로 인코딩 됩니다.
적은 종류의 포맷(규칙)으로 되어있습니다. operation code(opcode), register number....
규칙성을 갖습니다.
MIPS는 32 개의 레지스터를 갖고있습니다.
레지스터들은 각각의 번호마다 쓰이는 역할이 다릅니다.
$t0 ~ $t7 은 레지스터 번호가 8 ~ 15입니다.
$t8 ~ $t9 는 레지스터 번호가 24 ~ 25입니다.
$s0 ~ $s7은 레지스터 번호가 16 ~ 23입니다.
MIPS instruction의 3가지 종류를 알아보겠습니다.
MIPS R-format Instruction

op : operation code(opcode) 어떤 종류의 연산을 할지
rs : first source register number 피연산자1이 들어있는 레지스터 번호
rt : second source register number 피연산자2가 들어있는 레지스터 번호
rd : destination register number 연산결과가 담길 레지스터 번호
shamt : shift amount 쉬프트 연산 시에 사용합니다.
funct : opcode의 확장된 개념으로 op에 나타난 종류의 연산을 구체적으로 지정
R-format은 레지스터 number를 이용하여 add, addu, and, sll, srl 등의 연산을 수행할 수 있습니다.
ex)
add $t0, $s1, $s2
먼저 MIPS Green Sheet에서 add 명령이 어떻게 구성되어 있는지 확인합니다.

R-format으로 되있습니다.
rd rs rt 순서대로 읽습니다.
opcode는 0입니다.
func는 20(Hex 16진법)인것을 확인할 수 있습니다.
이제 R-format에 add $t0, $s1, $2를 넣겠습니다.
op rs rt rd shamt funct

이것을 10진수로 표현하면

이것을 binary code로 표현하면

위와 같습니다.
따라서 add $t0, $s1, $s2 => 00000010001100100100000000100000으로 바뀝니다.
그런데 이러한 R-format의 5 bit 필드는 2^5 = 32보다 큰 수를 표현할 수 없습니다.
이를 보완한것이 I-format입니다.
이전에 배운 Design Principle에서는 형태를 통일하라고 배웠습니다. 하지만 MIPS instruction은 3개로 나뉘었습니다.
Design Principle 4 : Good design demands good compromises (좋은 설계에는 적당한 절충이 필요하다)
모든 instruction의 길이를 (32 bit)로 같게 하되, instruction의 종류에 따라 format은 다르게 하는 것입니다.
MIPS I-format Instruction

I-format은 R-format과 달리 rd, shamt가 없고 constant or address를 저장하는 필드가 있습니다.
rs : base address
rt : destination(목적지) 혹은 source2(피연산자2) 레지스터 번호
constant : -2^15 ~ 2^15 - 1 의 수를 표현가능합니다.
address : rs에 담긴 base address로부터 얼마나 멀리 떨어져있는지(offset)
I-format은 R-format과 달리 16 bit를 이용해 상수와 주소표현이 가능합니다.
그래서 주소값을 가져오는 bne, beq, lw, sw 등의 분기문과 상수연산을 하는 addi, addiu, andi 등이 가능합니다.
ex)
lw $t0, 1200($t1)
$t1(주소값)에서 1200만큼 더한 곳의 주소값을 $t0에 저장

I-format으로 되있습니다.
opcode는 23(hex)입니다.
lw $t0, 1200($t1) 에서 rt = $t0, rs = $t1, constant = 1200입니다.
이를 10진수로 표현하면
op rs rt constant or address

이것을 binary code로 표현하면

lw $t0, 1200($t1)를 10001101001010000000010010110000 로 바꿔주었습니다.
Logical Operations
bit 단위 조작을 위한 instruction입니다.
word(32 bit)에서 bit 그룹을 추출하거나 새로 집어넣는데 유용합니다.
Shift Operations

