-
Introduction데이터 베이스 시스템 2022. 3. 7. 20:27728x90
Purpose of Database System
1) Data redundancy and inconsistency (데이터 중복 및 불일치)
예를 들어 학생이 복수전공(ex 음악, 수학)을 가지고 있는 경우, 해당 학생의 주소 와 전화번호는 음악학과 학생들의
학생 기록으로 구성된 파일과 수학과 학생들의 기록으로 구성된 파일에 나타날 수 있습니다.
이러한 redundancy(이중화)로 인해 저장공간 및 access 비용이 높아집니다.
이는 데이터 inconsistency(불일치)로 이어집니다.
예를 들어 변경된 학생 주소는 음악 부서 기록에는 반영되지만 시스템의 다른 곳에는 반영되지 않을 수 있습니다.
2) Difficulty in accessing data
데이터 베이스가 없으면 자신이 원하고 필요한 데이터를 편리하고 효율적으로 접근할 수 없습니다.
일반적인 사용을 위해서 보다 반응성이 높은 데이터 검색 시스템이 필요합니다.
3) Data isolation
데이터가 다양한 파일로 분산되어 있고 파일 형식이 다를 수 있기 때문에 적절한 데이터를 검색하기 위해
새로운 응용 프로그램을 작성하는 것은 어렵습니다.
4) Integrity problems
예를 들어 학과 별로 계좌 잔고가 0 아래로 절대 떨어지지 않을 것을 요구한다고 가정했을 때 개발자들은
적절한 코드를 추가함으로써 이러한 constraint(제약)들을 시행합니다.
그러나 새로운 constraint들이 추가되면 이를 시행하기 위해 프로그램을 변경하는 것은 어렵습니다.
constraint 조건이 서로 다른 파일의 여러 데이터 항목을 포함하면 문제가 복잡해집니다.
5) Atomicity problems (원자성 문제)
예를 들어 A 계좌에서 B 계좌로 500 달러를 송금하는 프로그램이 있다고 고려해보자
갑자기 시스템 장애가 발생한 경우 A의 500달러는 송금을 하였지만 B의 계좌에는 입금되지 않을 수 있다.
즉, 아예 A의 500달러가 송금되지 않고 B도 500달러는 받지 말아야 정상입니다.
그러나 기존의 파일 처리 시스템에서는 원자성을 보장하기 어렵습니다.
6) Concurrent access by multiple users (동시성 문제)
예를 들어 공유 계좌에 100원 있다고 하자.
두 명의 사용자가 동시에 50원을 인출하려고 할때 두 명 모두 계좌에 100원 이 있다는 것을 확인합니다.
예견치 못하는 동시성이 발생할 때 기존의 프로그램은 이를 반영하지 못합니다.
7) Security problems
예를 들어 대학에서 급여 담당자는 재무 정보가 있는 데이터베이스의 해당 부분만 보면 됩니다.
학업 기록에 대한 정보는 접근할 필요가 없습니다.
데이터 베이스 시스템은 이러한 문제들을 전부 해결합니다.
View of Data
데이터 베이스 시스템의 주요 목적은 사용자에게 데이터의 abstracion 부분만 제공해 줍니다.
즉, 데이터 저장 및 유지 관리 방법의 특정 세부 사항을 숨깁니다.
Data Model
1) Relational model (관계형 모델)
relational model은 데이터 및 데이터 간의 관계를 나타냅니다.
각 테이블에는 여러개의 열이 있으며 각 열에는 고유한 이름이 있습니다.
relational model은 레코드 기반의 모델인데 데이터 베이스가 여러 유형의 고정 형식 레코드로 구성되기 때문입니다.
가장 널리 사용하는 형태 입니다.
