-
Chapter 4 : Processor컴퓨터 아키텍쳐 2022. 6. 10. 20:23728x90
Instruction Execution
프로그램에 메모리가 load되면 instruction들은 instruction memory 에 순서대로 주소를 가지며 위치합니다.
PC 는 현재 실행하는 명령어의 메모리 주소를 가집니다. (정확히는 다음 명령어)
PC에 담긴 주소로 instruction memory에서 instruction을 읽어오는 것을 fetch instruction이라고 합니다.
instruction에서 레지스터 번호($at, $t0, $s0,...)를 통해 레지스터에 접근하여 값을 읽어오는것을 read register라고
합니다.
instruction의 class에 따라 계산에 ALU를 사용하기도 합니다.
또한 메모리에 접근하여 데이터를 load /store할 수 있고 PC ← target address(jump 명령어), PC += 4 (32bit)
순차적 진행
ALU
산술 계산
load / store를 위한 메모리 주소 계산
branch 대상 주소(target address) 계산
CPU Overview

빨간색 동그라미 친 부분을 보면 실제로는 여러선이 함께 만날 수 없습니다.
따라서 MUX(Multiplexer)를 사용해 하나의 신호를 선택해야 합니다.
Control
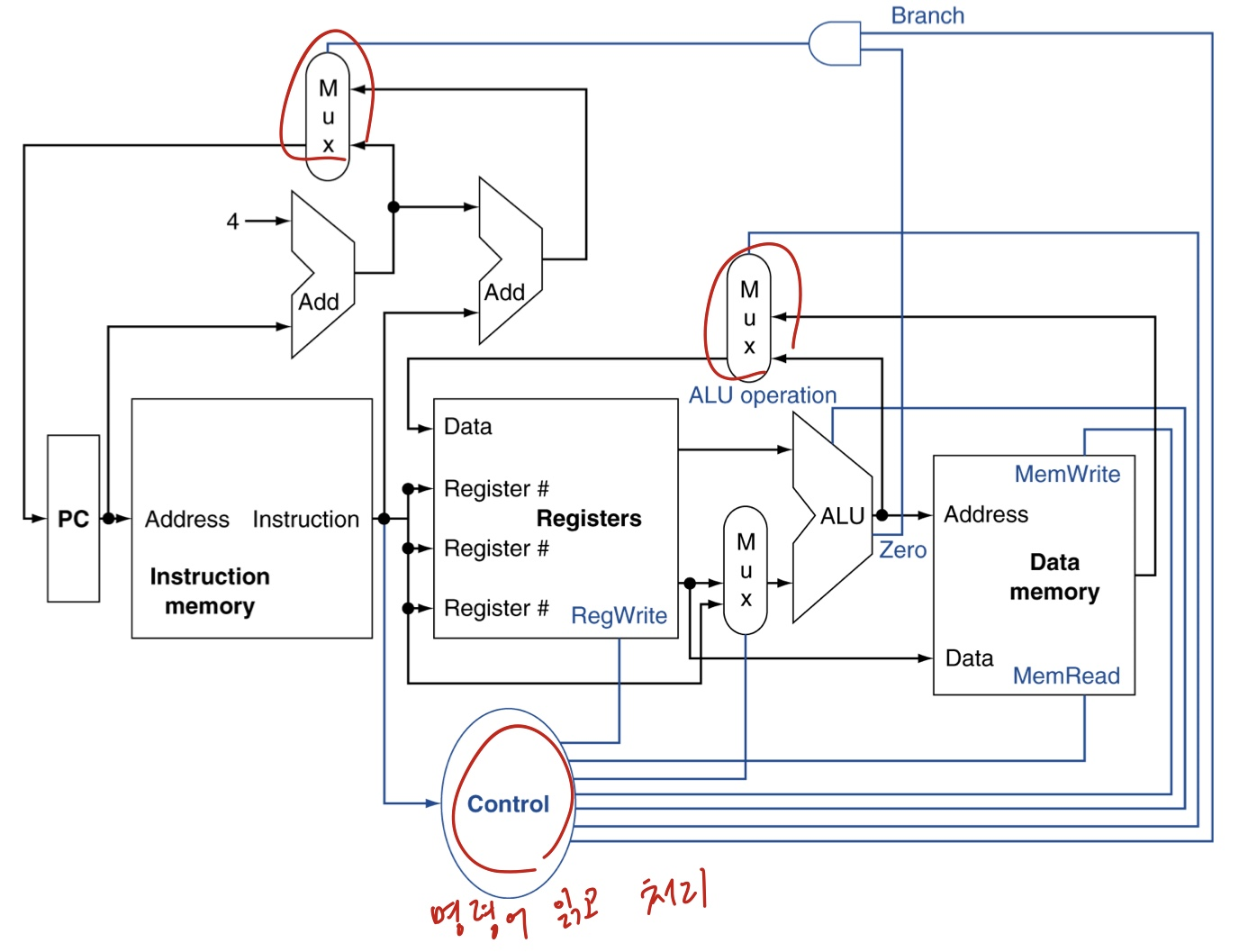
control은 각각의 하드웨어 모듈(레지스터, 메모리, ....)이 어떻게 동작하는 지를 control해주는 회로입니다.
명령어를 읽어서 해당하는 control 신호를 만듭니다.
Logic Design Basics
information은 binary(0, 1)로 인코딩됩니다.
low = 0, high = 1
하나의 bit를 표현하기 위해 한개의 wire(선)이 필요합니다.
따라서 multi data는 multi-wire bus들로 인코딩 됩니다.
Combinational elements
데이터에 의해 동작
input에 따라 output이 결정
State(sequential) elements
information을 저장
Combinational Elements

Sequential Elements

register : 데이터를 회로에 저장
clock 신호를 사용해 언제 저장된 값이 업데이트 되는지 결정합니다.
edge-triggered : clock이 0에서 1로 변할 때 업데이트(falling edge-triggered도 존재)
현재 값과 input, clock 타이밍에 의해 output이 결정됩니다.
레지스터, 메모리 등에 사용됩니다.
Clocking Methodology

combinational logic은 clock cycle 동안 데이터를 변형(transform)합니다.
clock edge간에 그사이에 데이터를 변형하며 현재 state들로 부터 input이 되고
또 clock period가 지나면 또 state가 됩니다.
가장 지연이 긴 시간 (가장 느린 logic)이 clock period를 결정합니다.
Buliding a Datapath
Datapath
데이터가 흐르는 경로입니다.
연산을 위한 데이터든, 그 결과든 흘러서 어디론가 전달되거나 저장되거나 해야합니다.
CPU에서 프로세스 data와 주소들의 요소가 전달되는 길입니다.
레지스터, ALU, MUX, 메모리, ....등 의 모듈들이 연결되는 통로
우리는 MIPS datapath를 순차적으로 만들것입니다.
Instruction Fetch

PC는 계속 해서 4를 더해 다음 instruction을 읽어 나갑니다.
R-Format Instruction

MIPS에서 R-Format은 3개의 register(rs, rt, rd)를 사용합니다.
register는 산솔/논리적 작업을 수행하고 2개의 read register를 이용해 결과를 write register에 씁니다.
ALU에서는 register에서 나온 2개의 read data input이 들어갑니다.
결과는 다시 register로 write data로 갑니다.
(레지스터에 다시 쓰는것은 write data
레지스터에서 다른곳으로 데이터가 가는것은 = 레지스터의 데이터를 다른곳에서 쓰는것이 read data)
Load / Store Instruction

대상 register에서 읽습니다(read)
16 bit의 offset을 이용하여 주소를 계산합니다.
주소계산에는 ALU가 사용됩니다. ALU는 32 bit이기 때문에, 32 bit로 확장해 사용합니다.
(offset은 +/-가 있으므로, sign-extend로 부호를 유지한채 확장합니다.)
Load : 메모리를 읽고, 레지스터를 업데이트(메모리에서 레지스터로)
Store : 레지스터의 값을 메모리에 기록(레시스터에서 메모리로)
Branch Instructions

대상 register에서 읽습니다.(read)
읽은 값을 비교하기 위함입니다.
이제 읽은 값을 ALU를 사용해 비교합니다. 두개를 뺀 결과를 Zero와 검사해 output이 발생합니다.
zero와 같으면 뺀게 0이니, output은 1입니다.(두 개의 값이 서로 같음)
zero와 다르면 뺀게 0이 아니므로 output은 0입니다.(두개의 값이 서로 다름)
branch를 통해 jump한다면 대상 주소(target address)도 계산하여야 합니다.
I-format instruction의 address부분에 담긴 16 bit의 정보(displacement, 얼마나 위(-), 아래(+)로 움직일지)를
32 bit로 확장하기 위해 sign-extend합니다.
그리고 2번 shift left합니다. (word(32 bit) displacement)
PC + offset * 4 형태의 PC - relative addressing방식입니다.
계산된 결과를 PC에 더합니다.(PC-relative addressing)
PC에는 이미 현재 명령어의 다음 주소인 PC + 4 상태이므로(instruction fetch에서 이미 더해짐)
+4를 감안해서 주소를 계산합니다.
PC-relative addressing은 Chapter 2복습
Composing the Elements
각 요소들을 통합하여 한 clock cycle에 동작할 수 있도록 합니다.
한 clock cycle에 하나의 instruction만 실행합니다. 각 datapath요소는 한번에 하나의 기능만을 수행할 수 있습니다.
따라서 data memory와 instruction memory들을 분리해야합니다.
(그렇지 않으면 하나의 명령어가 동시에 접근하려 합니다.)
data source가 교차하는 곳에서는 MUX를 사용해 다른 instruction에 다른 경로에 대응할 수 있도록 합니다.
R-Type / Load / Store Datapath