MIPS R-format Instruction shamt : 몇칸이나 shift 할지
왼쪽으로 shift (<<)
전체 bit가 왼쪽으로 이동하며, 오른쪽의 빈 공간들은 0으로 채워집니다.
MIPS Instruction에서 sll로 표현합니다.
i bit만큼 왼쪽으로 shift한것은, 2^i 만큼 곱한것과 같습니다.
오른쪽 shift (>>)
전체 bit가 오른쪽으로 이동하며, 왼쪽의 빈 공간들은 0으로 채워집니다.
MIPS Instruction에서 srl로 표현합니다.
i bit만큼 오른쪽으로 shift한 것은, 2^i 만큼 나눈 것과 같습니다.
AND Operations
word에서 특정 부분의 bit들에 주목할 때 유용합니다.
특정 bit들을 선택하고 나머지는 0으로 볼 때
ex) and $t0, $t1, $t2

OR Operations
word에서 특정 부분을 포함시키고 싶을 때 유용합니다.
특정 bit 부분을 무조건 1로 바꾸고, 나머지는 그대로 계승하고 싶을 때
ex) or $t0, $t1, $t2

NOT Operations
word의 bit들은 모두 반전시키고 싶을 때 유용합니다.
0은 1로, 1은 0으로 바꿉니다.
그러나 MIPS는 NOT연산이 존재하지 않아 NOR 연산을 통해 NOT연산과 똑같은 기능을 구현해줍니다.
a NOR b = NOT(a OR b)
ex) nor $t0, $t1, $zero
위 연산은 NOT(t1 OR zero) 의 값을 t0에 저장합니다. 0과 OR연산을 하게 되면 아무러 변화도 일어나지 않습니다.
따라서 위 연산은 NOT연산과 똑같은 기능을 합니다.

Conditional Operations
조건문
만약 조건(condition)이 true라면, 표시(label)된 instruciton으로 향하게 하는 분기 (branch)
그렇지 않으면(false), 그대로 진행(continue sequentially)
beq rs, rt, L1
만약 re = rt라면, L1이라고 표시된 instruction으로 이동
bne rs, rt, L1
만약 rs != rt라면, L1이라고 표시된 instruction으로 이동
j L1
무조건 L1이라고 표시된 instruction으로 이동
Compiling If Statements (If 구문 컴파일)