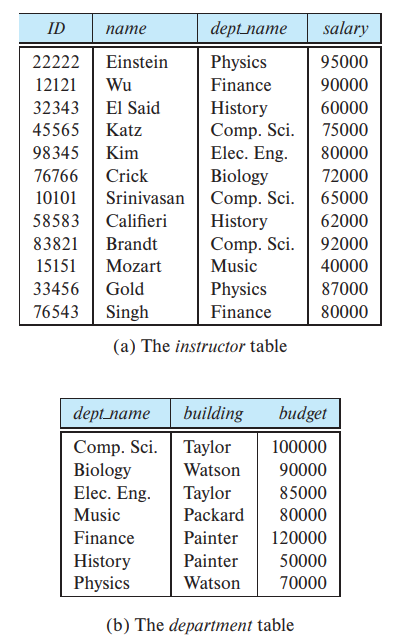
2) Entity-Relationship data model
entity라고 하는 기복 객체의 모음과 이러한 객체가의 관계를 사용합니다.
entity는 현실 세계에서 다른 개체와 구별되는 "사물" 또는 "객체" 입니다.
엔티티 관계형 모델은 데이터베이스 설계에 널리 사용됩니다.
3) Object-based data models (객체 지향 모델)
객체 지향 프로그래밍(c++, java 등)이 관계형 데이터 베이스와 통합된 형태 입니다.
standard는 객체를 관계형 테이블에 저장하기 위해 존재합니다.
데이터 베이스 시스템을 사용하면 데이터 베이스 시스템에 procedure(프로시져)를 저장하고 데이터 베이스 시스템에
의해 실행될 수 있습니다.
이것은 캡슐화, method(메소드), 객체 정체성의 개념으로 관계형 모델을 확장하는 것으로 볼 수 있습니다.
4) Semi-strucured data model (XML)
반 구조화된 데이터 모델은 동일한 유형의 개별 데이터 항목이 서로 다른 속성 집합을 가질 수 있는 데이터 지정을
허용합니다.
이는 앞에서 언급한 데이터 모델(특정 유형의 모든 데이터 항목은 동일한 속성 집합을 가져야함)과는 대조적입니다.
JSON과 XML은 널리 사용되는 반 구조적 데이터 표현입니다.
Data Abstraction
physical level :
가장 낮은 수준의 abstraction입니다. 복잡한 low-level 데이터 구조가 자세히 설명되어 있습니다.
logical level :
다음으로 높은 수준의 abstracion입니다. 데이터 베이스에 저장되는 데이터와 데이터 사이에
존재 하는 관계를 설명합니다. 따라서 logical level은 상대적으로 단순한 소수의 구조 측면에서 전체 데이터 베이스를
설명합니다. 비록 logical level에서 단순한 구조의 구현이 physical level 구조를 포함할 수 있지만 logical level 사용자는
이 복잡성을 인식할 필요가 없습니다. 이를 physical data independence라고 합니다.
데이터베이스에 보관할 정보를 결정해야 하는 데이터베이스 관리자는 logical level을 사용합니다.
view level :
가장 높은 수준의 추상화 view level은 전체 데이터 베이스의 일부만 설명합니다.
비록 logical level이 더 단순한 구조를 사용하지만 큰 데이터 베이스에 저장된 정보의 다양성으로 인해 복잡성을 여전히
남아있습니다.
데이터 베이스 시스템의 많은 사용자들은 이 모든 정보가 필요한 것이 아니라 데이터베이스의 일부에만 access하면
됩니다. view level은 시스템과의 상호작용을 단순화 하기 위해 존재합니다.
시스템은 동일한 데이터 베이스에 대해 많은 보기를 제공할 수 있습니다.
예를 들어 대학교 관리자는 학생의 정보만 볼 수 있습니다. 그들은 교수의 연봉 정보를 볼 수 는 없습니다.

데이터 모델의 중요한 특징은 low-level의 디테일을 사용자 뿐만 아니라 개발자 까지 알 필요가 없습니다.
반면에 데이터베이스 관리자는 디테일한 부분까지 알아야 합니다.