Full Datapath

single cycle로 돌아가는(간소화 된 version) MIPS의 구현 회로입니다.
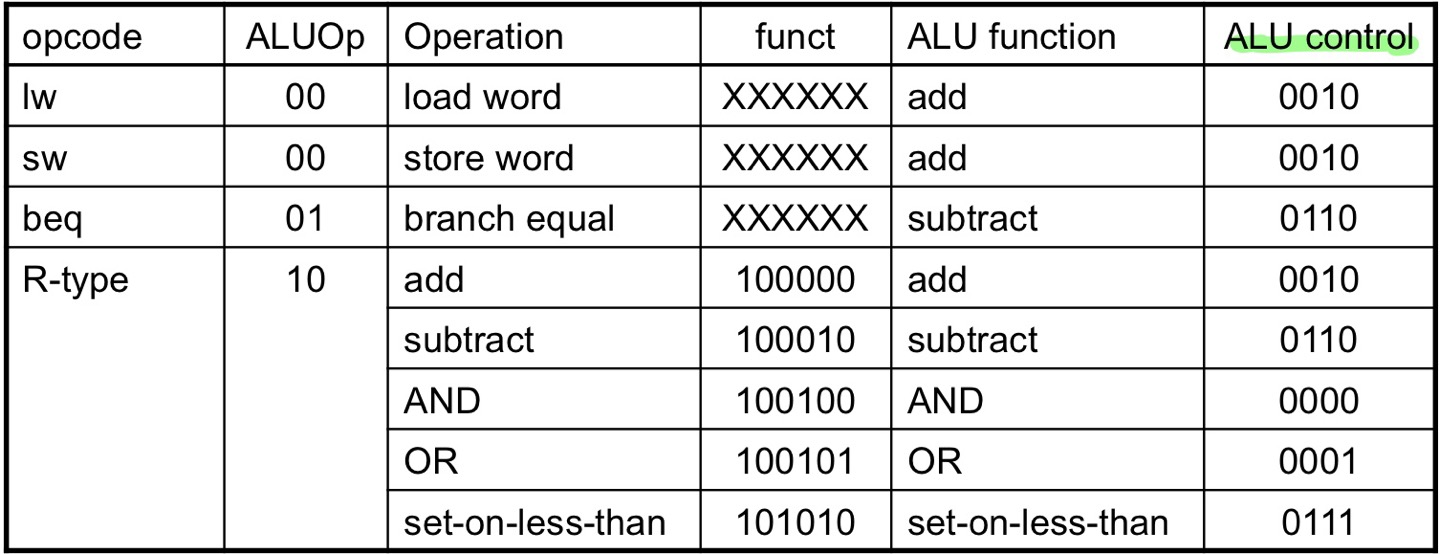
ALU Control
R-type이 아닌 instruction의 경우 opcode로 인해 모든 것이 결정됩니다.
- Load / Store
ALU는 add 기능을 수행합니다.
ALU op = 00
- Branch
ALU는 subtract 기능을 수행합니다.
ALU op = 01
- R-type
funct filed의 값에 의해 ALU 기능이 결정됩니다.
ALU op = 10


opcode로 부터 2-bit 부분을 가져와서 ALU op로 도출합니다.
8 bit를 input으로 받아 4 bit의 output을 결정하는 형태입니다.
combinational logic을 사용해 ALU control을 만들어 냅니다.
The Main Control Unit

control 신호는 instruction으로 부터 얻어집니다.
Implementing Jumps

jump instruction은 j-format instruction입니다.
jump는 word address(직접 주소)를 사용하므로 맨끝에 00을 붙여서 byte address로 변환하고
concatenation(이어 붙이기) 방식으로 PC를 업데이트
- 26 -bit의 address
- 위에 left shift를 두번하여 (28-bit)
- 현재 PC의 상위 4 bit 뒤에 위를 합쳐서 ( 4 + 28) = 32 bit
opcode로 부터 해석된(decode) 추가적인 control 신호(signal)이 필요합니다.
Datapath With Jumps Added

Performance Issues
- 가장 지연시간이 긴 부분(longest delay)가 전체 클럭 주기(clock period)를 결정합니다.
특히 길이가 긴 경로(경로가 길어서 delay가 클 확률이 높은): load instruction
instruction memory → register → ALU → data memory → register
- 다른 instruction에 다른 주기로 실행할 수 없습니다.
- 모든 instruction은 한 clock cycle에 실행되어야 하며, 모두 같은 clock cycle time이어야 합니다.
- 설계 원칙(design principle)을 위배합니다.
making the common case fast(가장 일반적인, 자주 사용되는 경로를 빠르게 하라)를 위배.
가장 느린 것에 맞춰지니까.
자주 사용되는 경로를 빠르게 하려고 해봤자, 가장 느린 것에 맞춰짐. 50을 10으로 줄여봤자, 100이 존재하면 헛수고.
이를 위해 우리는 pipelining을 통해 성능을 향상시킬 것입니다.
Pipelining Analogy

parallelism(병렬 처리)는 성능을 향상시켜줍니다.
위에서 순서대로 빨래를 하는 것보다
당연히 밑에 있는 것처럼 연속적으로 하는 것이 더 빨릅니다.
MIPS Pipeline
MIPS는 5개의 stage로 나눠서 한 stage가 하나의 clock에 수행되도록 합니다.
1. IF : 메모리로 부터 Instruction Fetch (메모리로부터 명령어 불러옵니다.)
2. ID : Instruction Decode & register read (명령어 해석, 레지스터 read)
3. EX : EXcute operation (작업 실행) 혹은 calculate address(주소계산)
4. MEM : access MEMory operand (메모리에 접근)
5. WB : Write result Back to register (레지스터에 결과를 다시 기록)
Pipeline Performance

각 stage별 시간을 측정해보면 레지스터 read, writer에는 각각 100ps가 소요됩니다.
다른 stage들은 200ps입니다.
이 중 가장 긴 것(critical path = lw(800ps))을 기준으로 하나의 clock(cct) = 800ps를 결정합니다.
pipeline화 된 data path와 single-cycle의 data path를 비교해보면

single cycle에서는 총 소요시간인 800ps 그대로,
pipelined 에서는 가장 소요시간이 긴 200ps 입니다.
Pipeline Speedup
만약 모든 stage 들이 비슷한 처리시간을 갖는다면 즉, 모두 같은 시간이라면 stage의 개수 배의 성능향상 효과
Time between instructions(pipelined) = Time between instructions(non pipelined) / stage의 개수
만약 모든 stage들이 균등하지 않다면, 속도 향상의 효과는 더 적을 것입니다.
왜냐하면 가장느린 stage에 맞춰지므로, 총 시간이 800ps 이지만, 한 stage가 700ps 라면,
다른 stage는 대기해야합니다.
속도향상은 throughput을 늘려서 얻은 결과입니다.
병렬식으로 동시에 여러 instruction을 실행 시키기 때문
지연시간(latency, 각 instruction 하나 실행에 걸리는 시간) 자체는 줄어들지 않습니다.
Pipelining and ISA Design
MIPS ISA는 Pipelining에 적합한 구조입니다.
- 모든 instruction은 32bit 입니다( 길이가 같습니다.)
한 cycle안에 fetch하고 decode하기 쉽습니다.
하드웨어 구현과 pipeline의 적용이 쉽습니다.
- 적은 종류의 규격화된 instruction format
R, I, J format
한 번에 decode하고 레지스터 read 가능
- Load / Store addressing
주소 계산을 3번째 stage에서, 메모리 접근은 4번째 stage에서 이루어집니다.
즉, stage별로 다른 작업을 수행할 수 있습니다.
- memory oprand의 정렬(alignment, 주소가 4byte씩 되어있습니다)
memory access는 한 cycle안에 이루어집니다. 즉 데이터를 읽을 수 있습니다.
만약 정렬되있지 않다면 memory access를 2번 해야합니다.
Hazards
pipeline에서는 매 cycle마다 instruction 하나가 수행되는 것이 중요합니다.
즉, 다음 cycle에서는 다음 instruction이 시작되는 것이 중요합니다.
이를 방해하는 것이 hazard라고 합니다.
크게 3가지의 hazard가 존재합니다.
- Structure hazards
필요한 resource가 다른 instruction에서 사용중인 경우
- Data hazards
이전 instruction의 수행결과가 필요해서 wait해야 하는 경우
다른 instruction이 데이터를 read / write하고 있다면 완료하기 까지 기다려야 합니다.
특히 lw / sw한 data를 사용하는 경우는 Load-use data hazard라고 합니다.
- Control hazard
이전 instruction의 결과에 따라 jump할지말지 결정해야하는 경우
Structual Hazards
하드웨어 resource를 이용하는 것에서의 충돌을 의미합니다.
single memory를 사용하는 MIPS Pipeline에서
Load / store 명령은 data access을 위해 memory에 접근합니다.
instruction fetch도 instruction을 가져오기 위해 memory에 접근합니다.
서로 동시에 진행될 수 없으므로 한 쪽은 대기를 해야하고, 해당 cycle를 지연(stall) 시킬 수 있습니다.
즉, pipeline에 bubble을 야기 할 수 있습니다.
따라서 pipeline화 된 datapath는 instruction memory와 data memory가 분리되어야 합니다.
(메모리에서 instruction영역과 data 영역 분리 혹은 instruction 과 data cache를 분리)
대부분의 structure hazard는 resource의 부족으로 인해 발생하며, resource를 추가하면 해결되는 경우가 많습니다.
Data Hazards
뒤의 instruction이 앞의 instruction의 결과를 사용할 때 발생합니다.
ex)
add $s0, $t0, $t1
sub $t2, $s0, $t3
앞의 instruction인 add의 결과에 따라 그 뒤에 instruction인 sub에도 영향이 갑니다.
forwarding이 없을 경우 instruction의 결과는 WB가 끝나야 업데이트 됩니다.
그렇기 때문에 앞의 instruction의 연산결과를 바로 뒤의 instruction에서 사용할 수는 없습니다.
data hazard는 값을 write 한 후 read해야 하는 RAW(Read After Write) data depedency가 발생합니다.

위의 예시를 보면 2번째 cycle에 바로 sub이 실행되면 3번째 cycle에서 register의 값을 읽어야 하지만,
아직 add에서의 연산결과가 register file에 업데이트 되지 않았습니다. 여기서 hazard가 발생합니다.
마찬가지 이류로 3번째 cycle에서 sub을 실행하는 것도 안됩니다.
따라서 2개의 bubble이 발생해 2개의 cycle손실을 야기합니다.
Forwarding ( = Bypassing)
이를 해결하고자 Forwarding이라는 것을 사용합니다.
위의 예시에서 add의 결과를 바로 사용하는 것입니다.(register에 저장되기 전에 곧바로)
즉, register에 WB되는 것을 기다리지 않습니다.
이를 위해서 data path에 추가적인 연결이 필요합니다.