C code:
if(i == j) f = g + h; else f = g - h;f = $s0, g = $s1, h = $s2, i = $s3, j = $s4
Compiled MIPS code:
bne $s3, $s4, Else
add $s0, $s1, $s2
j Exit
Else : sub $s0, $s1, $s2
Exit : ....
Compiling Loop Statements (반복 구문 컴파일)
C code:
while(save[i] = k){ i += i; }i = $s3, k = $s5, 배열 save의 시작주소는 $s6
Compiled MIPS code:
Loop: sll $t1, $s3, 2 (처음 주어질 i index만큼의 주소(4byte)를 위해 2^2=4를 곱해둠)
add $t1, $t1, $s6 (offset(위에서 구해둔 i*4)에 시작 주소 더하면 save[i]의 주소)
lw $t0, 0($t1) // lw $t0, $t1, 0
bne $t0, $s5, Exit
addi $s3, $s3, 1
j Loop
Exit: ...
Basic Blocksinstruction들이 순선대로 모인 집합입니다.
embeded branch(일체형 분기)는 없습니다. (끝 부분을 제외하고) 끝에는 있을 수 있습니다.
branch target(분기 대상, labeled)은 없습니다. (처음 시작 부분을 제외하고)처음에는 있을 수 있습니다.
즉, 중간에는 branch(분기)도 없고, labeled된 (점프할 곳을 지정)곳도 없습니다. 분기가 없는 일련의 연속 작업덩어리
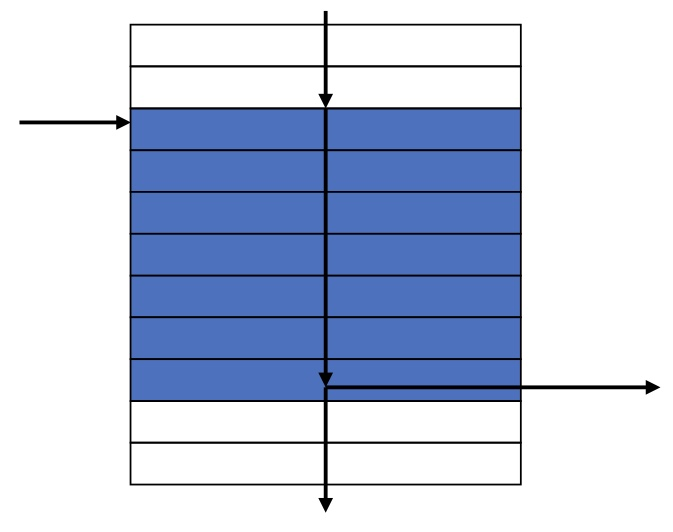
컴파일러는 최적화를 위해 이런 basic block들을 찾아냅니다.
고성능 processor는 basic block들의 수행을 가속시킬 수 있습니다.
More Conditional Operations
만약 조건이 true라면 결과를 1로 설정하고 그렇지 않으면 0으로 설정합니다.
slt rd, rs, rt
if(rs < rt) rd = 1; else rd = 0;slti rt, rs, constant
if(rs < constant) rt = 1; else rt = 0;beq와 bne를 혼합으로 사용할 수 있습니다.
slt $t0, $s1, $s2 #if($s1 < $s2)
bne $t0, $zero, L #0이 아니면 L로 이동
Branch Instruction Design
하드웨어 입장에서 <, ≥, ....연산은 =, ≠연산보다 느립니다. (복잡합니다)
모든 branch를 지원하면, 한 instruction마다 기존보다 더 많은 일을 수행하게 되고, clock 속도가 느려집니다.
모든 instruction 전체가 불이익을 받습니다. (느려진 clock 속도 때문)
beq와 bne가 더 일반적인 경우 많이 쓰입니다.
이것은 좋은 설계를 위한 타협입니다.
Signed vs Unsigned
Signed 비교 : slt, slti
Unsigned 비교 : sltu, sltui
ex)
$s0 = 1111 1111 1111 1111 1111 1111 1111 1111
$s1 = 0000 0000 0000 0000 0000 0000 0000 0001
slt $t0, $s0, $s1 #signed
-1 < 1 가 true면 $t0 = 1입니다.
sltu $t0, $s0, $s1 #unsigned
4, 294, 967, 295 < 1 가 false이기 때문에 $t0 = 0입니다.
Procedure Calling
프로시저(함수) 실행의 6단계 입니다.
- 1) 메인 routine[Caller]이 인자(argument)를 프로시저[Callee] 가 접근가능한 곳에 위치시킵니다.
- 2) Caller가 제어권(control)을 Callee에게 넘겨줍니다.
- 3) Callee는 필요한 storage(메모리)을 얻습니다.
- 4) Callee는 요구되는 일을 수행합니다.
- 5) Callee는 결과값을 Caller가 접근가능한 곳에 위치시킵니다. ($v0 ~ $v1 은 결과값을 위한 2개의 register)
- 6) Callee는 제어권(control)을 Caller에게 반납합니다.
($ra는 하드웨어가 사용하는 반환 주소를 위한 register, Caller에게 제어권을 주기 위한 주소입니다.)
Register Usage
$a0 ~ $a3 : 인자(argument) <레지스터 번호 : 4 ~ 7>
오직 4개만 존재하며 4개가 넘을 시 메모리의 stack을 이용합니다.
$v0, $v1 : return값을 담는 register <레지스터 번호 : 2, 3>
return값은 오직 1개만 필요합니다. 하지만 return값이 32 bit를 넘을 경우 $v1을 이용하여 추가공간을 사용합니다.
$t0 ~ $t9 : 임시값을 저장하는 register <레지스터 번호 : 8 ~ 15>
다른 함수 호출 시 보존되지 않습니다. 즉, 덮여 쓰일 수 있는 값입니다.
$s0 ~ $s7 : saved값을 저장하는 register <레지스터 번호 : 16 ~ 23>
보존 되어야 하는 값이므로 메모리의 stack을 이용하여 미리 값을 복사해놓고 덮어쓴 다음 return하기 전에
원래 값을 restore합니다.
$gp : global pointer <레지스터 번호 : 28>
전역변수에 사용합니다.
$sp : stack pointer <레지스터 번호 : 29>
스택 포인터 입니다.
$fp : frame pointer <레지스터 번호 : 30>
frame 포인터입니다.
$ra : return address <레지스터 번호 : 31>
반환 주소 입니다.
Procedure Call Instruction
PC는 Program Counter로 실행될 명령의 주소를 담고있습니다.
프로시저 호출(call)은 jal함수를 통해 이루어집니다.
프로시저 호출(call) : jal(jump and link)
jal "Procedure Label"
바로 다음에 올 instruction의 주소를 $ra에 담습니다.
target의 주소로 이동(jump) 합니다.
프로시저 리턴(return) : jr(jump register)
jr $ra
jr연산은 target의 레지스터로 이동하는 연산입니다. $ra의 값을 PC에 넣어 프로시저 반환(return)이
이루어지게 합니다.
jr은 computed jump에 사용되기도 합니다. (case / switch 구문)
Leaf Procedure Example
leaf procedure : 함수 내에서 다른 함수를 호출하지 않음
C code
int leaf_example(int g, h, i, j){ int f; f = (g + h) - (i + j); return f; }인자들 g는 $a0에 h는 $a1, i는 $a2, j는 $a3에 넣습니다.
f는 $s0에 (f는 leaf_example안에 있는 routine이므로 스택으로써 $s0에 넣습니다)
return값은 $v0에 넣습니다.
MIPS code

