-
Introduction to SQL데이터 베이스 시스템 2022. 4. 4. 20:14728x90
SQL Parts
sql은 크게 DML과 DDL로 나뉩니다.
DML : 데이터베이스에서 정보를 물을 수 있고, tuple을 삽입, 삭제 및 수정할 수 있는 기능이 있습니다.
integrity : DDL에는 무결정 제약 조건을 지정하는 명령이 포함되어 있습니다.
View definition : DDL에는 view를 정의하는 명령어가 포함되어 있습니다.
Transaction control : transaction의 시작과 종료를 지정하는 명령어가 포함되어 있습니다.
Embeded SQL and dynamic SQL : 일반적인 프로그래밍 언어에 sql문을 삽입하는 방법을 정의합니다.
Authorization : relation 및 view에 대한 access 권한을 지정하는 명령이 포함되어 있습니다.
Data Definition Language (DDL)
DDL을 사용하면 다음과 같은 relation에 대한 정보를 지정할 수 있습니다.
- 각 relation의 schema
- 각 attribute와 관련된 값의 유형
- 무결성 제약조건
- 각 relation에 대해 유지되는 인덱스 집합
- 각 relation에 대한 보안성과 권한성
- disk에 있는 각 relation의 물리적인 저장 구조
Domain Types in SQL
char(n) : 길이가 n으로 고정된 문자열
varchar(n) : 최대 길이가 n이 가변적인 문자열
ex) n = 5 이고 문자열이 "adv" 라면 char(5) = adv_ _ 입니다. char은 무조건 길이가 n으로 고정되기 때문에
문자열의 길이가 부족하면 뒤에 space를 붙여 n으로 만들어줍니다.
varchar(5) = adv 입니다.
int : 정수
smallint : 작은 정수
numeric(p, d) : 전체 자리수가 p 이고 소숫점 아리자리수가 d인 실수 입니다.
ex) numeric(3, 1)이면 44.5(o), 3.12(x), 444.5(x)
real, double, precision
float(n) : 사용자가 지정한 정밀도가 n자리 이상인 부동 소수점
Create Table Construct
create table r (A1 D1, A2 D2, ... , An Dn, (integrity-constraint1), ... , (integrity-constraintk));처음에 table을 생성하는 명령어는 create table입니다.
r은 relation의 이름입니다.
각각의 A1, A2, ...An은 r의 schema에 있는 attribure의 이름
D1, D2, ...Dn은 A1, A2, ....An의 data type입니다.
ex)
create table instructor ( ID char(5), name varchar(20), dept_name varchar(20), salary nuumeric(8,2));Integrity Constraints in Create Table
무결성 제약조건의 종류
- primary key (A1, A2, ....An)
- foreign key (Am, ..., An) references r
- not NULL
등등
create table instructor ( ID char(5), name varchar(20) not null, dept_name varchar(20), salary nuumeric(8,2), primary key(ID), foreign key(dept_name) references department);SQL는 데이터베이스에서 일어난 Update가 무결성제약조건에 위반하지 않게 막아줍니다.
ex) relation 정의에 대한 여러가지 예시
create table student ( ID varchar(5), name varchar(20) not null, dept_name varchar(20), tot_cred numeric(3,0), primary key (ID), foreign key (dept_name) references department);create table takes ( ID varchar(5), course_id varchar(8), sec_id varchar(8), semester varchar(6), year numeric(4,0), grade varchar(2), primary key (ID, course_id, sec_id, semester, year) , foreign key (ID) references student, foreign key (course_id, sec_id, semester, year) references section) ;create table course ( course_id varchar(8), title varchar(50), dept_name varchar(20), credits numeric(2,0), primary key (course_id), foreign key (dept_name) references department) ;Updates to tables
Insert
relation에 tuple을 집어넣습니다. ex('10211', 'Smith', 'Biology', 66000) 삽입
Delete
relaiton에 있는 모든 tuple을 지웁니다.
