-
Intro to Relation Model데이터 베이스 시스템 2022. 3. 20. 22:17728x90
Structure of Relation Databases

위의 데이터베이스는 instructor 테이블입니다.
Relation Schema and Instance
A1, A2, A3,.....An 들은 attributes(속성)들입니다.
R = (A1, A2, A3,.....An) 은 relation schema입니다.
ex) instructor = (ID, name, dept_name, salary)
Schema R위에 정의된 relation instance r을 r(R)로 표현합니다.
relation r 의 요소 t는 tuple이라고 하며 table내의 행으로 표현합니다.
Attributes
각 attribute에 대해 허용되는 값의 집합을 attribute의 domain이라고 합니다.
속성 값은 쪼개질 수 없습니다.
특별한 값 null은 모든 domain의 멤버입니다.
null값은 많은 작업의 정의에 문제를 일으킵니다.
Relations are Unordered
table에 들어가는 tuple들은 임의적으로 저장됩니다. 즉, 정렬이 되어있지않습니다.
Database Schema
데이터베이스 schema는 데이터베이스의 logical structure입니다.
데이터베이스 instance는 특정한 때에 snapshot처럼 데이터베이스의 data입니다.
instance는 데이터를 추가, 삭제시 달라질 수 있습니다.

Figure 1 Keys
예를 들어 R={ID, name, dept_name, salary} 라고 하고 K가 R의 부분집합이라고 가정하자.
R의 relation instance중 다른 tuple들과 유니크하게 구별되는 tuple의 값을 포함하면 super key라고 합니다.
super key는 하나 이상의 attribute 집합입니다.
예를 들어 위의 데이터베이스 table Figure 1 을 보면 {ID}, {ID, name} 등 attribute 집합에 "ID"가 포함되면
모두 super key 입니다. ID가 다른 tuple들과 유니크하게 구별하게 해주는 attribute이기 때문입니다.
만약 super key K가 최소이면 K는 candidate key입니다. 즉, {ID} 만이 candidate key 입니다.
primary key는 데이터베이스 설계자가 relation내에서 tuple을 식별하는 주요 수단으로 선택한 candidate key를
의미합니다.
classroom (building, room number, capacity)
여기서 primary key는 building과 room number 2개의 attribute로 구성됩니다. 따라서 밑줄 쳐져있습니다.
각각의 attribute만으로는 classroom을 고유하게 식별할 수 없지만 두 attribute 함께라면 classroom을 고유하게
식별할 수 있습니다.
primary key는 attribute값이 변경되지 않거나 매우 드물게 변경되지 않도록 선택해야 합니다.
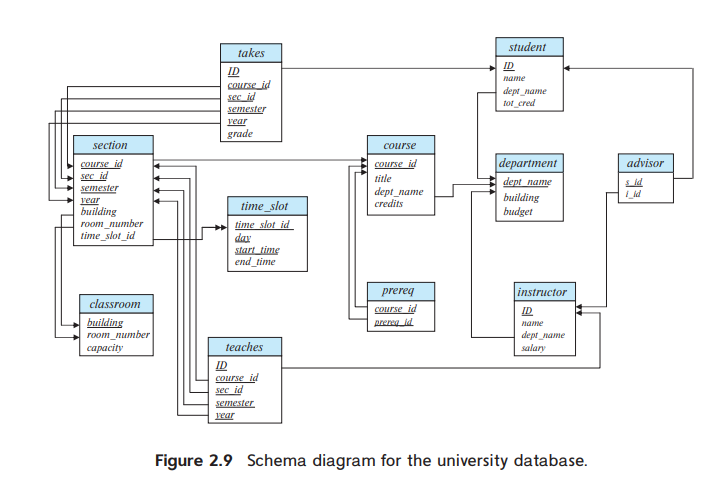
위의 Schema diagram을 봤을 때 instructor table에서 dept_name은 department table의 primary key 입니다.
이때 dept_name을 foreign key라고 합니다. 또한 instructor을 Referencing relation,
department를 Referenced relation이라고 합니다.
즉, 현재 relation에서 key가 다른 relation에서 primary key일때 foreign key라고 합니다.
Foreign key constraint : relation A가 relation B를 referencing 했을 때 그때 B의 key가 primary key여야 합니다.
Referencial integrity constraints : foreign key는 참조할 수 없는 값을 가질 수 없습니다.
예를들어 위의 schema diagram에서 section relation의 attribute인 time_slot_id 는 time_slot relation의 attribute로
존재해야 합니다.
일반적으로 referencial integrity constraint는 referencing relation에 있는 임의의 tuple의 특정 attribute에 나타나는
값이 referenced relation에 있는 적어도 1개의 tuple의 특정 attribute에 나타나는것을 요구합니다.
실제로 foreign key constraints는 referencial integrity constraints의 특별한 경우 입니다.
오늘날은 foreign key constraint를 더 많이 사용합니다.
Relational Query Language
Query language란 사용자가 데이터베이스로부터 정보를 요청할 때 사용하는 언어입니다.
이 언어는 2가지 종류가 있습니다.
1. Procedural (절차적)
2. Non-procedural (비절차적)
사용자가 직접 사용하지는 않지만, Query language의 기초를 이루는 언어를 pure language라고 하여 3가지
종류가 있습니다.
1. Relational algebra (SQL query language의 이론적 기초를 형성)
2. Tuple relational calculus
3. Domain relational calculus
위 3개의 pure language는 동등한 능력을 가집니다.
Relational Algebra
pure language중의 하나에 속하며 , Procedural (절차적)인 언어입니다.
6가지 기본적인 opration(연산)을 가지고 있습니다.