먼저 addi연산을 통해 스택 포인터를 -4감소 시켜
4 byte만큼의 stack 사용공간을 확보합니다.
(스택은 위에서 아래로 이동)
sw를 이용하여 $s0의 값을 현재 스택의 위치에 저장
(g + h) - (i + j)를 수행하기 위해
add, add, sub를 사용한 후
return값을 $v0에 해당 결과를 저장합니다.
이때 add연산을 사용했는데 MIPS에는 별도의 copy연산이 없어
add연산과 zero를 이용하여 copy를 수행합니다.
그 다음 처음에 스택에 저장해 놓았던 $s0을 불러온 후 스택 포인터를 다시 4를 더해 사용했던 스택공간을
되돌려줍니다. 그 후 저장되어있는 $ra를 이용하여 본래의 함수로 return합니다. 이때 $v0에는 return값이 담겨있습니다.
Non-Leaf Procedures
non-leaf 프로시저 : 프로시저 내에서 다른 프로시저를 호출(call)하는 형태입니다.
중첩된 호출(call)이 있으므로, Caller는 스택에 다음값들을 저장합니다.
1. return될 주소(Leaf와 다르게 $ra 하나에 의존할 수 없기 때문)
2. 필요한 argument들(인자), 임시값들
Call이후에 (한 routine이 끝나면) 스택에 저장해둔 값을 복귀시켜야합니다.
Non-Leaf Procedure Example
C code
int fact(int n){ if(n < 1) return 1; else return n * fact(n - 1); }인자 n은 $a0에 넣습니다.
return 값은 $v0에 넣습니다.
MIPS code