Drop Table
relation 자체를 지웁니다 (relation의 tuple을 모두 삭제한후 drop가능)
Alter (주의해서 사용해야함)
데이터베이스의 schema를 바꿉니다.
1) alter table r add A D
attribute를 추가하는 것입니다.
A는 relation r에 추가된 attribute의 이름이고 D는 A의 domain입니다.
relation에 있는 모든 기존의 tuple은 null이 새 attribute의 값으로 할당 됩니다.
2) alter table r drop A (가급적 사용금지)
attribute를 삭제 합니다.
A는 relation r의 attribute이름입니다.
많은 데이터베이스에서 attribute 삭제가 지원되지 않을 수 있슶니다.
Basic Query Structure
전형적인 SQL query는 아래와 같습니다.
select A1, A2 , ... , An from r1, r2, ... , rm where P;Ai 는 attribute를 나타냅니다.
ri 는 relation을 나타냅니다.
P는 predicate를 나타냅니다. 즉, 조건같은것이라고 생각합니다.
SQL query의 결과값은 항상 relation입니다.
The select Clause
select는 query 결과의 attribute를 나열해서 나타냅니다.
projection operation과 동일합니다.
예를 들어 instructor relation의 모든 instructor 이름을 찾고 싶으면
select name from instructor;
위 SQL에서 name, instructor은 대소문자를 구별안합니다.
NAME = name = Name
SQL은 query결과 뿐 만아니라 relation 안에서의 중복을 허용합니다.
따라서 중복되는 값을 제거하려면 select 뒤에 'distinct'라는 값을 적어줘야합니다.
select distinct dept_name from instructor;반면에 select뒤에 'all'을 입력하면 중복되는 값도 포함해서 모두 보여줍니다.
select all dept_name from instructor;


가장 왼쪽에 있는 것은 select dept_name
가운데는 select distinct dept_name
오른쪽은 select all dept_name
select뒤에 *을 붙여주면 all attribute를 보여줍니다.
select * from instructor;위의 SQL을 적어주면 instructor의 table 전체를 가져옵니다.

select문까지 쓰고 from문을 안쓸 수 있습니다.
select '437'
437의 값을 갖는 열과 한개의 행으로 이루어진 table이 나옵니다.
열에다가 이름을 설정할 수 있습니다.
열의 이름을 FOO라고 하고 싶다면 as문을 사용합니다.
select '437' as FOO
select 'A' from instructor위의 SQL을 입력하면 한개의 열과 instructor table이 가지고 있는 행의 개수만큼 A가 채워집니다.

select문에는 +, -, *, / 와 같은 연산자를 쓸 수 있습니다.
select ID, name, salary/12 from instructor;
as문을 써서 salary/12를 monthly_salary로 바꿀 수 있습니다.
select ID, name, salary/12 as monthly_salary from instructor
The where Clause
where절은 조건을 지정해줍니다.
relational algebra에서 selection predicate와 동일합니다.
depart_name이 Comp. Sci인 모든 instructor을 찾고싶으면 (Comp. Sci. 학과에 있는 모든 교수이름)
select name from instructor where dept_name = 'Comp. Sci';
SQL에는 논리연산자도 이용가능합니다. and, or, not
또한 비교연산자도 이용가능합니다. <, <=, >, >=, =, <>(같지 않다)
Comp. Sci. 학과에 연봉이 70000이 넘는 교수이름을 알고싶으면
select name from instructor where dept_name = 'Comp. Sci.' and salary>70000;
The from Clause
from 뒤에 여러개의 relation이 올 경우, 이는 relation algebra의 Cartesian product와 같습니다.
instructor X teaches를 구하고 싶으면
select * from instructor, teaches;
.
.
.
이 때 공통적인 attribute가 있는 경우 (relation name.attribute name)으로 이름이 재정의 됩니다.
위에서는 instructor와 teach relation에 공통적으로 ID가 겹칩니다.
ex) instructor.ID
Cartesian priduct는 직접쓰기에는 별로지만 where clause와 함께 쓰면 굉장히 유용합니다.
