-
Chapter 5 : Memory Hierarchy컴퓨터 아키텍쳐 2022. 6. 15. 20:32728x90
메모리는 크게 3가지로 나뉘어 집니다.
Secondary Memory(Disk, Storage)
Main Memory
Cache
Memory Technology
메모리에는 ROM과 RAM이 있습니다.
ROM은 Read-Only Memory의 약자로 비휘발성 메모리라는 의미입니다. 전원이 꺼져도 data가 남아있습니다.
RAM은 Random Access Memory의 약자로 휘발성 메모리라는 의미입니다. 전원이 꺼지면 data가 날라갑니다.
Static RAM(SRAM)
메모리에 access하는데 0.5ns ~ 2.5ns가 들고 GB당 $500 ~ $1000에 가격입니다.
Dynamic RAM(DRAM)
메모리에 access하는데 50ns ~ 70ns가 들고 GB당 $3 ~ $6 가격입니다.
이상적인 형태의 메모리라면 SRAM의 access 속도에 용량과 가격은 DRAM이면 좋겠습니다.
Principle of Locality
지역성의 원칙입니다.
프로그램은 언제나 주소공간(메모리)의 아주 작은 일부분에 접근합니다.
즉, access하는 부분을 계속 access할 확률이 높습니다.
Temporal(시간적인) locality(지역성)
최근에 access한 항목은 아마 곧 다시 access할 확률이 높습니다.
ex) loop에서의 instruction, induction 변수(반복문의 i)
Spatial(공간적인) locality
최근에 access한 항목 근처의 것들을 아마 곧 access할 확률이 높습니다.
ex) 연속되는(순차적인, sequential) instruction access array 데이터
Taking Advantage of Locality
지역성을 활용하는 것입니다.
1. Memory hierarchy
자주 사용하는 데이터를 점점 고속의 임시 저장소로, CPU와 가깝게 놓습니다.
2. Disk에 모든것을 저장
3. 최근에 access한(그리고 주변들의) 항목들을 disk에서 작은 DRAM 메모리로 복사합니다.
메인 메모리(고속)
4. 좀 더 최근의 항목들은 DRAM에서 더 작은 SRAM 메모리로 복사합니다.
CPU에 붙은(CPU와 통합된) 캐시 메모리(초고속)
Memory Hierarchy Levels
메모리 계층의 단계

Block(=line)
복사의 단위(unit of copying)
아마 여러개의 word(multiple words, 32bit * n)로 이루어집니다.
만약 원하는 데이터가 상층부(upper level, 캐시, 더 빠른)에 존재하면
Hit(적중) : 상층부에서 access를 성공
Hit ratio : hits(hit이 발생한 수) / accesses(access한 수)
만약 원하는 데이터가 없으면
Miss : 하층부(lower level, 더 느리고, 더 큰)에서 block을 복사
시간 소요 : Miss penalty
miss ratio : misses(miss가 발생한 수) / accesses(access한 수) = 1 - hit ratio
하층부로 복사해와서는, 이제 상층부에서 데이터를 access 합니다.
miss ratio + hit ratio = 1
Cache Memory

cache memory는 메모리 계층에서 CPU와 가장 근접한 단계입니다.
위에 그림에서 보면 cache에 Xn을 access한다고 했을 때를 보여줍니다.
access 후에 Xn에 해당하는 block이 cache에 들어오게 됩니다. (cache에 순서대로 위치하는 것은 아닙니다.)
의문점은
데이터가 현재 캐시에 존재하는지 어떻게 알 수 있느냐?
어디를 살펴봐야하는?

예시로 메인 메모리에 16개의 block
메인 메모리 block의 index(block address)인 6개의 bit중 하위 2bit는 word안에서 byte를 정의하기 때문에
access할 때는 전혀 필요가 없습니다. 따라서 don't care로 표시하였습니다.
6개의 bit중 중간에 2 bit(빨간색)는 Cache의 index에 쓰입니다. 예시에서 보면 Cache의 index는 총 4개 입니다.
(00, 01, 10, 11) 즉, cache의 어느 열(line)에 mapping 되는지를 나타냅니다.
6개의 bit중 상위 2 bit(파란색)는 cache의 tag에 쓰입니다.
메인 메모리 입장에서는 block 각자 정해진(index가 일치하는) 4개의 word block(cache)중 1가지에 mapping합니다.
메인 메모리 주소의 그 다음 2 bit(cache의 index)로 cache의 line위치를 결정합니다.
cache의 tag와 메인메모리 주소의 상위 2bit를 비교하여, cache에 메모리 block이 있는지 알 수 있습니다.
예를 들어 cache에서 index가 10인 line에서는 0010xx, 0110xx, 1010xx, 1110xx 중 하나가 매핑되어 있을 것입니다.
이제 tag를 보고, 찾으려는 메모리 주소의 상위 2bit를 비교하여 찾는 데이터가 cache에 있는지 확인합니다.
맞으면 hit
다르면 miss
메인 메모리의 주소(block address)들을 cache의 block들의 수로 나머지 연산을 한것이 index가 됩니다.
Direct Mapped Cache