처음에 addi를 통해 8만큼의 stack사용 공간을 확보했습니다.
재귀적으로 함수를 수행하기 위해서는 $ra와 argument인 $a0가 덮여 쓰여서는 안되기 때문입니다.
따라서 해당 스택에 $ra와 $a0의 값을 저장한 다음 if연산을 수행합니다.
만약 if(n<1)이 true면 분기가 일어나지 않고 아래에 있는 addi를 수행하게 되며
만약 false이면 L1에 있는 addi연산을 수행하게 됩니다.
위의 코드에서는 $a0의 값을 -1만큼 감소하여 다시 한번 함수를 호출하게 됩니다.
새롭게 호출된 함수는 다시 스택을 할당하고 현재 인자와 $ra를 저장한 후에 위와 똑같은 작업을 수행합니다.
결국 인자가 0이 된다면 더이상 재귀가 일어나지 않고 return이 시작됩니다.
먼저 스택의 Top에 위치한 함수는 사용했던 stack주소를 +해줌으로 스택을 pop하여 $ra로 이동합니다.
이렇게 하여 이동된 주소는 jal fact밑인 lw명령입니다. 즉, 함수가 return되어 돌아왔으므로 현재 함수의 스택에서
$a0와 $ra를 다시 load하여 return 주소와 현재 함수의 인자를 불러와 이전 함수에서 return받았던 $v0과 곱하는
연산을 수행한 후 에 다시 $ra주소로 return합니다.
이 과정을 처음에 함수가 불려졌던 곳까지 반복하고 결국 사용했던 모든 스택이 pop되고 마지막에 남은
$v0이 fact함수의 결과값이 됩니다.
Local Data on the Stack
프로그램에서 프로시저(function)가 호출 될떄 메모리가 어떻게 할당되는지 봅니다.
레지스터가 한정적인 개수만 존재하므로 우리는 stack을 이용합니다.

프로시저 호출에서 (a)전, (b)도중, (c)후 $sp는 스택의 top을 가리킵니다. (activation record 의 끝 주소)
$fp(frame pointer)는 이번 프로시저에 할당되기 직전 가리키고 있던 스택포인터를 가리킵니다.
(activation record의 시작주소)
Procedure frame (activation record)
$fp에서 $sp까지, 하나의 function을 실행할 때 할당되는 메모리 공간입니다.
몇몇 컴파일러들은 스택 공간을 관리하기 위해 사용합니다.
local data는 Callee에 의해 할당됩니다.
Memory Layout