( = join operation)
Example
1) 현재 실제로 course를 가르치고 있는 교수자의 이름과 그 course_id를 찾기
select name, course_id from instructor, teaches where instructor.ID = teaches.ID;
2) Music department에 있고, 현재 실제로 가르치고 있는 교수자의 이름과 그 course_id찾기
select name,course_id from instructor,teaches where instructor.ID = teaches.ID and instructor.dept_name = 'Music'
The Rename Operation
SQL은 relation과 attribute를 as 구문을 이용해서 이름을 재정의 할 수 있습니다.
old-name as new-name
ex) 컴퓨터 학과 교수보다 더 높은 연봉을 받는 모든 교수의 이름을 찾아라
select distinct T.name from instructor as T, instructor as S where T.salary > S.salary and S.dept_name = 'Comp.Sci.`ex) loan_number를 loan_id로 개명하여 고객의 이름, loan number, amount를 구하는 질의는 다음과 같습니다.
select customer_name, loan_amount as loan_id, amount from borrower, loan where borrower.loan_number = loan.loan_numberas는 생략이 가능합니다.
ex) instructor as T == instructor T
Self Join Example

relation E 입니다.
여기서 "BoB"의 supervisor의 supervisor의 supervisor의 ... 를 찾으라 하면 (BoB -> Alice -> David)
select * from E as e1, E as e2 where e1.supervisor = e2.supervisorString Operations
SQL은 문자열을 비교하는 string-matching operator를 가지고 있습니다.
문자열 패턴은 2가지 특수 문자를 사용하여 나타냅니다.
1. 퍼센트(%) : 이것은 길이가 0이상인 모든 substring에 해당됩니다.
2. 언더스코어(_) : 이것은 하나의 문자에 해당됩니다.
패턴은 대소문자를 구분합니다.
ex) 모든 교수중에 이름에 "dar"이 들어가는 이름을 모두 찾아라
select name from instructor where name like '%dar%';만약 substring이 "100%" 라면
like '100\%' escape '\'라고 작성합니다.
만약 문자열이 처음에 Intro로 시작한다면
where name like 'Intro%'라고 작성합니다.
만약 3개의 문자로 이루어진 문자열을 찾고 싶다면
where name like '_ _ _'라고 작성합니다.
만약 3개 문자 이상의 문자열을 찾고 싶다면
where name like '_ _ _%'라고 작성합니다.
SQL은 다음과 같은 다양한 string operation을 제공합니다.
concatenation (using ||) : 이어 붙이기
converting from upper to lower case : 대문자에서 소문자로 변환, 또는 그 반대
finding string length, extracting substring etc : 문자열 길이 찾기, substring 추출 등
Ordering the Display of Tuples
예를 들어 교수들의 이름을 알파벳 순서로 정렬하고 싶을 경우 order by 를 쓸 수 있습니다.
select distinct name from instructor order by name
또한 내림차순(desc), 오름차순(asc)도 지정 가능합니다. (기본적으로 오름차순으로 되있습니다)
select distinct name from instructor order by name desc
또한 여러 attribute를 기준으로 정렬할 수 있습니다.
select distinct name from instructor order by dept_name, name
Where Clause Predicates
SQL에서는 where절에서 사용할 수 있는 비교 연산자로서 between을 포함하고 있습니다.
이 절은 어떤 값보다 크거나 같고, 다른 어떤 값보다 작거나 같다는 것을 나타냅니다.
예를들어 90000달러 이상 100000달러 이하인 loan amount를 갖는 모든 loan을 구하려고 하면
select name from instructor where salary between 90000 and 100000
Tuple comparison
예를 들어 instructor ID가 teaches ID와 같고 dept_name이 Biology인 교수의 이름과 course_id를 구하려고하면
select name, course_id from instructor, teaches where (instructor.ID, dept_name)=(teaches.ID, 'Biology');
Set Operations
Union (합집합)
ex) 2017년 가을 학기와 2018년 봄학기에 열린 모든 강의들의 강의 번호 구하기
(select course_id from section where semester='Fall' and year = 2017) union (select course_id from section where semester='Spring' and year = 2018);
Intersect (교집합)
2017년 가을학기 그리고 2018년 봄학기에 열린 강의들의 강의 번호 구하기
(select course_id from section where semester='Fall' and year = 2017) intersect (select course_id from section where semester='Spring' and year = 2018);
Except (차집합)
2017년 가을 학기에 열리고 2018년 봄학기에 안 열린 강의들의 강의 번호 구하기
(select course_id from section where semester='Fall' and year = 2017) except (select course_id from section where semester='Spring' and year = 2018);
기본적으로 Set Operation들은 중복을 제거합니다.