Load-Use Data Hazard
lw 명령어에서 data load는 MEM stage에서 수행됩니다.
따라서 register에 write되는 값은 MEM 이후 부터 확정됩니다.
이 때문에 바로 앞의 instruction이 lw instruction인 경우 한 cycle stall이 필요합니다.
ex) lw $s0, 20($t1)
이러한 명령어에서는 20($t1)의 주소를 ALU에서 계산하고 그 주소를 토대로 MEM에 접근합니다.
그 곳의 값을 $s0에 load 합니다.
따라서 최대한 줄이려고 해도(register에서 WB전에 빼오려고 해도) MEM에 접근 이후에나 원하는 값을 알 수 있습니다.
최대한 줄여도 1 cycle의 stall이 발생합니다.

Code Scheduling to Avoid Stalls
code의 schedule을 바꿈으로써 stall을 피하는 것입니다.
물론 명령어에 필요한 값들이 변하지 않아서 순서를 바꿀 수 있는 경우에, 즉, 바꿔도 상관없는 명령어를 이용합니다.
ex) A = B + E; C = B + F;

A의 기본주소는 $t0에 있습니다.
왼쪽이 원래 code이고 오른쪽이 순서를 바꾼 code입니다.
원래의 code에서 add $t3, $t1, $t2에서 $t2의 값을 알려면, 4($t0) 때문에 (MEM 직후까지) forwarding을 해도,
1개의 stall이 발생합니다.
원래의 code에서 add $t5, $t1, $t4에서 $t4의 값을 알려면, 8($t0) 때문에 (MEM 직후까지) forwarding을 해도,
1개의 stall이 발생합니다.
원래의 code는 RAW로 data dependency가 발생합니다.
첫 stall부분에서 차라리 lw $t4, 8($t0)를 당겨와서(그동안 이 명령어에 이용되는 값은 변하지 않기 때문) 미리 처리
해줍니다.
$t4를 미리 준비해놔서, 두번째 stall도 같이 사라집니다.
code의 양이 줄어드는 것이 아니라 pipeline에서 발생하는 지연현상을 줄이는 것입니다.
Control Hazards
control hazard는 control 신호로 인해 프로그램의 flow가 바뀔 수 있는 상황입니다.
그래서 flow가 바뀔지도 모르기 때문에 직후 명령어들이 바로 실행되지 못하는 hazard가 발생합니다.
Branch(분기)는 control의 흐름을 결정합니다.
다음 명령어를 가져오는 것(instruction fetch)은, 분기의 결과(branch outcome)에 의존적입니다.
순차적으로 PC + 4가 될지, beq가 1이 와서 다음 주소 결과를 PC에 담을지 모르기 때문입니다.
pipeline은 항상 올바른 instruction을 fetch하지 않을 수 도있습니다.
branch의 ID stage가 여전히 작업중이라 결과를 못낼 수있기 때문입니다.
MIPS pipeline에서는 branch 명령어의 비교대상(register의 값)을 비교하는 것과 jump대상 주소 계산을 미리
해야 합니다. 그럴 수 있도록 ID stage에 하드웨어를 추가해줍니다.
Stall on Branch
branch에서의 stall을 말합니다.
즉, 다음 instruction을 fetch하기 전에, branch 결과가 결정되는 동안 기다리게 되는 상황을 말합니다.

ID stage가 끝나야 instruction fetch할 수 있으므로 1 cycle stall이 발생합니다.
Branch Prediction
이를 해결하고 branch의 결과를 미리 예측하는 것입니다.
너무 긴 pipeline의 branch의 결과를 미리 알기 어렵습니다. 결과를 최대한 당겨도 여러 cycle의 stall이 발생할 수
있습니다.(stage 수가 많기 때문)
branch결과를 예측하는 것은 믿져야 본전형식입니다.
즉, 만약에 예측이 틀릴 경우에만 stall이 발생하는 것입니다.
MIPS pipeline에서는 branch결과를 not taken(일어나지 않은 것)으로 예측할 수 있습니다.
이렇게 해서 branch 명령어 이후에 instruction fetch를 지연없이 바로 가능합니다.
pridict not taken
conditional branch가 나오면 항상 jump가 일어나지 않는 다고 가정하는 것입니다.
그 다음 instruction을 무조건 fetch합니다.
predict taken
conditional branch가 나오면 항상 jump를 한다고 가정하는 것입니다.
jump할 곳의 instruction을 fetch합니다.
MIPS with Predict Not Taken

위의 경우에는 예측이 맞는 경우입니다.
beq가 아니라면을 가정하여 연속된 (PC + 4) instruction을 바로 가져와줍니다.
아래 경우는 예측이 틀린 경우입니다.
1 cycle stall이 발생하고 맞는 instruction을 새로 가져옵니다.
More-Realistic Branch Prediction
좀더 현실적은 branch prediction방식입니다. 2가지가 있습니다.
1. Static branch prediction
전형적인 branch동작에 기인합니다.
고정적이고 정확도가 떨어집니다.
2. Dynamic branch prediction
하드웨어가 실제의 branch동작을 측정합니다.
예를 들어 각 branch의 최근 history를 기록합니다.
미래의 동작은 그동안의 경향을 따를 것으로 가정하는 것입니다.
그게 틀린다면 당연히 그때는 stall이 발생하고 re-fetching이 일어납니다.
history는 잘되든 못되든 항상 기록될 것이고, stall이 발생하면 점차 수정되어 trend도 변할 것입니다.
정확도는 높아지지만, history 기록과 trend 측정에 자원과 시간이 소요됩니다.
최신 processor는 이 방식을 사용합니다.
MIPS Pipelined Datapath

MIPS datapath는 전체적인 신호의 흐름은 left - to - right입니다.
그러나 MEM stage와 WB stage에 right - to -left 신호가 있습니다.
이는 cycle을 형성하기 때문에 문제를 일으킵니다.
MEM stage에서의 cycle은 branch hazard를 일으키고,
WB stage에서의 cycle은 data hazard를 일으킵니다.
Pipeline register

각 stage사이에 regiter들이 필요합니다.
이전 cycle에서 만들어진 정보를 가지고 있어야 하기 때문입니다.
Pipeline Operation
pipeline datapath를 통한 instruction의 cycle-by-cycle(cycle에서 cycle로) 흐름입니다.
- Single-clock-cycle pipeline diagram
single-cycle을 사용하는 pipeline을 보여줍니다.
사용되고 있는 하드웨어 resource를 highlight해서 표시해줍니다.
- multi-clock-cycle diagram
시간 경과에 따라 어떻게 실행되는지(operation) 보여주는 그래프입니다.
우리는 load / store 명령어를 수행하는 single-clock-cycle diagram을 살펴볼것입니다.
IF for Load, Store,...

instruction과 PC + 4를 저장합니다.
ID for Load, Store,...

EX for Load, Store,...

MEM for Load

MEM for Store

WB for Load

pipeline에서 WB은 5번째 stage이며, 이만큼 이미 다른 cycle이 진행되어, register에는 이미 다른 instruction를
해석하고 있을 것입니다. 기존명령어의 $rt가 아니므로 WB를 위해 기존 명령어의 $rt를 보존해야 합니다.
WB for Store는 wb stage에서 강조되는 영역이 없습니다. 따라서 sw의 wb stage는 아무 작업이 일어나지 않습니다.
Corrected Datapath for Load
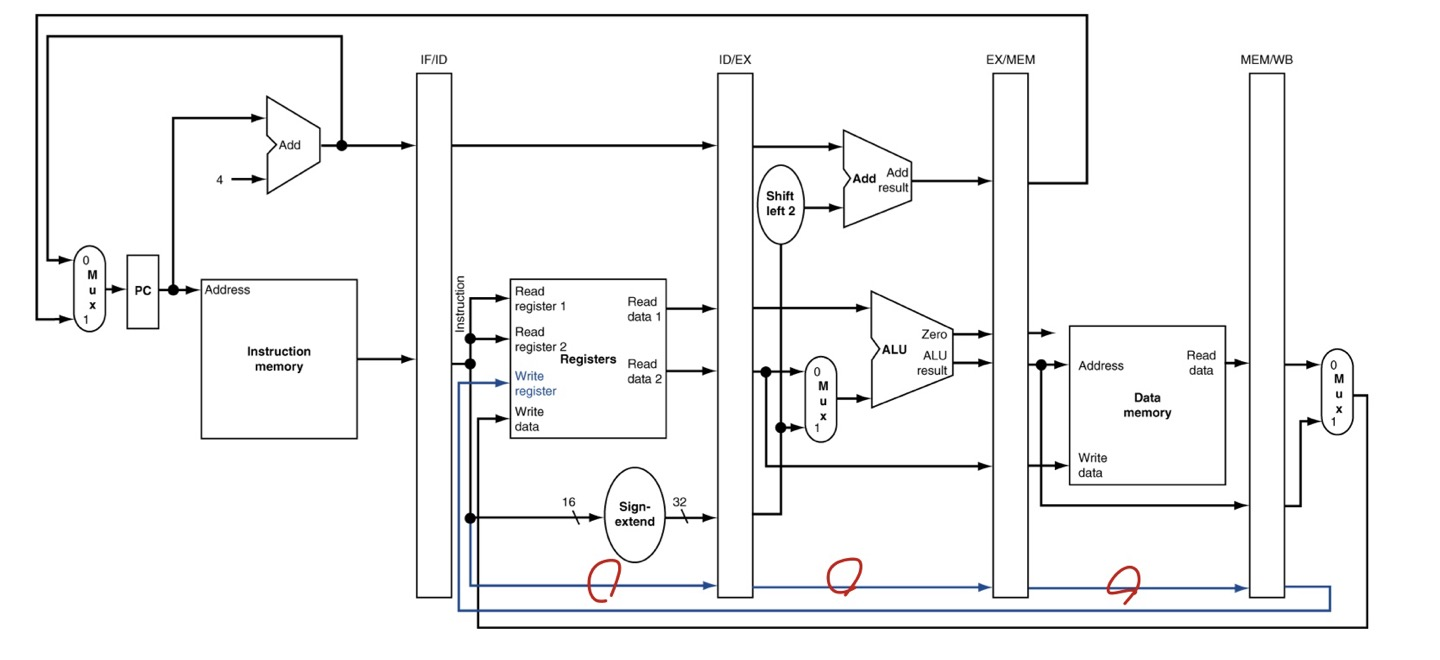
$rt 보존을 위해, 레지스터 이후의 stage간 레지스터(pipeline register)마다 $rt를 넘겨줌으로써, WB에서 다시
레지스터에 전달하여 활용합니다.
Multi-cycle Pipeline Diagram

시간과 명령에 따른 resource(하드웨어 자원)의 사용을 보여줍니다.