위와 같은 연산자는 2개 또는 그 이상의 relation을 input으로 받아서 연산을 한 후, 그 결과로 새로 만들어진
하나의 relation이 만들어 집니다.
Select Operation
주어진 predicate(설명)을 만족하는 tuple들을 선택합니다.

p는 selection predicate라고 불립니다.
예를들어 instructor relation안에서 dept_name이 Physics인 instructor를 select한다고 하면


다음과 같은 결과가 나옵니다.
일반적으로 selection predicate에 =, ≠, <, ≤, >, ≥을 사용하여 비교할 수 있습니다.
또한

를 사용하여 여러 predicate를 더 큰 predicate로 조합할 수 있습니다.
예를 들어 instructor 내에서 dapt_name이 Physics고 salary가 $90,000보다 큰 instructor를 찾으려면

다음과 같이 쓸 수 있습니다.
selection predicate는 두 attribute 간의 비교를 포함할 수 있습니다.
예를 들면 building 명과 이름이 같은 모든 department를 찾으려면 다음과 같이 입력합니다.

Project Operation
특정 attribute가 생략된 relation를 return하는 연산입니다.

r relation내에서 A1, A2, A3, ...Ak의 attribute가 선택된 relation을 return합니다.
중복되는 행은 제거합니다.
예를 들어 instructor relation에서 ID, name, salary attribute들만 뽑으면


instructor relation이 위와 같이 변합니다.
Composition of Relational Operations
relational-algebra의 결과는 relation이므로 relation-algebra 들은 함께 식으로 표현가능합니다.
예를들어 instructor relaion내에서 Physics department에서 name attribute들만 보고싶으면

위와 같은 식으로 표현가능합니다.

instrutor relation 위 표에서
name Einstein Gold 위와 같은 return 값이 나옵니다.
Project연산의 인수로서 relation의 이름을 지정하는 것 아니라, relation을 평가하는 식을 제시합니다.
Cartesian-Product Operation
두 relation의 결합을 보여줍니다. (X 로 표현)
예를 들어 instructor와 teaches relation 들의 cartesian product 는

위와 같이 표시합니다.


instructor and teaches relation 왼쪽이 instructor이고 오른쪽이 teaches 입니다.
ID attribute는 양쪽 relation에서 나타나기 떄문에 attribute에 attribute의 원래 발산원인 relation의 이름을 부가함으로써
이들의 attribute를 구별합니다.
예를들어
instructor . ID
teaches . ID
이렇게 둘이 구분합니다.

instructor X teaches table 입니다.
instructor relation이 총 12개의 tuple
teaches relation이 총 15개의 tuple
총 12 * 15 개의 tuple이 만들어 졌습니다.
Join Operation
cartesian-product 인 instructor X teaches는 모든 tuple을 조합합니다.
결과 tuple의 대부분은 특정 과정을 가르치지않은 instructor에 대한 정보를 담고 있습니다.
instructor X teaches 의 tuple중에서 강사와 그들이 가르친 코스와 관련된 정보만을 얻기위해 우리는
다음과 같이 쓸 수 있습니다.


총 15개의 tuple만 남게 됩니다.
join 연산을 사용하면 select연산과 caresian-product연산을 single(단일)연산으로 결합할 수 있습니다.
예를들어 r(R) 와 s(S)가 있다고 하면 θ (theta) 는 R ∪ S (R union S) 의 schema안에 있는 attribute에 predicate
입니다.

이러한 join 연산은
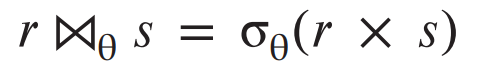
다음과 같이 쓸 수 있습니다.
따라서

위와 같은 식은

위와 같이 쓸 수 있습니다.
Union Operation
두개의 relation의 결합입니다.