만약 중복을 보존하고 싶으면
union all
intersect all
except all
을 사용하면 됩니다.
Null Values
tuple들을 전부 null 값으로 채울 수 있습니다.
null은 알 수 없는 unknown 값 또는 존재하지 않는 값을 나타냅니다.
null을 포함하는 산술식의 결과는 항상 null입니다. ex(5 + null = null)
is null을 활용해 null 값인지를 체크할 수 있습니다.
ex) 모든 교수중에 salary가 null인 것을 찾아라
select name from instructor where salary is null;is not null은 null 값이 아닐 경우 true입니다.
null 값이 비교 구문에 포함될 경우 unknown을 return합니다.
ex) 5 < null 또는 null <> null 또는 null = null (모두 null을 return 합니다.)
where의 술어부분에서는 Boolean operation이 작동하므로 unknown이 끼어있을 때 어떻게 할지 결정해야합니다.
and : (true and unknown) = unknown
(false and unknown) = false
(unknown and unknown) = unknown
or : (unknown or true) = true
(unknown or false) = unknown
(unknown or unknown) = unknown
where 구문에서 unknown으로 판명될 경우 false로 취급합니다.
Aggregate Functions
집계 함수
SQL에서는 다음과 같은 함수들을 제공합니다.
avg : 평균값
min : 최솟값
max : 최댓값
sum : 합
count : (number of values) 개수 세기
ex) 컴퓨터학과 교수의 평균 급여
select avg(salary) from instructor where dept_name = 'Comp. Sci.';
ex) 2018년 봄학기에 가르친 모든 교수들의 수
select count (distinct ID) from teaches where semester = 'Spring' and year=2018;
ex) course relation안에 있는 모든 tuple의 개수
select count (*) from course;
group by : 동일한 값끼리 묶어서 보여줍니다.
ex) 각 학과의 교수님들의 평균 salary
select dept_name, avg (salary) as avg_salary from instructor group by dept_name;

왼쪽의 table로 부터 오른쪽 table의 결과가 return됩니다.
group by 함수를 사용하려면 반드시 select에 존재해야 합니다.
ex) 다음은 error query입니다.
select dept_name, ID, avg(salary) from instructor group by dept_name;select문에 ID가 들어가게 되면 하나의 속성으로 통일 불가
having
예를 들어 평균 salary가 42000보다 큰 모든 과를 찾아서 이름과 평균 salary을 보여주어라
select dept_name, avg (salary) as avg_salary from instructor group by dept_name having avg (salary) > 42000;
대충 보면 where과 사용이 매우 비슷하지만, where절의 술어는 group을 형성하기 전에 적용되고,
having 절의 술어는 그룹을 형성한 이후 적용됩니다.
만약 where절을 썼다면 전체 과 교수님의 평균에 대해 계산했을 것입니다.
having 절을 썼기 떄문에, 먼저 그룹화 한 이후 그룹 평군에 대해 계산하여 보여줄 수 있는것입니다.
Nested Subqueries
중첩 query입니다.
즉, 다른 쿼리 내에 쿼리를 중첩해서 쓰는것입니다.
subquery란 다른 쿼리 안에 중첩되어 있는 select-from-where 구문을 말합니다.
기존 기본 query
select A1, A2, ... ,An from r1, r2, ... , rm where P;From clause : ri는 어느 valid subquery로도 대체될 수 있습니다.
Where clause : P는 다음과 같은 형식으로 대체될 수 있습니다.