전통적인 방식입니다. (보통의 형태)
Single-Cycle Pipeline Diagram

주언진 cycle(특정한 cycle)에서 pipeline의 상태입니다.
특정한 cycle에서 각 stage들이 어떤 명령어를 수행하고 있는, 내부 상태가 어떠지 볼 수 있습니다.
현재 위의 diagram은 위의 multi-cycle-pipeline diagram을 참조하면 CC5의 해당하는 상태입니다.
Pipelined Control (Simplified)

Pipelined Control
control siganl는 instruction으로 부터 파생됩니다. sigle-cycle 처럼

각 stage에 control들이 전달되기 위해, pipeline register에 함께 전달되어 보존되어야 합니다.
single-cycle과는 달리 , ID에서 해석되어 생성된 control signal들이 각 stage에 쓰이기 위해 보존되어야 하므로,
pipeline에서는 ID에서 또 새로운 명령어로 다른 control signal들을 생성할 것이기 때문입니다.

IF, ID stage는 수행할 instruction이 어떤 것인지 모르기 때문에 모든 instruction들이 공통으로 수행됩니다.
그러나 IF에서는 PCSrc, ID에서는 RegWriter라는 control signal이 필요합니다.
이들의 위치는 IF, ID이지만, 실제 그 신호를 주는 것은 MEM과 WB stage에서이다.
즉, 아직 decode 되지 않은 단계에서 control siganl들이 결정되지 않아서 오류나는 것이 아니라,
MEM과 WB stage에서 결정된 것을 받아오는 것입니다.
Control signal들도 pipeline register을 통해서 움직입니다.
- EX
- 4개의 control signal
- ALUSrc : ALU에 input으로 들어갈 source를 결정한다.
- RegDst : 저장할 register number를 결정한다.
- ALUOp(2) : ALU operation을 결정한다.(2bit)
- MEM
- 3개의 control signal
- Branch : branch인지 아닌지 결정한다.(PCSrc)
- MemRead : data memory에 read 할 것인지 결정한다.
- MemWrite : data memory에 write 할 것인지 결정한다.
- WB
- 2개의 contorl signal
- RegWrite : register file에 write 할 것인지 결정한다.
- MemToReg : register file에 write할 것이 memory에서 읽은 data인지, ALU에서 계산된 결과인지 결정한다.
Data Hazards in ALU Instruction

다음과 같은 경우 data hazard가 발생합니다.
이러한 경우 forwarding(bypassing)으로 hazard를 해결가능합니다.
그렇다면 forwarding이 필요할 때는 어떻게 알 수 있을까?
Dependencies & Forwarding

forwarding을 해결가능한 data dependency는 RAW에 의한 의존성입니다.
위의 그림에서 보면 빨간색 선이 forwarding이 일어나는 구간입니다.
실제로 장치는 하나이기 떄문에 오른쪽에서 왼쪽으로 표현해야합니다.
다음 cycle 기준으로 EX/MEM 레지스터가 생성된값($2)을 가지고 있고(sub 명령어는 이미 MEM 단계에 들어감)
다다음 cycle 기준으로는 EX/MEM 레지스터에는 이미 다른 값으로 덮혔지만
MEM/WB 레지스터에 해당 값($2)을 가지고 있습니다. (sub명령어는 WB단계에 들어감)
Detecting the Need to Forward
forwarding이 필요한 순간을 감지합니다.
1. pipeline을 통해 레지스터 번호를 넘겨줍니다(pass)
예를 들어 ID/EX.RegisterRs는 ID/EX 레지스터의 Rs(SourceRegister)를 위한 레지스터 번호입니다.
2. EX stage에서의 ALU 피연산자 레지스터 번호는 다음과 같습니다.(R-format의 ALU)
ID/EX.RegisterRs 와 ID/EX.RegisterRt
3. Data hazard가 발생하는 경우는 아래의 4가지 경우입니다.

1a와 1b
(다음 cycle의 instruction)EX의 Rs/Rt(피연산자들)가 (이전 cycle의 instruction)MEM의 Rd가 같을 때
즉, WB를 위한 대상 레지스터에 값이 쓰이고, 다른 명령어가 그걸 읽어야 하는데, 아직 값이 쓰이지 않기 때문입니다.
1cycle 전의 instruction에서, EX직후에서 계산된 Rd에 쓰일 값을 끌어와서 사용해 해결합니다.
2a와 2b는
(다음 cycle의 instruction)EX의 Rs/Rt(피연산자들)가 (이전 cycle의 instruction)WB의 Rd가 같을 때
마찬가지로 WB를 위한 대상 레지스터에 값이 쓰이고, 다른 명령어가 그걸 읽어야 하는데, 아직 값이 쓰이지
않기 때문입니다.
2cycle 전의 instruction에서, Rd에 쓰일 값이 흐르던 것을 MEM이후에서 끌어와서 사용해 해결합니다.
forwarding은 이전의 instruction에서 레지스터에 늦게 쓰여지는 것들을 해결하는 것이라
(아직 그 값이 안 쓰여져서 문제) pipeline register에 함께 전해지는 control 신호를 살펴보면
RegWrite 신호(마지막 WB에서 register에 쓰이라는 신호)를 찾아볼 수 있을 것입니다.
EX/MEM.RegWrite, MEM/WB.RegWrite
그리고 쓰이는 것이니, 쓰일 대상 레지스터 번호를 나타낼 Rd도 $zero가 아닐 것입니다.
EX/MEM.RegisterRd ≠ 0
MEM/WB.RegisterRd ≠ 0
Forwarding Paths

Forwarding 감지를 위해 현재 cycle의 Rs, Rt(파란색)를 Forwarding Unit(보라색)에 보냅니다.
현재 피연산자 Rs, Rt가 제대로 준비 되었는지가 Data Hazard와 forwarding으로 해결의 핵심이므로,
현재 cycle은 피연산자가 필요한 실행단계인 EX stage입니다.
1cycle전의 instruction과 , 2cycle전의 instruction에서 (둘다 아직 덜 끝난) 쓰여질 목표 레지스터 (Rd)가
현재 Rs나 Rt와 같다면, 레지스터에는 값이 아직 제대로 쓰이지 않았을 것입니다.
이전 cycle의 Rd를 보존하기 위해, Rd를 pipeline register에 넘겨지도록 합니다.(빨간색)
- 1cycle 전의 Rd는 EX/MEM.RegisterRd에
- 2cycle 전의 Rd는 MEM/WB.RegisterRd에
Forwarding Unit(보라색)에서는 현재 cycle의 Rs나 Rt와 , EX/MEM.RegisterRd 혹은 MEM/WB.RegisterRd가
같은 번호를 가지는지 비교합니다.
- EX/MEM.RegisterRd, MEM/WB.RegisterRd 모두 Rs, Rt와 일치하지 않으면 상관없습니다.
- EX/MEM.RegisterRd가 Rs나 Rt와 일치한다면, EX직후인 ALU의 결과값(초록색)을 가져와서 사용합니다.
- MEM/WB.RegisterRd가 Rs나 Rt와 일치한다면, WB로 쓰려는 값(초록색)을 가져와서 사용합니다.
- Forwardig Unit(보라색) 은 control 신호를 3 x 1의 MUX(주황색)들로 보내 ALU의 피연산자로 ID stage 레지스터의 값(일반적인 경우)를 사용할지, forwarding으로 가져온 값을 사용할지 control합니다.
Forwarding Conditions
forwarding 조건입니다.
*EX hazard
ㆍ(EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRs)
→ ForwardA = 10
ㆍ(EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRt)
→ ForwardB = 10
*MEM hazard
ㆍ(MEM/WB.RegWrite & MEM/WB.RegisterRd≠0) & (MEM/WB.RegisterRd == ID/EX.RegisterRs)
→ ForwardA = 01
ㆍ(MEM/WB.RegWrite & MEM/WB.RegisterRd≠0) & (MEM/WB.RegisterRd == ID/EX.RegisterRt)
→ ForwardB = 01
ForwardA = 00 / ForwardB = 00
즉 앞 bit는 EX hazard, 뒤 bit는 MEM hazard 입니다.
Double Data Hazard

위의 순서를 보자
양쪽 hazard가 모두 일어난다면 좀 더 최근것을 사용합니다.
double일 경우에는 MEM hazard의 조건이 변경됩니다.
EX hazard가 아닌 경우에만 MEM hazard forwarding, 즉 double이라면, 항상 EX hazard로 보고 EX 직후의 값
(1cycle 이전의 최근것)을 가져오면 됩니다.
Revised Forwarding Condition
수정된 forwarding 조건입니다.
EX hazard는 그대로 입니다.
MEM hazard
ㆍ(MEM/WB.RegWrite & MEM/WB.RegisterRd≠0)
& not ((EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRs))
& (MEM/WB.RegisterRd == ID/EX.RegisterRs)
→ ForwardA = 01
ㆍ(MEM/WB.RegWrite & MEM/WB.RegisterRd≠0)
& not ((EX/MEM.RegWrite & EX/MEM.RegisterRd≠0) & (EX/MEM.RegisterRd == ID/EX.RegisterRt))
& (MEM/WB.RegisterRd == ID/EX.RegisterRt)
→ ForwardB = 01
Datapath with Forwarding

전체 datapaht 입니다.
Forwarding Unit에서는 이전 cycle들의 Rd 뿐만아리나 EX/MEM.RegWrite, MEM/WB.RegWrite의
control 신호도 forwarding 판별에 필요하므로 이들 역시 pipeline register에서 함께 전달되는 것을 볼 수 있습니다.
Load-Use Data Hazard
lw instruciton에서 data load는 MEM stage에서 수행됩니다.
따라서 register에 write 되는 값은 MEM 이후부터 확정됩니다.
이 때문에 바로 앞의 instruction이 lw instruction인 경우 한 cycle stall이 필요합니다.
이전에 forwarding으로 줄여도 stall을 완전히 없앨 순 없어서 code scheduling했던 것입니다.