위와 같이 표시합니다.
r ∪ s가 유효하기 위해서는 2가지 조건이 있습니다.
1. r과 s는 같은 arity를 가져야 합니다. 즉, attribute의 개수가 같아야 합니다.
2. attribute 도메인이 호환되어야 합니다.
예를 들어 r의 2번째 열은 s의 2번째 열과 같은 type의 값을 가져야 합니다.
EX) (2017년 가을학기의 모든 과목) 혹은 (2019년 봄학기 모든 과목)
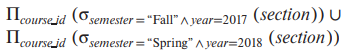

위와 같은 table에서

return 합니다.
Set-Intersection Operation
set-intersection연산을 사용하면 두 input 관계에 있는 tuple을 찾을 수 있습니다.

r, s가 same arity를 가지고 있고 r과 s의 attribute들은 서로 compatible(호환)한다고 가정해보자
예를들어 2017년 가을학기의 모든과목 그리고 2018년 봄학기의 모든과목 중에서 둘다 진행된 과목을 찾고자 한다면

위와 같이 쓸 수 있고
위와 같은 table에서

return 합니다.
Set Difference Operation
어떤 relaiton에 있지만 다른 relation에 없는 tuple을 찾을 수 있습니다.

호환성있는 relation간에 set 차이를 고려해야합니다.
1. r과 s는 무조건 같은 arity여야 합니다.
2. r과 s의 attribute 도메인은 무조건 호환 가능해야 합니다.
예를들어 2017년 가을학기의 모든과목중 2018년 봄학기에는 강의하지 않은 course_id를 모두 구하면

위와 같이 쓸 수 있고
위 table에서 {CS-101, CS-347, PHY-101} - {CS-101, CS-315, CS-319, FIN-201, HIS-351, MU-199}

return 됩니다.
The Assignment Operation
때로는 relational-algebra식을 임시 relation 변수에 할당하여 작성하는 것이 편리합니다.
assignment operation은 ←로 표시하며 프로그래밍 언어처럼 작동합니다.
예를들어 instructor relation내에 "Physics" 와 "Music" department을 찾아라

위와 같이 표현할 수 있습니다.
assignment operation에 의해 query는 일련의 할당에 이어 query의 결과로 값이 표시되는 식으로 이루어진
sequential program 으로 쓰여질 수 있습니다.
The Rename Operation
relaton을 하나이상의 다른이름으로 부를 수 있게 합니다.

의미는 표현식 E를 x라는 이름으로 반환한다는 의미입니다.
만약 relation-algebra E가 n개의 arity를 가지는 경우

위와 같이 쓸 수 있고 표현식 E를 x라는 이름으로 반환하면서 각 attribute는 A1, A2,....An 이름으로 대체됩니다.
예를들어
위의 instructor relation을 기준으로
문제 : 가장 큰 salary를 받는 교수를 찾아라

위와 같이 표현 할 수있습니다.
먼저

위 식의 내용은 instructor의 salary가 다른 instructor의 salary보다 작지 않은 경우를 찾는 것입니다.
(즉, 최댓값이 아닌것)
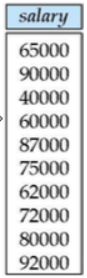
여기서 전체 instructor의 salary를 빼주면

return 됩니다.
문제 : ID가 12121인 강사보다 수입이 많은 강사의 ID와 이름을 찾아라

위와 같이 표현할 수 있습니다.
Equivalent Queries
relational algebra는 꼭 한가지로만 표현할 수 있는것은 아닙니다.
똑같은 return값이여도 다른 operation으로 query문을 작성할 수 있습니다.
예를들어 salary가 90,000이 넘는 instructor중 Physics 부분인 사람을 찾으라고 하면

다음 2개의 query는 똑같은 return값을 가집니다.
그럼 둘중 어느것을 사용하는 것이 더 좋을까?
정답은 Query 1을 사용하는 것이 더 효율적입니다.
왜냐하면 Query 1은 연산을 1번밖에 안하는것에 비해 Query 2는 select operation을 총 2번사용해야합니다.
또 다음 예시로 Physics 부분에서 가르치는 instructor가 가르치는 강의에 대한 정보를 찾으라 하면

다음 2개의 query는 똑같은 return 값을 가집니다.
그럼 둘중 어느것을 사용하는 것이 더 좋을까?
정답은 Query 2를 사용하는 것이 더 효율적입니다.
query 2는 먼저 Physics에 해당하는 insturctor만 selcet하고 그 다음에 instructor ID와 teaches ID가 같은것을
join하였습니다. 우리는 어차피 instructor중 Physics에 해당하는 instructor만 보면 되기때문에
먼저 Physics만 선별을 해준것입니다.
반면에 query 1은 먼저 모든 instructor을 join 해줍니다. 그 다음에 physics에 해당하는 instructor을 찾습니다.
이처럼 데이터베이스 시스템에서는 return값이 같아도 최적화를 해주는 작업이 중요합니다.
'데이터 베이스 시스템' 카테고리의 다른 글
Normalization (0) 2022.05.02 Intermediate SQL (0) 2022.04.16 Introduction to SQL (0) 2022.04.04 Database Design Using the E-R Model (0) 2022.04.02 Introduction (0) 2022.03.07