Instances and Schemas
Instance : 특정 순간에 데이터베이스에 저장된 정보의 collection을 instance라고 합니다.
Schema : 데이터베이스의 전반적인 design을 데이터베이스 schema라고 합니다.
코딩으로 설명하면 변수선언은 Schema라고 하고 변수값은 Schema의 instance라고 합니다.
데이터베이스 시스템은 abstraction 수준에 따라 분할된 여러 schema들을 가지고 있습니다.
Logical Schema : 논리적 수준의 데이터베이스를 설계합니다.
예를들어 고객들과 은행들간의 관계 정보가 데이터베이스로 구성됩니다.
Physical Schema : 물리적 수준의 데이터베이스를 설계합니다.
Physical Data Independence
physical schema가 변경 되어도 logical schema는 변경할 필요가 없습니다.
Databases Language
Data Definition Language (DDL)
데이터베이스 schema를 정의 하는데 사용합니다. (CREATE, ALTER, RENAME, DROP 등)

DDL 컴파일러는 data dictionary에다가 table templete의 집합을 생성합니다.
data dictionary는 metadata(data에 관한 data)를 포함합니다.
- 데이터베이스 schema
- Integrity constraints(무결정 제약조건) (Primary key)
- Authorization (권한) (who can access what)
Data Manipulation Language (DML)
데이터베이스의 원하는 데이터를 수정, 삽입, 삭제하는 언어입니다. Query 언어라고도 합니다.
(SELECT, INSERT, UDDATE, DELETE)
DML에는 2가지 유형이 존재합니다.
Procedure DML : 사용자는 필요한 데이터와 해당 데이터를 가져오는 방법을 지정합니다.
Declarative DML : 사용자는 필요한 데이터를 어떻게 가져오는지 제외하고 지정합니다.
declaritve dml이 더 배우기 쉽고 사용을 많이합니다. 또한 non-procedural DML이라고 불립니다.
SQL Query Language
sql 언어는 non-procedural 언어입니다.
예를 들어 'Comp.Sci. 부서의 모든 교수를 찾고싶으면
select name from instructor where dept_name = 'Comp.Sci.'SQL은 Turing machine과 동등한 언어가 아닙니다. 복잡한 함수를 계산할 수 있도록 sql은 보통 high-level 언어로
구성됩니다.
응용프로그램이 데이터베이스에 접근하기 위해서는 일반적으로
embedded sql을 이용해 언어를 확장
sql 쿼리를 데이터베이스로 보낼 수 있는 API(Application Program Interface)를 이용
Database Design
Logical Design : 데이터베이스의 schema 결정
Physical Design : 데이터베이스의 physical layout 결정
Database Engine
데이터베이스는 시스템 전체의 각 책임을 처리하는 module로 분할됩니다.
데이터베이스의 기능은 크게 storage manager, query processor, transaction management로 나눌 수 있습니다.
Storage manager
데이터베이스의 저장된 low-level data와 시스템에 제출된 응용프로그램 및 query간의 interface를 제공하는
프로그램 module입니다.
storage manager는 OS file manager와의 상호작용, 효율적인 data의 저장, 가져오기, update를 합니다.
storage manager는
authorization 과 무결성(integrity)
transaction manager
file manager
buffer manager
들을 포함합니다.
storage manager는 physical system 구현의 일부로 여러 data 구조를 구현합니다.
1) data file : 데이터베이스 자체를 저장
2) data dictionary : 데이터 베이스의 구조, 특히 데이터베이스의 schema에 대한 metadata를 저장
3) Indices : 데이터 항목에 빠르게 access 할 수 있다. 데이터베이스 인덱스는 특정 값을 포함하는 데이터
항목에 대한 포인터를 제공합니다.