현재 cycle은 EX stage이고, 이전 cycle의 값들이라봐야 EX/MEM에 있는 값들이 고작인데
MEM이후의 값은 아직이라 가져올(forwarding)수 없습니다. = stall 발생
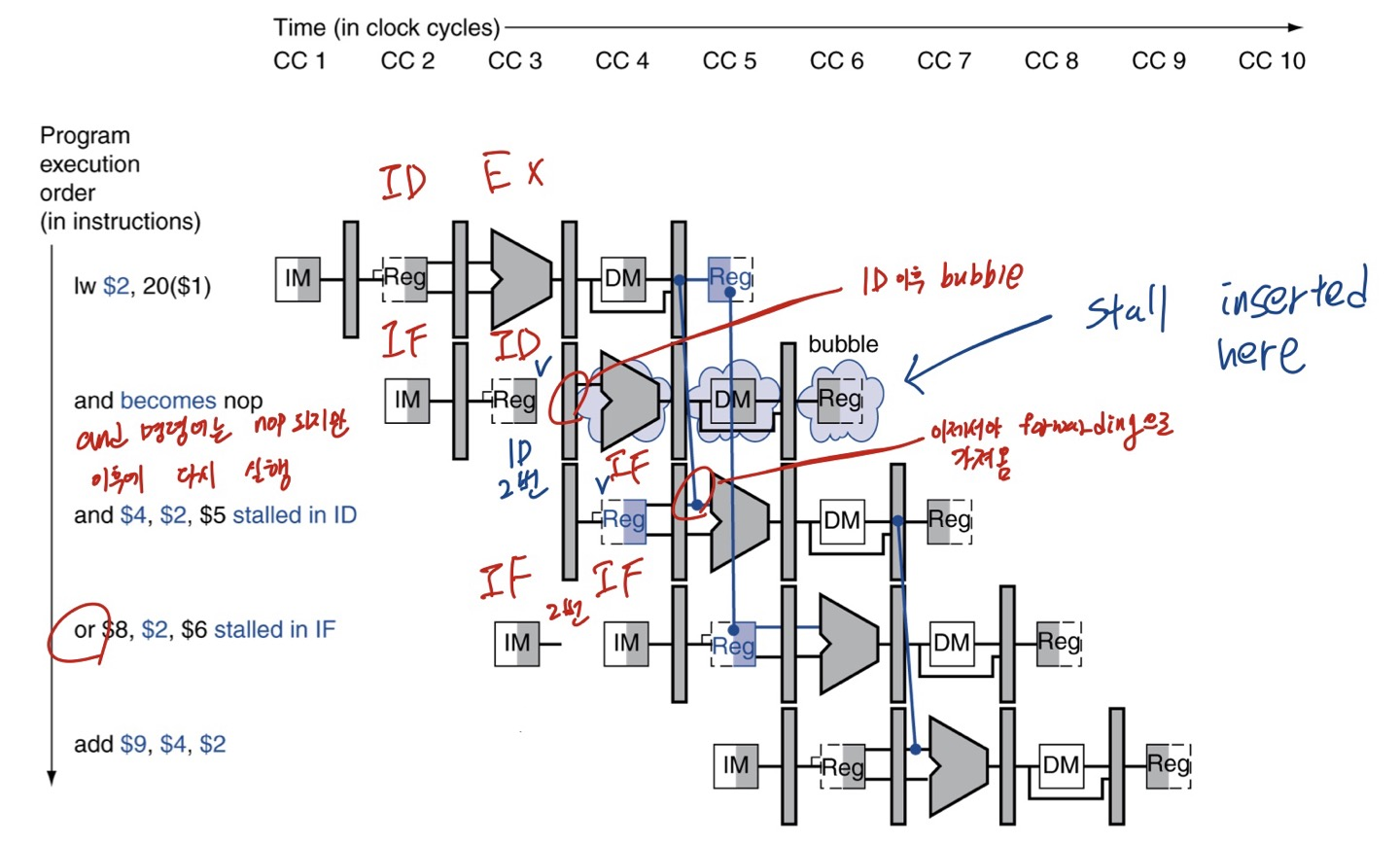
Load-Use Hazard Detection
Load-Use data hazard는 가능한 빨리 detect해서 해결하는 것이 좋습니다.
ID stage 마지막 단계에서부터 현재 instruction이 읽으려고하는 register(rs, rt)를 알 수 있습니다.
따라서 현재 cycle의 ID stage에서 , 향후 instruction에 필요한 부분이 아직 준비되지않았는지 검사합니다.
EX stage에서는 지금 당장 필요한데 부랴부랴 검사하기에는 만약 안돼서 bubble을 삽입하기에 늦습니다.
forwarding은 EX stage에서도 충분히 어떻게든 끌어올 수 있기 때문에 그 때 판별해서 상관없습니다.
ID stage에서 ALU 피연산자 레지스터 번호는 다음과 같습니다.
IF/ID.RegisterRs
IF/ID.RegisterRt
Load-Use Hazard는 다음일 때 발생합니다.
ID/EX.MemRead & [ (ID/EX.RegisterRt == IF/ID.RegisterRs) || (ID/EX.RegisterRt == IF/ID.RegisterRt) ]
이전 cycle의 명령어가 MEMRead 종류라서, MEMRead 신호가 있고
현재 cycle의 명령어의 피연산자(Rs나 Rt)의 번호가
이전 cycle의 Rt의 번호(메모리에서 읽은 값을 넣을 레지스터 번호)와 같을 경우 입니다.
만약 Load-Use hazard가 감지된다면, stall이 발생할 것이고, 해당 부분에 bubble을 삽입시킵니다.
How to Stall the Pipeline
강제로 ID/EX 레지스터의 control 신호값들을 모두 0으로 합니다.(ID 이후 아무것도 동작하지 않도록 합니다.)
EX, MEM, WB는 nop(no-operation)
EX/MEM 포함, 그 이후의 신호들은 그대로 이기 때문에, 이전 cycle의 명령어는 계속 진행됩니다.
한 단계의 bubble이 필요할 뿐입니다.
쉰 다음에 (제대로 다 준비되면) 명령어를 수행해야 하므로 PC와 IF/ID 레지스터의 갱신을 방지합니다.
현재 명령어가 ID stage에서 다시 decode되도록 합니다.
직후 명령어(PC + 4 + 4 가 아닌 PC + 4)가 IF stage에서 다시 fetch되도록 합니다
1cycle의 stall은 이전의 명령어(lw)가 충분히 MEM에서 데이터를 읽어올 수 있도록 해주었습니다.
이제 현재 명령어가 EX stage로 진행해도 됩니다.
Datapath with Hazard Detection
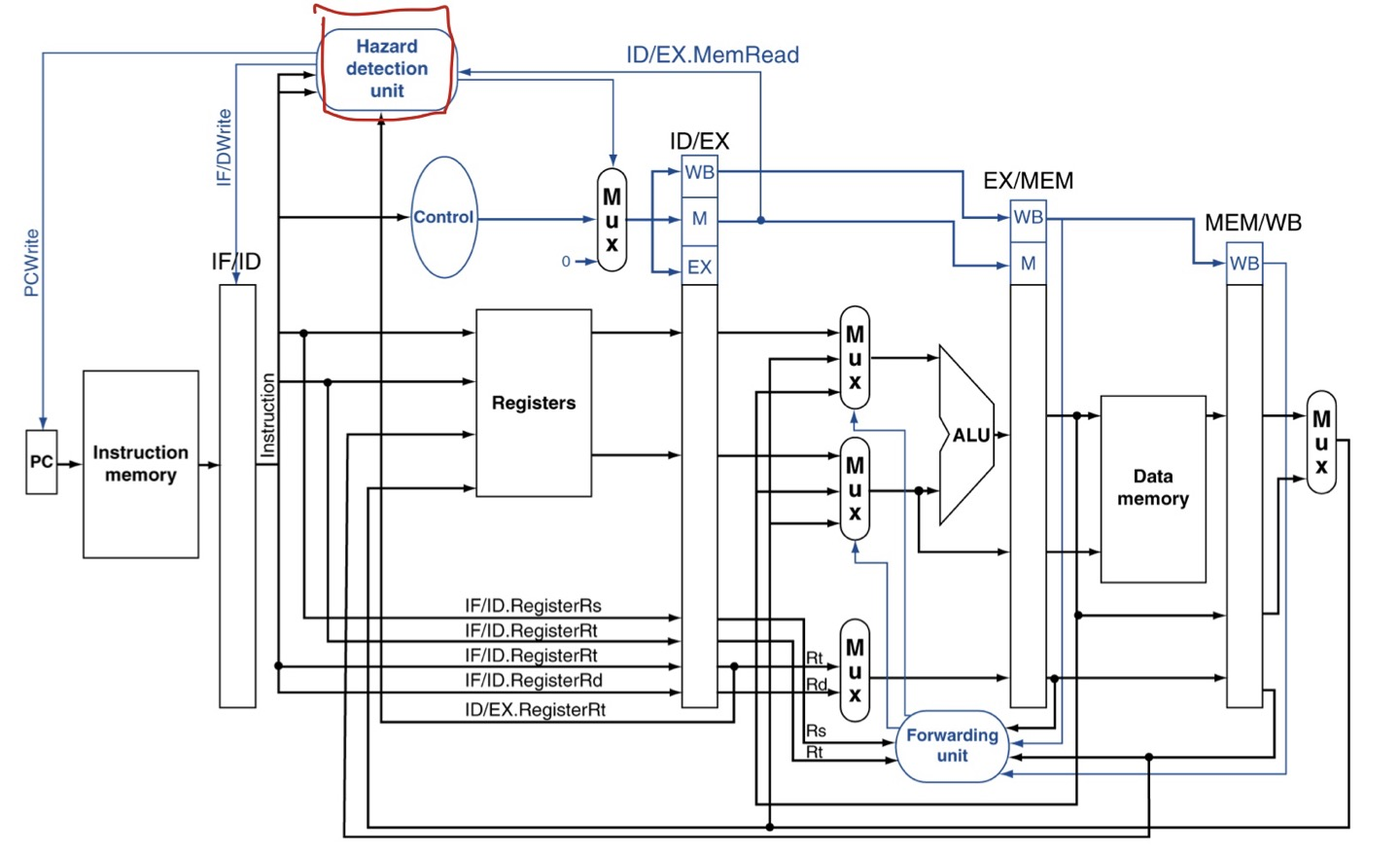
ID stage에서 Hazard detection unit이 추가된 것이 보입니다.
ㆍ여기에 ID/EX.MemRead control 신호가 전달됩니다.(1-cycle 전)
ㆍ그리고 ID/EX 레지스터에의 Rt가,(1-cycle 전)
ㆍIF/ID 레지스터의 Rs, Rt가 전달됩니다.(현재)
이것을 토대로 Load-Use Data hazard를 감지하면,
ㆍID/EX 레지스터에 control신호를 모두 0으로 하여,
1번 bubble이 생기도록(한 층만 건드리니까) 해 줍니다.
ㆍPC에는 PCWrite control신호를 0으로 하여,
PC가 업데이트 되는 것을 방지합니다(직후 명령어는 그대로 다시 fetch).
ㆍIF/IDWrite control신호를 보내 현재 명령어가 다시 decode 될 수 있도록.
Stalls and Performance
stall은 성늘을 저하시킵니다.
하지만 정확한 결과를 얻기 위해서는 꼭 필요합ㄴ디ㅏ.
compiler는 code를 재배치해서 hazard를 피하고 stall을 방지할 수 있습니다.
이를 위해서 compiler는 해당 processor의 pipeline 구조를 정확히 파악해야 합니다.
Branch Hazards
branch의 결과가 MEM 단계에서 결정된다면?
Conditional jump(beq, bne)에서 branch의 여부는 4번째 cycle(MEM stage)에서 판단이 완료됩니다.
따라서 3cycle동안 nop를 수행해야합니다.