B<operation>(subquery) : B는 attribute이고 <operation>은 나중에 선언된것입니다.
Select clause : Ai는 어떤 single value를 만들어내는 subquery라면 대체될 수 있습니다.
Set Membership
ex) 2017 가을과 2018년 봄에 둘다 열린 course 찾아라 (in)
select distinct course_id from section where semester = 'Fall' and year=2017 and course_id in (select course_id from section where semester= 'Spring' and year = 2018);
Union을 사용하면 다음과 같습니다.
(select course_id from section where sem='Fall' and year = 2017) union (select course_id from section where sem='Spring' and year = 2018);
ex) 2017년 가을에는 열렸지만 2018년 봄에는 열리지 않는 course 찾아라 (not in)
select distinct course_id from section where semester = 'Fall' and year=2017 and course_id not in (select course_id from section where semester='Spring' and year = 2018);
except(차집합)을 사용하면 다음과 같습니다.
(select course_id from section where sem='Fall' and year = 2017) except (select course_id from section where sem='Spring' and year = 2018);
ex) 교수의 이름이 "Mozart"도 아니고 "Einstein"도 아닌 instructor의 이름 찾기 (not in)
select distinct name from instructor where name not in ('Morzart', 'Einstein');
ex) ID 10101을 가진 교수한테 강의를 듣는 학생의 총 수를 찾아라 (in)
select count (distinct ID) from takes where (course_id, sec_id, semester, year) in (select course_id, sec_id, semester, year from teaches where teaches.ID=10101);
ID가 10101인 교수의 수업 id, 분반, 학기, 년도를 가져와서 그 해당 수업을 듣는 학생의 ID를 세는 방식입니다.
위의 query들은 훨씬 더 간단한 방법으로 작성할 수 있습니다.
위의 공식은 단순히 SQL의 기능을 설명하기 위한것입니다.
Set Comparison - "some" Clause
some (= or)
ex) biology 학과에 있는 교수 중 아무나 한 명보다 자신의 salary가 더 큰 사람의 이름을 구하라
즉, biology 학과에 있는 교수의 salary 중 가장 낮은 salary보다 자신의 salary가 큰 사람
select distinct T.name from instructor as T, instructor as S where T.salary > S.salary and S.dept_name = 'Biology';
some 구문을 사용해 똑같이 구현가능합니다.
select name from instructor where salary > some (select salary from instructor where dept_name='Biology');F<comp> some r => ex) 5 < some 0, 5, 6 = true
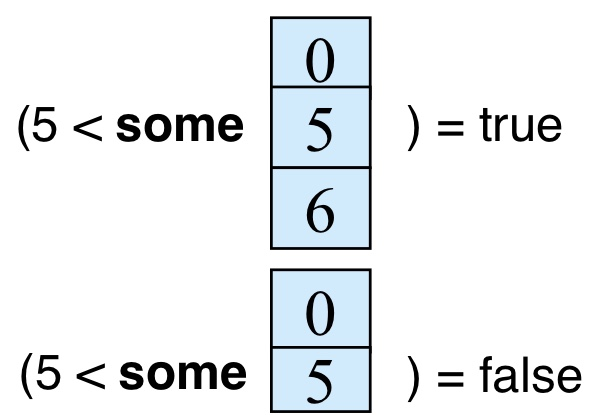
0, 5, 6 중에 한개라고 5보다 크면 true입니다.

5랑 같은게 1개라도 있으면 true
5랑 같지 않은게 1개라도 있으면 true
Set Comparison - "all" Clause
all (= and)
ex) biology 학과에 있는 모든 교수의 salary 보다도 더 큰 salary를 받는 instructor 이름을 찾아보자
즉, biology 학과에 있는 교수의 salary 중 가장 큰 salary보다도 자신의 salary가 더 큰사람
select name from instructor where salary > all(select salary from instructor where dept_name = "Biology");
모든 수가 5보다 커야 true

모든수가 5와 같아야 true
모든 수가 5와 달라야 true
some ==in
!all = not in
!some != not in 이고 all != in 입니다.