Text : 프로그램 코드 (instruction 들)
PC(Program Counter)가 이 영역에서 움직이면서 현재 실행될 instruction을 가리킵니다.
Static data : 전역 변수들
C에서 static 변수, constant 배열이나 string 등
$gp(global pointer)는 Static data를 가리키기 쉽도록 text의 끝과 dynamic data의 시작의 중간에 위치하여,
±offset으로 데이터를 가리켜 줍니다.
(MIPS에서는 중간, 다른 프로세서에서는 다르게 동작할 수도 있습니다.)
Dynamic data : heap 메모리에 할당
C에서 malloc
Stack : 현재 영역에서 사용할 자료 및 복귀 주소 등
activation record 들이 쌓였다 복귀됩니다.
Dynamic data영역은 점점 높은 주소로, Stack을 점점 낮은 주소로 할당 됩니다.
만약 Stack과 Dynamic data영역이 만나게 되면 더 이상 메모리를 새로운 곳에 사용할 수 없습니다.
만약 메모리를 지켜주는 protection이 있다면 프로그램이 서로 충돌해 멈추게 하겠지만
protection이 없다면 dynamic data와 stack이 만나더라도 아무일도 일어나지 않아 데이터를 덮어쓰게 되어
프로그램에 치명적인 오류를 야기시킬 수 있습니다.
Reserved : 특별한 사용을 위해 예약되어 있는 공간입니다.
Character Data
문자 데이터입니다.
Byte-encoded character sets
- ASCII : 128(2^7)개의 문자표현 95개의 그래픽, 33개의 제어용
- Latin-1 : 256(2^8)개의 문자 표현 ASCII보다 96개의 그래픽이 더 많습니다.(191개)
Unicode : 32-bit character set
- JAVA, C++ 등에서 쓰입니다.
- 대부분의 국가 언어 문자와 기호를 표현 가능합니다.
- UTF-8, UTF-16 : 여러길이의 인코딩이 존재합니다.
Byte / Halfword Operations
Byte : 1 byte(8 bits)
Halfword : 2 byte(16 bits)
bitwise operation으로 1 bit씩 옮길 수 도 있지만, byte/halfword 단위로도 데이터 이동이 가능합니다.
MIPS byte / halfword load/store (String 처리가 일반적인 경우입니다.)
- lb rt, offset(rs) lh rt, offset(rs)
메모리 주소로부터 signed값의 하위 각각 8 bit, 16 bit들을 불러와 32 bit로 늘려서 (LSB의 값과 같은 bit가 복제되어
왼편에 나열) 레지스터 (rt)에 불러옵니다.
- lbu rt, offset(rs) lhu rt, offset(rs)
메모리 주소로부터 unsigned값의 하위 각각 8 bit, 16 bit들을 불러와 32 bit로 늘려서 (LSB 왼편은 모두 0으로 나열)
레지스터 (rt)에 불러옵니다.
- sb rt, offset(rs) sh rt, offset(rs)
rt의 값 중 하위 각각 8, 16 bit의 값을 메모리 주소가 가리키는 곳에 저장합니다.
String Copy Example
C code (null 문자(\0)로 끝나는 string
void strcpy(char x[], char y[]){ int i = 0; while((x[i] = y[i]) != '\0'){ i += 1; } }x, y의 주소에는 각각 레지스터 $a0, $a1
i의 값은 $s0
MIPS code

먼저 addi연산을 통해 스택 포인터를 이동시켜 스택을 사용할 공간을 확보했습니다.
그 후 i의 값을 스택에 저장하고 i = 0을 수행합니다.
그 다음 $t1에 $s0과 $a1을 더한 값을 저장합니다. 이는 y + i의 주소를 의미합니다.
그 다음 $t2에 y[i]의 값을 저장합니다.
그 다음 $t3에 마찬가지로 x + i의 주소를 저장한 후에 sb를 통해 x[i] = y[i]의 연산을 수행합니다.
그 다음 beq연산을 통해 x[i]의 값이 0인지 확인하고 0이라면 L2로 점프하여 다시 $s0의 값을 불러오고 스택을
pop하여 return하는 구조입니다.
32-bit Constants
대부분의 상수들은 작기 때문에 I-format의 constant 필드를 통해 해결이 가능합니다.
하지만 가끔씩 32-bit 상수가 쓰일 수 있습니다.
이때 $s0 레지스터를 이용할 수 있습니다. 레지스터는 32 bit의 크기를 가지고 있습니다.
먼저 16 bit의 상수를 lui연산을 통해 $s0 에 왼편 16 bit 자리에 복사합니다.
그 다음 ori연산을 통해 $s0의 나머지 오른편 16 bit를 채워 32 bit의 상수가 저장되게 합니다.

Branch Addressing

MIPS에는 beq, bne 등 분기(branch) 연산이 존재합니다.
이는 조건을 판단하여 원하는 주소로 이동하는 명령어 입니다.
beq, bne 연산은 I-format 연산으로 16 bit의 주소를 담을 공간을 가지고 있습니다.
대부분의 분기(branch)연산의 목표 주소는 현재 위치에 가까운 곳에 위치하고 있기 떄문에
16 bit에서 처리가 가능합니다.(if, loops 등)
branch 연산에 사용하는 주소 계산법은 PC-relative addressing (PC가 가리키는 주소를 활용)입니다.
목표 주소(target address) = PC(Program Counter) + offset * 4입니다.
여기서 offset은 16 bit에 저장된 주소를 말합니다. 4를 곱해주는 이유는 하나의 연산이 4 byte이기 때문입니다.
MIPS에서, PC는 어떤 루틴에 들어가면, 다음에 실행할 명령의 주소값을 가리키게 되어있습니다.
즉, 이미 이번 분기에 진입할 때 4만큼 증가 했었습니다.
따라서 실제로는 (PC + 4) + offset * 4를 통해 목표 주소(target address)를 설정할 수 있습니다.
Jump Addressing
jump연산에는 j와 jal 연산이 있습니다. 이 연산을 통해 어느 주소든지 이동이 가능합니다.
branch와 달리 멀리 도 갈 수 있습니다. PC와 거리가 멀더라도 text segment를 통해 이동이 가능합니다.