control hazard 파트에서, branch 결과를 알기 위해 기다리는 것 대신 "not taken" 으로 가정하여 연속된 명령어를
수행하다고 아니면 그대로, 맞으면 제대로 명령어 가져와서 수행하기로 했었습니다.
만약 결과가 맞으면 그동안 미리 예측하여 수행해둔 명령어는 버려야 합니다.
contorl 신호를 0으로 하여 비워야(flush) 합니다.
Reducing Branch Delay
예측에 실패하더라도 버려지는 단계를 줄여봅니다.
beq/bne를 ID stage에서 끝냄으로써 손실을 최대한 줄일 필요가 있습니다.
branch 결과를 구하는 것을 ID stage에서 할 수 있도록 하드웨어를 옮깁니다.
ID stage에서 끝내면 1cycle로 줄일 수 있습니다.
이를 위해 ID stage에서 adder와 comparator가 필요합니다.
- target address adder(대상 주소를 PC + 4 + offset(address * 4) 해주던 ALU 및 left shift, sign extend)
ID stage에서 target address를 계산합니다.
- register comparator(ALU로 비교해서(빼서) zero인지 확인)
두개의 register의 값이 같은지 계산합니다.
단순히 equality check를 하기 위해서 빼기를 수행하는 것이 아니라 bit by bit comparison을 수행합니다.
ex) branch


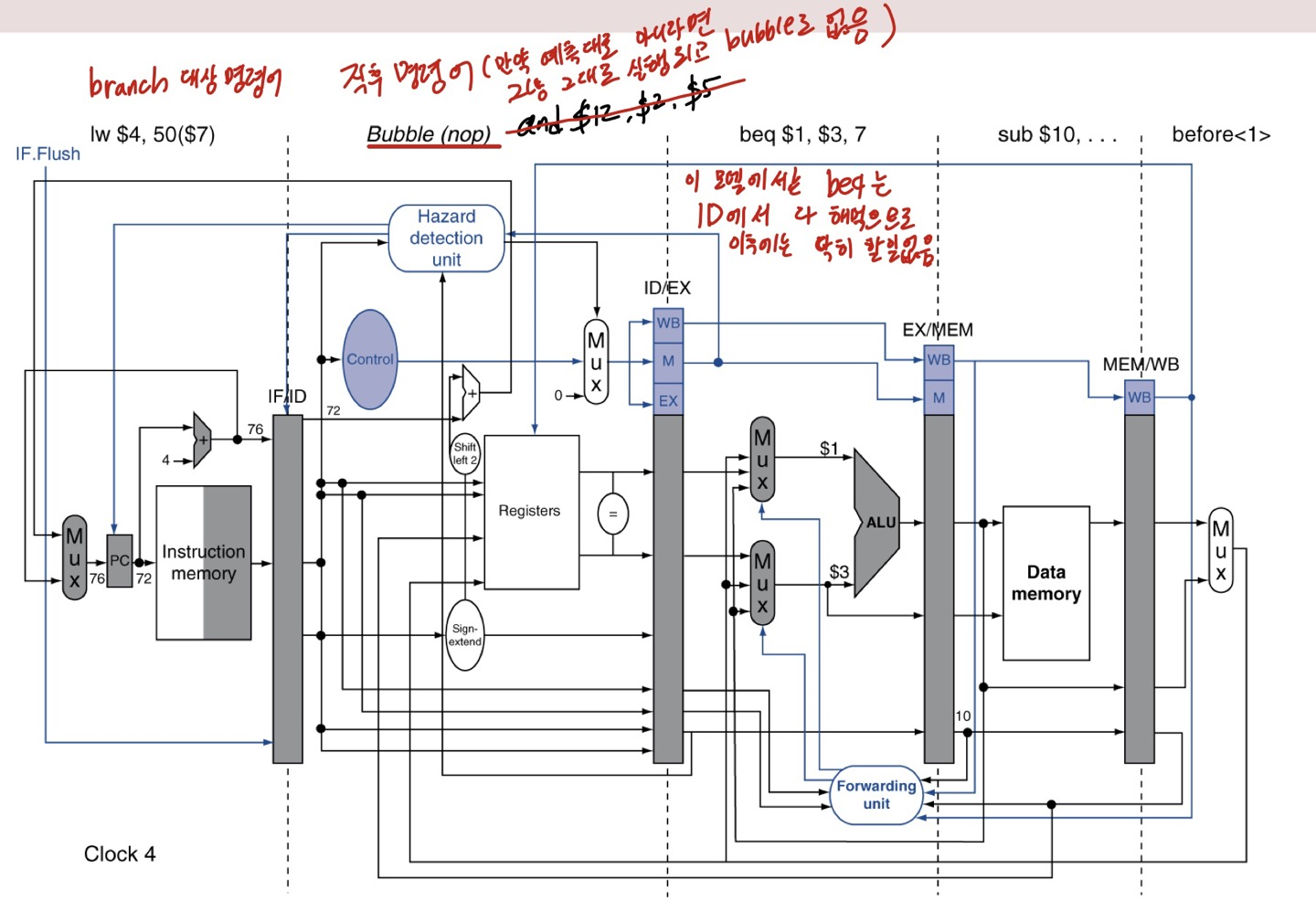
beq는 다음 stage들로 넘어가도 딱히 할 일은 없습니다.
예측이 맞다면 상관없이 다음 명령어 계속 수행합니다.
예측이 틀리고 정말 분기로 이동해야한다면, 분기 대상 주소를 PC에 넣어 해당하는 명령어를 IF 할 수 있도록 하고
직후 명령어(IF였던)는 파기(이제서야 ID로 들어오지만) 합니다.
기존 모델에서는 예측으로 실행해둔 여러 instuction을 버리면서 여러 cycle의 bubble이 발생하지만,
ID stage에서 분기 결과값을 구함으로써, 단 1번(IF 단계였던 직후 명령어)의 bubble만으로 줄일 수 있습니다.
Data Hazards for Branches
만약 branch에서 비교하려는레지스터가 2cycle 전이나 3cycle전의 ALU결과(Rd)라면(아직 레지스터에 안쓰임)
즉, RAW 상황
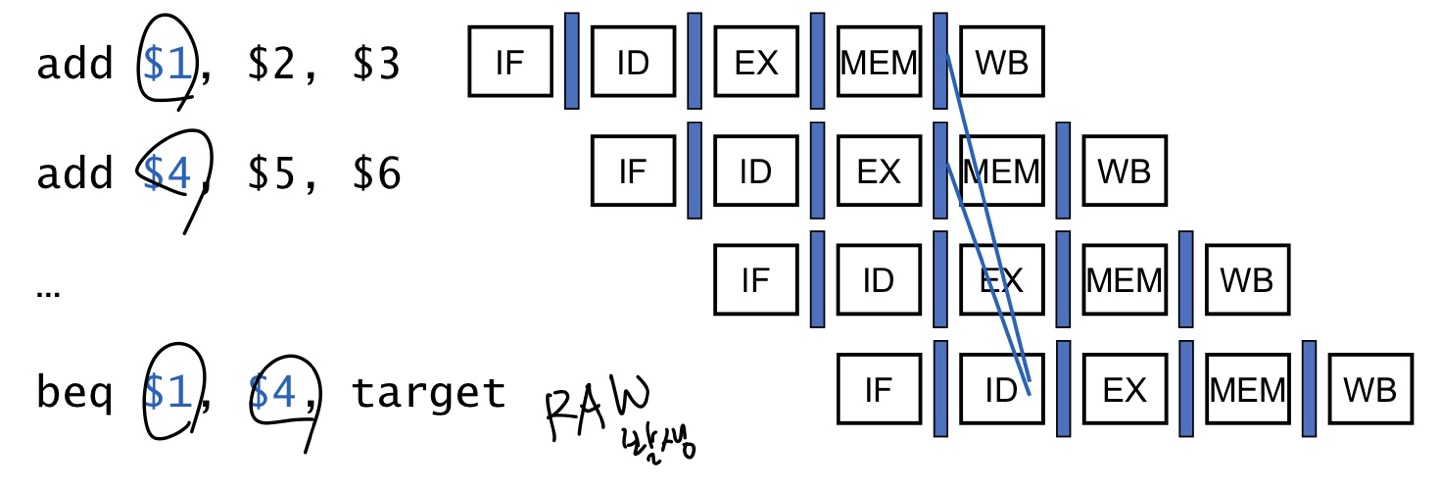
forwarding을 사용해 해결가능합니다.
이전에 본 forwarding은 현재 cycle이 EX stage였습니다. (ALU에 필요한 피연산자)
이제 branch의 비교 ALU는 ID stage에 있기 때문에
1, 2 전 단계가 아닌 2, 3 전 단계에 대해 forwarding할 수 있습니다.
만약 비교하려는 레지스터가 1cycle 전(바로 직전)의 ALU의 instruction의 결과(ID/EX.RegisterRd) 이거나
2cycle 전의 load로 불러온 값을 쓸 레지스터(EX/MEM.RegisterRt)라면, forwarding할 수 없고, stall이 발생합니다.