Query Processor
query processor는
DDL interpreter(DDL문을 해석하고 data dictionary에 정의를 기록)
DML compiler(쿼리 언어의 DML문을 쿼리 평가 engine이 인식하는 low-level 명령으로 구성된 evaluation plan으로
변환) 즉, query 최적화를 합니다. 수많은 대안들중에 lowest cost evaluation plan을 고릅니다.
Query evaluation engine(DML 컴파일러에 의해 생성된 low-level 명령을 실행)

1. Parsing and translation
(해석과 번역)
2. Optimization(최적화)
3. Evaluation (평가)
Transaction Mnagement
데이터 베이스에서 논리적인 기능을 수행하는 operation의 집합을 Transation이라고 합니다.
시스템의 문제가 생겨도 데이터베이스가 항상 일관적인(정확한) 상태로 남아 있는것을 보장합니다.
Concurrency-control manager : 데이터베이스의 일관성을 보장하기 위해 동시 transaction 간의 상호작용을
control 합니다.
Database and Application Architecture

Database Architecture
Centralized database : shared memory 서버 구조에 적용가능합니다.
shared memory는 여러 CPU를 갖추고 Parallel processing을 이용하지만 모든 CPU가 공통 shared memory에
접근합니다.
Client-sever : 한대의 서버 머신이 다수의 클라이언트 머신을 대신해 작업을 실행합니다.
Parallel database : 메모리를 공유하는 많은 CPU, 공유된 disk, shared nothing
Distributed database: 지리학적 분포, schema/data 이질성
Database Application
데이터베이스 application은 2 or 3개의 파트로 나눌 수 있습니다.
Two-tier architecture : application은 클라이언트 machine에 상주하며, query문을 통해 서버머신의 데이터베이스
시스템 기능을 호출합니다.
Three-tier architecture : 클라이언트 machine은 단지 프론트 엔드로서 기능하며 직접적인 데이터베이스 호출을
포함하지 않습니다. 웹 브라우저와 모바일 어플은 오늘날 가장 일반적으로 사용되는 application client입니다.
client end는 application 서버와 통신합니다. application 서버는 데이터베이스와 통신하여 data에 access합니다.

Database Users and Administarators
Database Users
1) Naïve users (비전문 사용자)
기존에 작성된 웹 또는 어플 등 미리 정의된 사용자 인터페이스를 사용하여 시스템과 통신합니다.
2) Application programmer
응용프로그램을 작성하는 컴퓨터 전문가 입니다. 사용자 인터페이스를 개발 할 수 있습니다.
3) Sophisticated user
프로그램을 작성하지 않고 시스템과 상호작용합니다. 대신 데이터베이스 query언어, 데이터 분석 sw등의 도구를
사용하여 요청을 작성합니다.
Database Administrator
DBMS를 사용하는 주된 이유 중 하나는 데이터와 해당 데이터에 access 하는 프로그램을 모두 중앙에서 control
하기 위함입니다. 이러한 시스템을 중앙에서 control 하는 사람을 데이터베이스 관리자(DBA)라고 합니다.
기능들은 다음과 같습니다.
1) schema 정의
2) storage srtucture 그리고 access 방법 정의
3) schema 및 물리적인 구조를 변경
4) 데이터베이스를 access하기 위한 사용자의 권한을 부여
5) 정기 유지 보수
- 데이터베이스를 remote서버에 정기적으로 백업하여 데이터 손실을 방지
- 통상적인 조작에 충분한 빈 디스크 영역이 있는 것을 확인하고, 필요에 따라서 디스크 영역을 업그레이드
- 데이터베이스에서 실행 중인 작업을 모니터링하고 일부 사용자가 제출한 비용이 많이 드는 작업으로 인해 성능이 저하되지 않도록 보장
'데이터 베이스 시스템' 카테고리의 다른 글
Normalization (0) 2022.05.02 Intermediate SQL (0) 2022.04.16 Introduction to SQL (0) 2022.04.04 Database Design Using the E-R Model (0) 2022.04.02 Intro to Relation Model (0) 2022.03.20