exists clause
exists는 해당 subquery가 nonempty이면 true를 return합니다.
not exists는 해앙 subquery가 empty이면 true를 return합니다.
ex) 2017년 가을 학기와 2018년 봄 학기에 모두 열린 과목을 exist구문을 사용해 구현하면
select course_id from section as S where semester = 'Fall' and year = 2017 and exists (select * from section as T where semester = 'Spring' and year = 2018 and S.course_id = T.course_id) ;
section을 S로 불러와서 S 안에서 2017 가을에 열리는 과목을 찾아두고
section을 다시 T로 불러와서 그 T안에서 2018 봄에 열리고, 2017 가을에 열린 그 과목 course_id와 같은게
있는지 찾아봅니다.
같은게 있다면 그 과목은 두번 다 열린게 맞으므로 course_id 반환합니다.
not exists clause
ex) biology 학과에서 열리는 모든 과목을 들은 학생을 찾아라

일단 strudent table에서 이름을 가져옵니다.
student table에서 사람 한 명을 선택한 상태라고 가정합니다.
이 사람에 대해서 where절을 검사해줍니다. 차집합을 해줄건데 먼저 biology 학과에서 열린 모든 과목 course_id를
가져 옵니다. 그다음 이 course_id 집합에서 지금 선택한 학생이 듣고 있는 수업을 아래 select절을 통해 구해서
빼줍니다.
그러면 이제 biology 학과에서 열린 과목 중 학생이 듣지 않은 수업만이 남아 not exists 로 갑니다.
만약 이떄 not exists가 공집합이라면 모든 과목을 다 들었다는 의미이므로 not exists가 true가 되어
해당 student를 return해줍니다.
Test for Absence of Duplicate Tuples
subquery에 중복된 tuple이 있는지 여부를 검사하여 중복이 없을 경우 true을 return합니다.
ex) 2017년에 기껏해야 한 번 열린 모든 과목을 찾아라
select T.course_id from course as T where unique ( select R.course_id from section as R where T.course_id = R.course_id and R.year = 2017);select T.course_id from course as T where 1>= ( select count(R.course_id) from section as R where T.course_id = R.course_id and R.year = 2017);
Subquries in the From Clause
sql은 from문에서 subquery를 허용합니다.
ex) 평균 연봉이 $42,000 보다 더 큰 과들의 평균 연봉을 구하라
select dept_name, avg_salary from (select dept_name, avg (salary) as avg_salary from instructor group by dept_name) where avg_salary > 42000;
위의 경우 having을 쓸 필요가 없습니다. from 안의 절이 먼저 처리가 됩니다.
다른 방식으로 결과를 table화 할 수 도 있습니다. (from ~ as 이용)
select dept_name, avg_salary from (select dept_name, avg (salary) from instructor group by dept_name) as dept_avg (dept_name, avg_salary) where avg_salary > 42000;With Clause
query 안에서 임시로 작동하는 임시적인 table을 만듭니다.
ex) 가장 많은 예산을 가진 모든 department를 찾아라
with max_budget(value) as (select max(budget) from department) select dept_name from department, max_budget where department.budget = max_budget.value;
ex) 총 급여가 모든 부서의 총 급여의 평균보다 큰 부서를 찾아라
with dept_total (dept_name, value) as (select dept_name, sum(salary) from instructor group by dept_name), dept_total_avg(value) as (select avg(value) from dept_total) select dept_name from dept_total, dept_total_avg where dept_total.value>dept_total_avg.value;
dept_name과 부서의 salary의 총 합을 저장하고 있는 dept_total이라는 table과 dept_total의 value
즉, 각 부서별 salary의 총 합을 평균낸 값을 저장하고 있는 dept_total_avg를 새로 만듭니다.
그리고 이 두 table에서 value값을 비교해 부서를 찾습니다.