다음과 같은 경우는 2개의 stall이 생깁니다.

lw뒤에 최소 2개의 cycle이 떨어져 있어야 하지만 바로 beq명령어가 나와
2 stall이 생깁니다.
Dynamic Branch Prediction
deeper and superscalar(stage가 아주많은) pipeline일 수록 branch 패널티(stall)는 더 중요하게 여겨집니다.
stage 수가 많으면 나눠서 일을 하니 속도가 올라가지만 그만큼 stall도 한꺼번에 여러 cycle이 발생할 수 있습니다.
또한 복잡하기 때문에, branch의 결과도 ID stage가 아닌, 좀 더 진행이 된 상태에서 알 수 있게 됩니다.
그러면 예상이 틀렸을 때, 미리 진행한 명령어들을 flush하면서 stall도 더 많이 발생합니다.
Dynamic prediction을 사용하자
branch prediction buffer(branch history table)를 둡니다.
거쳐온 branch instruction의 주소들을 index합니다.
분기 결과를 저장해 둡니다. (not taken, taken)
branch를 수행하려면 테이블을 살펴보고 추론한 예상을 바탕으로, 이러하길 바라면서 진행하기로 합니다.
분기 대상이든, 아니라서 연속으로 진행하든, 예상한 대로의 명령어를 가져와서 진행합니다.
만약 틀렸다면, 예상대로 했던 명령어를 비우고(flush pipeline)예측을 뒤엎습니다.(반대의 명령어를 가져옵니다)
1-Bit Predictor : Shortcoming
1 bit 바로 전의 결과만 사용하는 경우의 단점을 말해봅니다.

inner loop는 처음에는 계속해서 loop를 돌고있으므로 taken으로 설정되었다고 마지막에 loop를 탈출할때
예측 실패(mispredict)가 나타납니다. inner loop를 탈출할때는 not taken으로 설정되어 있습니다.
다시 outer loop를 돌려면 taken이어야 하는 현재 not taken이기 때문에 또 다시 예측 실패(mispredict)가
나타납니다.
따라서 총 2번의 mispredict가 발생하게 됩니다.
이를 1번으로 줄일려면 어떻게 해야할까?
2-Bit Predictor

2번 연속 예측 실패가 나와야 state(taken / not taken)가 바뀝니다.
따라서 위의 예시를 적용하면 총 1번의 예측 실패가 나오게 됩니다.
Calculating the Branch Target
branch 명령어를 위해 기존의 EX stage에서였든, ID stage로 옮겼든,
대상 주소를 계산(rs(PC + 4) + address * 4) 해야합니다.
predictor를 사용하더라도, 여전히 대상 주소를 계산해야합니다.
branch 마다 1cycle이 발생합니다.
branch target buffer
반복될 branch라면 아예 대상 주소(바뀌지 않고 고정된 메모리 주소)를 기억해 두고 재활용하는 방법이있습니다.
대상 주소의 cache
instruction fetch 때 PC에 의해 index됩니다.
만약 예측이 적중하면, 대상 주소의 명령어를 즉시 fetch할 수 있습니다.
이미 buffer에 있는 주소라면, 주소 계산의 overhead가 사라집니다.
Exception and Interrupts
프로그램이 실행중에 예상치 못한 상황 발생으로 변동(예상치 못한 상태 제거)이 필요할 때를 말합니다.
Exception(예외)
CPU 내부에서 발생합니다.
ex) undefined, opcode, overflow, syscall, ....
Interrupt(중단)
외부 I/O cotroller(CPU가 아닌 외부장치, OS 등..) 로부터 발생합니다.
Trap
softward interrupt입니다. syscall 활용, 명령어가 interrupt를 발생합니다.
원래 interrupt는 하드웨어에서 발생시키지만, sw적으로 호출해서 발생시키는 경우입니다.
성능을 희생하지 않고서 이 문제들을 다루는 것은 어렵습니다.
즉, 이 문제들을 다루기 위해서는 어느정도 성능 저하가 발생합니다.
Handling Exceptions
MIPS에서 exception은 System Control Coprecessor(CP0)에 의해 관리됩니다.
문제가 생간 instruction의 PC(instruction의 주소)를 저장합니다.
MIPS에서는 Exception Program Counter(EPC)
문제의 종류(indication)을 저장합니다.
MIPS에서는 Cause Register에 저장합니다.
1-bit로 가정한다면, undefined opcode는 0, overflow는 1처럼 등등
8000 00180(미리정해진)의 메모리 주소에 위치한 handler로 jump합니다.
여기서 EPC와 Cause Register의 값 등을 이용해 처리합니다.
An Alternate Mechanism(좀더 발전된 version)
Vectored Interrupts
원인에 따른 handler 주소가 다르게 정해져 있습니다.
ex)
undefined opcode : C000 0000
over flow : C000 0020
..... : C000 0040
.
.
문제가 발생한 instruction은 다음 중 하나로 진행됩니다.
해당 handler에서 처리하거나 real handler(문제를 제대로 처리할 수 있는)로 jump하여 처리합니다.
Handler Actions
원인을 읽고, 관련된 handler로 넘겨줍니다.(handler jump)
필요한 동작을 결정합니다.
만약 해당 명령어를 재시작 가능하다면 적절한 동작으로 시정하여 동작시킵니다. 또는 EPC를 이용해
원래의 PC로 돌아갈 수 있도록 합니다.
그렇지 않다면 프로그램을 중단합니다.(terminate), EPC, cause, ...등을 이용하여 error를 보고합니다.(report error)
Exceptions in a Pipeline
control hazard의 또 다른 형태로 볼 수 있습니다.
control hazard는 프로그램의 flow가 바뀔지도 몰라서 직후 명령어가 바로 실행될 수 없는 hazard입니다.
exception도 발생하면, 다음의 명령어들이 실행되지 못하고 exception을 처리해야합니다.
ex) add 명령어의 EX stage에서 overflow가 발생했다고 생각해봅니다.
add $1, $2, $1
$1에 잘못된 값이 쓰여지는 것을 막습니다.
이전 명령들은 제대로 완료될 수 있도록 합니다.
add 명령어와 이후 명령어들을 비웁니다.(flush)
EPC와 Cause Register의 값을 setting합니다.
handler로 control권을 넘깁니다.(handler가 처리하도록 jump)
예측 실패한 branch와 유사합니다. 동일한 하드웨어 자원을 많은 부분 함께 사용합니다.
Pipeline with Exceptions

추가된 장치 외에도, 기존의 장치를 많은 부분 함께 활용하여 exception을 처리합니다.
Exception Properties
- 재실행 가능한 명령어에 대한 exception
pipeline은 명령어를 비웁니다.(flush)
handler가 처리 후 , 원래의 instruction으로 돌아갑니다.
- EPC register에 PC 저장
문제가 발생한 instruction을 식별가능합니다.
당연히 실제로는 PC + 4가 저장됩니다.
(handler가 반드시 조정해야합니다. -4를 PC에 넣어줘야 해당 instruction으로 돌아갑니다.)
Exception Example

add 명령어에서 exception이 발생했습니다.

현재 instruction과 이후 instruction들을 모두 flusht 해줍니다.