위 명령을 J-format 형식에 속합니다. J-format은 6 bit의 op필드와 26 bit 주소 필드를 가집니다.
Target address = address * 4를 통해 설정할 수 있습니다. 따라서 총 2^28(2^26 * 4) bit만큼 이동가능합니다.
하지만 총 32 bit의 주소를 이동하기에는 bit가 모자랍니다. 따라서 이때 필요한 추가적인 4 bit를 PC의 상위 4 bit
를 이용해 4 + 28 = 32 bit공간을 이동할 수 있습니다.
Target Addressing Example
C code
while(save[i] = k){ i += i; }i는 $s3에 , k는 $s5에, 배열 save의 시작주소는 $s6에
MIPS
Loop : sll $t1, $s3, 2 (처음 주어질 i index만큼의 주소(4byte)를 위해 2^2=4를 곱해둠)
add $t1, $t1, $s6 (offset(위에서 구해둔 i*4)에 시작 주소 더하면 save[i]의 주소)
lw $t0, 0($t1) // lw $t0, $t1, 0
bne $t0, $s5, Exit
addi $s3, $s3, 1
j Loop
Exit: ...
Loop의 메모리 주소는 80000이라고 가정합니다.
Branching Far Away
만약 분기 대상(branch target) 주소가 너무 멀어서 16-bit의 offset으로도 표현할 수 없다면,
(branch addressing은 PC + 16 bit의 offset으로 위아래를 표현하기 떄문에 ±2^15 byte만 이동가능)
어셈블러 코드를 다시 작성하게 됩니다.
ex)
beq $s0, $s1, L1 (L1거리가 표현이 불가능한 거리)
↓
bne $s0, $s1, L2
j L1
L2: .....
즉, beq의 명령을 수행할 수 없기 때문에 bne와 j(jump addressing) 명령을 통해 두개로 나누어 이동을 수행합니다.
Addressing Mode Summary

Translaion and Startup
실제 작성된 코드가 어셈블리어로 어떻게 바뀌고 프로그램으로서 실행되는지 살펴봅니다.

1. C언어(HLL)로 작성된 프로그램을, 컴파일러가 어셈블리어 프로그램으로
2. 어셈블리어 프로그램을, 어셈블러가 object(기계어 module)로
대부분의 컴파일러는 위 두과정을 한번에 일괄적으로 진행합니다.
3. 내 코드로 만들어진 object들과, 사용한 라이브러리에 의해 만들어진 object들을 linker가 합쳐서
실행가능한 기계어 프로그램(실행 파일)으로 작성합니다. 이 과정을 static linking이라고 합니다.
(static linking은 프로그램에 라이브러리에 의한 내용이 모두 포함됩니다.)
4. 실행 파일이 실행(OS의 메모리에 올라와야 함)되기 위해, Loader가 실행파일을
메모리에 load(메모리에 프로그램을 올림)
'컴퓨터 아키텍쳐' 카테고리의 다른 글
Chapter 5 : Memory Hierarchy (0) 2022.06.15 Chapter 4 : Processor (0) 2022.06.10 Logic Design (0) 2022.04.18 Chapter 3 : Arithmetic for Computers (0) 2022.04.11 Chapter 1 (0) 2022.03.06