Scalar Subquery
결과값이 하나일 것으로 예상될 때 사용합니다. select에 쓸 수 있습니다.
ex) 모든 부서를 각 부서의 교수자의 수와 함께 열거해라
select dept_name, (select count(*) //1 개의 속성을 가진 tuple (여기서는 숫자) from instructor where department.dept_name = instructor.dept_name) as num_instructors from department;
만약 suquery가 한개 이상의 tuple을 return할 경우 runtime error가 발생합니다.
Modification of the Database
Deletion, Insert, Update의 기능이 있습니다.
Deletion
모든 tuple을 다 지울 경우
delete from instructortuple중 특정 조건을 만족하는 tuple만 지울 경우
delete from instructor where dept_name = 'Finance';ex) Watson building에 위치한 아파트에 사는 instructor을 지워라
delete from instructor where dept_name in (select dept_name from department where building = 'Watson');ex) 연봉이 평균 연봉보다 작은 사람들을 지워라
delete from instructor where salary < (select avg(salary) from instructor);이 경우 평균을 매번 구하게 되면 delete 할때 마다 기준이 되는 평균값이 달라질 수 있습니다.
따라서 평균값을 먼저 구해 값을 고정한 다음에 delete할 대상을 찾아봅니다.
그 다음 delete할 대상을 한번에 지웁니다. (avg를 다시 계산하거나 비교를 다시 하지 않습니다.)
Insertion
새로운 tuple을 삽입합니다.
insert into course values('CS-437', 'Database Systems', 'Comp.Sci.', 4);또는
insert into course(course_id, title, dept_name, credits) values('CS-437', 'Database Systems', 'Comp.Sci.', 4);만약 일부 항목을 빈칸으로 채우고 싶으면
insert into student values ('3003', 'Green', 'Finance', null);위와 같이 null을 적어줍니다.
ex) 144학점 이상 들은 음악과에 있는 학생들을 연봉 18,000인 교수로 추가해라
insert into instructor select ID, name, dept_name, 18000 from student where dept_name = 'Music' and total_cred>144;select, from, where 문은 relation에 삽입되기 전에 다 계산이 완료됩니다. 그리고 그 결과를 삽입하는 것입니다.
그렇지 않으면 다음 query를 수행할 때 문제가 생깁니다.
insert into table1 select * from table1; //무한 루프Updates
몇몇 요소들을 update합니다.
ex) 모든 교수들의 연봉을 5% 인상
update instructor set salary = salary * 1.05;ex) 70000 보다 적게 버는 교수 5% 연봉 인상
update instructor set salary=salary * 1.05 where salary < 70000;ex) 평균보다 낮은 교수 연봉 5% 인상
update instructor set salary = salary * 1.05 where salary<(select avg(salary) from instructor);ex) 100000이 넘는 사람은 3%인상하고 나머지는 5%인상
update instructor set salary = salary * 1.03 where salary > 100000; update instructor set salary = salary * 1.05 where salary <= 1000000;두 개의 update 문을 사용할 수 있습니다. 첫번째 update문을 먼저할지 두번째 update문을 먼저할지 에 따라
결과가 다르게 나옵니다. 따라서 순서가 중요합니다.
이를 개선한것이 case문입니다.
update instructor set salary = case when salary <= 100000 then salary * 1.05 else salary * 1.03 end;일반적으로 case문을 사용하는것이 더 좋습니다.
case문의 템플릿입니다.

Updates with Scalar Subqueries
tot_creds 의 값을 재계산 및 update
update student set tot_cred = (select sum(credits) from takes, course where takes.course_id = course.course_id and student.ID = takes.ID and takes.grade<>'F' and takes.grade is not null);만약 어떠한 course도 수강하지 않은 학생은 tot_creds를 null값으로 설정하려면 다음 코드를 sum(credits) 대신 사용
case when sum(credits) is not null then sum(credits) else 0 end'데이터 베이스 시스템' 카테고리의 다른 글
Normalization (0) 2022.05.02 Intermediate SQL (0) 2022.04.16 Database Design Using the E-R Model (0) 2022.04.02 Intro to Relation Model (0) 2022.03.20 Introduction (0) 2022.03.07