nop으로 flush(bubble), 그리고 instruction을 모두 flush합니다.
Multiple Exceptions
다중(동시) exception
pipeline은 여러 명령어를 동시에 수행합니다.
그러므로 동시에 여러 exception이 발생할 수 있습니다.
simple approach
더 일찍인 instuction의 exception부터 처리합니다.
뒤이어 오던 instruction들은 함께 flush
첫 단추부터 잘 수정해보자는 precise exception
복잡한 pipeline에서는 cycle마다 여러 명령어를 실행할 수 있습니다.
명령어의 결과 순서가 실행 순서와 같지는 않습니다.(out-of-order)
규칙(명령어 순서대로, precise exceptions)을 지키기가 어렵습니다.
Imprecise Exceptions
pipeline 동작을 멈추고 현 상태를 저장합니다.(exception의 원인(하나 혹은 여럿)도 함께 저장합니다.)
이제 handler가 동작하도록 합니다.
어느 instruction(하나 혹은 여럿)이 exception을 일으켰는지 파악하고,
어떤 것을 처리할지 ,어떤 것을 flush할지 결정합니다.
하드웨어는 간결화(simplify)하되, handler 소프트웨어는 더욱 정교하게(복잡하게)
즉, 소프트웨어적으로 해결합니다.
명령어를 다중 수행할 수 있는 out-of-order pipeline인 복잡한 최신 CPU에서는 사용할 수 없는 방법입니다.
Instruction-Level Parallelism (ILP)
ILP를 향상시키기 위한 2가지 방법이 있습니다.
1. Deeper pipeline(더 여러 stage로 더 깊게)
stage마다 적은 일을 하면 clock cycle은 짧아집니다.
stage를 좀더 세분화 해서 한단계가 적은 일을 하면, 속도는 더 빨라집니다.
한 명령어가 거칠 총 stage 수는 많아지겠지만 더 병렬적으로 처리합니다.
2. Multiple issue(issue = Instruction Fetch)
clock cycle마다 여러 instuction들을 동시에 시작 합니다.
최근에는 CPI(Cycles Per Instruction) < 1 이 되므로, 대신 Instruction Per Cycle(IPC)를 사용합니다.
(한 cycle에 몇개의 instruction을 수행하는지)
Multiple Issue
Static multiple issue
어떤 명령어가 어느 cycle에서 실행할 지 이미 결정이 되어있는것입니다.(runtime 전에 컴파일러가 결정)
컴파일러가 hazard를 감지하고 회피시켜줍니다.
Dynamic multiple issue
CPU가 instruction stream를 시험해보고, 각 cycle에 issue할 instruction들을 고릅니다.
컴파일러가 instruction의 순서를 재배치함으로써 도와줄 수는 있습니다.
runtime 동안에 CPU는 고급기술로 hazard를 해결합니다.
Speculation (추측)
어떤 instruction을 할 것인지 예상하는 것입니다.
우선 할 수 있기만 하면 가능한 빨리 operation을 시작해봅니다.
예상이 맞았는지 확인합니다. 맞았다면, operation을 그대로 진행하여 완수하고
틀렸다면, roll-back하고 올바른 작업을 합니다.
static과 dynamic multiple issue 모두에서 공통적으로 사용하는 형태입니다.
ex)
branch의 결과를 추측
만약 틀렸다면 roll back하고 제대로
load 명령어
특정한 메모리 주소에서 값을 읽어오는 것인데, 값이 변하지 않을 경우가 많아서 미리 읽어둔 값을 그대로
사용하려고 합니다.
그러나 해당 주소의 값이 변했다면 roll back 하고 제대로
Compiler / Hardware Speculation
컴파일러는 instruction들의 순서를 재배치할 수 있습니다.
예를 들어 branch 직전의 load(두 칸 여유를 필요)를 옮긴다던가,,,
예상이 실패하면 fix-up instruction을 끼워 넣어서 복구 시킬 수 있습니다.
하드웨어는 실행할 instruction들을 내다 볼 수 있습니다.(앞서 볼 수있습니다.)
instruciton들이 실제로 수행되어야 하는 게 맞았는지 알기 전까지 buffer가 instruction들을 수행하여 결과를
갖고있다가, 추측이 맞았다면 그대로 가져다가 쓰고, 추측이 실패하면 buffer를 비웁니다.(flush)
Speculation and Exceptions
만약 추측으로 미리 실행하는 instruction에서 exception이 발생한다면 어떻게 될것인가??
미리 실행하는게 도중일 수도, 완료되었을 수도 있고, flush될 수 도 있습니다.
Static speculation
ISA의 도움을 받아, exception들을 지연시킬 수 있습니다.
Dynamic speculation
instruction이 완수될 때까지 exception들을 buffer해둘 수 있습니다.(마치 일어나지 않은 것처럼)
Static Multiple Issue
컴파일러가 instruction들을 issue packets(issue slot)로 그룹화합니다.(함께 issue될 수 있도록)
instruction 그룹은 single cycle(한 cycle 즉, 동시에) issue될 수 있습니다.
해당 명령어들이 필요로 하는 pipeline 자원에 의해 결정됩니다.(묶여집니다)
명령어의 dependency를 고려하고, 각 stage별로 수행되면서도(pipeline 자원) 동시에 수행 가능한 명령어들)
하나의 issue packet을, 하나의 아주 긴 instruction처럼 (64bytes, 128 byte, ...처럼) 생각합니다.
여러개의 동시 작업들로 지정합니다.
=> Very Long Instruction Word(VLIW)
Scheduling Static Multiple Issue
컴파일러는 반드시 모든 /몇몇 hazard를 제거해야합니다.
instruction들의 순서를 재배치하고, issue packet들로 묶습니다.
한 packet은 dependency가 없도록 묶여진 것들입니다.(따라서 동시에 실행 가능)
다른 packet들 사이에는 좀 dependency가 있을 수 있습니다.(ISA에 따라 다릅니다, 컴파일러는 반드시 알아야함)
만약 필요하다면 nop(stall, bubble)을 삽입합니다.
MIPS with Static Dual Issue
2개씩 동시실행
2-issue packets
1 ALU/branch instruction
1 load/store instruction
64-bit 정렬(32 bit * 2)
ALU/branch, 그 후 load/store
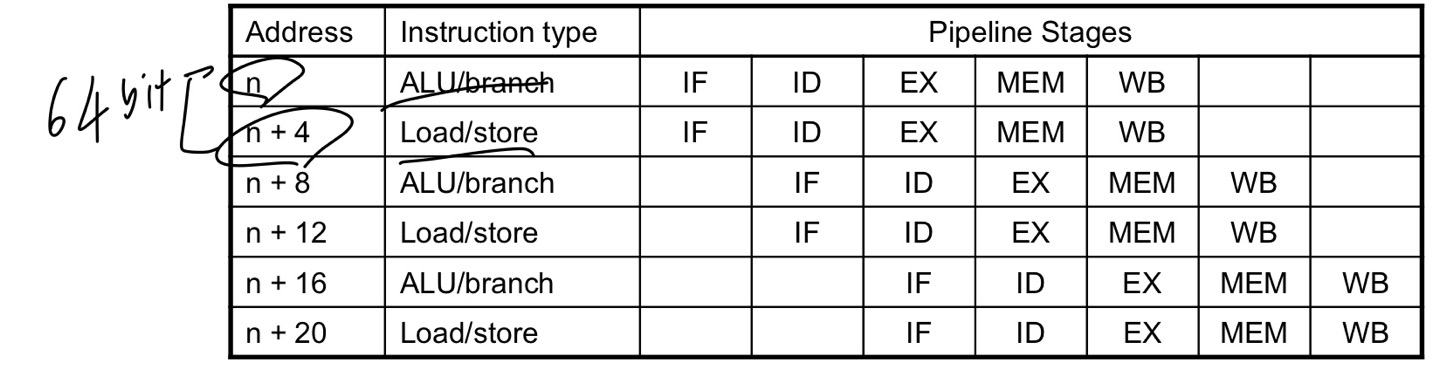
주소의 앞뒤 정렬순서는 ALU/branch 이후 load/store
사용되지 않는 instruction은 nop로 충진(아무리 packet으로 잘 나눠도 bubble이 발생할 수 있기때문입니다.)
MIPS with Static Dual Issue

ALU/branch는 기존 장치를 이용
load/store를 위한 장치와 datapath등이 추가되었습니다.
(여기서는 branch를 ID stage로 당긴 모델이 아닌 예전 모델 기준입니다.)
ALU/branch는 메모리에서 가져오거나 쓰지않으므로, 바로 통과하여 레지스터 WB하는 경로로 수정되었습니다.
Hazards in the Dual-Issue MIPS
병렬적으로 많은 instruction을 동시에 실행하는 형태입니다.
EX data hazard
single-issue에서도 stall을 피하기 위해 forwarding 기법을 사용했었습니다.
이제는 같은 packet에서 ALU결과값을 load/store에 이용하지는 않습니다.

$t0은 dependency가 있으므로, 다른 packet으로 나누었을 것입니다.(같은 타이밍은 불가능하기 때문)
다른 타이밍(다른 packet)에도 여전히 stall이 발생합니다.
(single cycle도 한 단계 늦은 타이밍에도 stall이 발생해 forwarding 했었습니다.)
load-use data hazard
여전히 1 cycle의 지연(latency)을 필요로하지만, 이번에는 2 instruction들이 동시진행합니다.
더욱 적극적인 scheduling이 필요해집니다.
Scheduling Example

lw 명령어에서 $t0는 그 다음 addu 명령어의 dependency입니다. 따라서 lw가 완료되기 전까지 addu명령어를
실행할 수 없으므로 addi라는 아예 관련없는 명령어를 먼저실행합니다.
그 사이에 lw가 완료되므로 addu를 실행하고 이어서 bne와 sw를 실행합니다.
IPC = 5/4 = 1.25 (ch,. peak IPC = 2)
Dynamic Multiple Issue
Superscalar processor
CPU가 각각의 cycle에 어떤 instruction이 issue될 지 결정하는 것입니다.
runtime에 동적으로(컴파일러가 아닌 CPU가 하니 runtime)
CPU가 향후 instruction들을 미리 내다보고, 시험해본 후 , 순서를 정하여 실제로 실행합니다.
structure hazards, data hazards를 방지해줍니다.
컴파일러의 scheduling의 필요성을 줄입니다.(필요에 따라 보조적으로 할 수 는 있습니다.)
그러나 여전히 도움이 될 수 는 있습니다.
전체적으로 code의 제어권은 CPU가 가집니다.
Dynamic Multiple Scheduling
CPU가 stall을 방지하기 위해 instruction들을 순서에 상관없이(out-of-order)실행하도록 허용하는 것입니다.
하지만 레지스터에 결과를 반영(commit)하는 것은 순서대로(in-order) 해야합니다.

addu가 lw때문에 기다리는 동안 sub를 시작할 수 있게 해줍니다.
Dynamically Scheduled CPU

Register Renaming
superscalar processor의 중요한 특징 중 하나입니다.
어떤 instruction이 어떤 레지스터를 사용하는 경우, 원래는 해당 레지스터를 사용해야 하고, 그걸 위해
기다리거나 했지만, 다른 레지스터를 이용가능하도록 하여 그 레지스터를 사용합니다.
instruction의(code) 표기된 레지스터와, 실제 수행의 레지스터가 다를 수 있다는 의미입니다.
reservation station들과 reorder buffer(conmit unit)은 효과적으로 register renaming을 제공합니다.
reservation station에 instruction issue가 진행될 때,
만약 피연산자가 당장 레지스터 뭉치(일반적인 경우)나 reorder buffer에서 값을 사용할 수 있다면,
reservation station으로 복사됩니다.
이제 레지스터는 필요없으므로, 여기에 값이 다시 쓰여져도 됩니다.
아직 피연산자가 준비되지 않았다면, function unit에서 값을 가져와 reservation station으로 제공합니다.
값을 끌어왔으므로, 다른 곳에 필요하지 않다면 레지스터에 값을 쓰지 않아도 됩니다.
(아마 다른 곳도 비슷한 타이밍이면 끌어와서 해결했을 것입니다)
Concluding Remarks
ISA는 datapath와 control 설계에 영향을 줍니다.
*datapath와 control은 ISA 설계에 영향을 줍니다.
(서로에게 영향을 줍니다.)
*pipelining은 parallelism을 이용하여 instruction의 throughput(처리량)을 늘리는 것입니다.
ㆍ같은 시간당 더 많은 instruction을 완수할 수 있게 합니다.
ㆍ하지만 한 instruction의 시간(latency)이 줄어드는 것은 아닙니다.
*Hazards: structural, data, control
*ILP(Instruction-Level Parallelism)에서 multiple issue와 dynamic scheduling
ㆍ의존성(dependency)은 parallelism을 방해합니다(peak 성능보다 실제로 낮게 동작합니다).
ㆍ복잡성(complexity)는 power wall로 향하게합니다(전력소모가 늘어납니다).
'컴퓨터 아키텍쳐' 카테고리의 다른 글
Chapter 5 : Memory Hierarchy (0) 2022.06.15 Logic Design (0) 2022.04.18 Chapter 3 : Arithmetic for Computers (0) 2022.04.11 Chapter 2 : Instructions : Language of the Computer (0) 2022.03.24 Chapter 1 (0) 2022.03.06