위치가 주소로 결정됩니다. 위에서 본 방식과 같습니다.
block address % cache의 block 수
ex) 1 % 8(캐시 block의 수) = 9 % 8 = 17 % 8 = 25 % 8 = 1
block의 수는 2^n개 입니다.
최하위 n bit를 address bit로 사용합니다.
Tags and Valid Bits
cache의 위치에 mapping된 데이터가, 메모리의 어느 특정 block과 일치하는지 어떻게 알 수 있는가?
block 주소를 데이터 처럼 저장합니다.
실제로는 오직 상위 bit들만 필요합니다.
이것을 tag라고 부릅니다.
만약 cache에 data가 없다면?
valid bit가 1이면 존재하는 것이고, 0이면 없는 것입니다.
처음에는 모두 0으로 시작합니다.
Cache Example
8개의 block이고 block당 1 word = 32 bit 이며 direct mapping을 합니다.
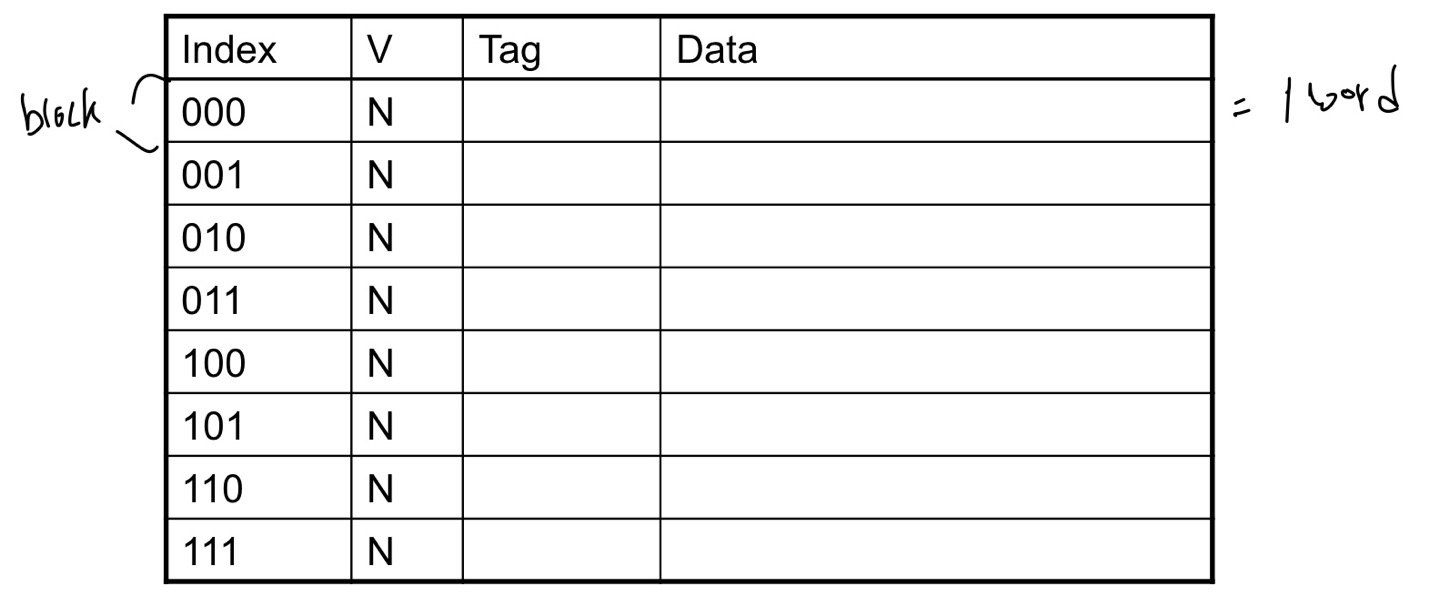
초기 단계입니다.

메인 메모리에서 cache에 접근하였습니다.
메인 메모리의 주소는 10110입니다.
cache의 block이 8(2^3)개 이므로 10110 mode 8 = 110입니다.
즉, 메모리 주소에서 하위 3bit만이 mod 8한 값입니다.
처음에는 모두 valid가 0이기 때문에 data가 없습니다. 따라서 처음에는 miss이고
access이후에는 valid가 1로 바뀌었습니다. data가 들어갔다는 의미입니다.

또 data가 들어왔습니다.

기존에 있던 위치에 또 data가 들어왔습니다. 따라서 Hit입니다.

마찬가지로 처음에 word address가 16인 것이 들어오고
나중에 또 들어오니 hit입니다.

이번에는 index가 같지만 tag가 다른 data가 들어왔습니다.
원래 010 index에 있던 data 대신 새롭게 들어온 data가 쓰여집니다.
MIPS Direct Mapped Cache 예제
ex) 1 word block, cache size = 1K words(or 4KB)

1024개를 위한 bit(index)는 1024 = 2^10이므로 10개의 bit입니다.
따라서 index는 최하위 2bit를 뺀 10개의 bit를 사용합니다.
나머지 bit인 상위 20bit가 tag가 됩니다.
캐시 메모리에서는 data가 32bit, index는 10bit, tag는 20bit, valid는 1bit를 사용합니다.
이 cache는 temporal locality만 활용합니다. 인접 데이터가 아닌 최근 데이터를 직접
Example : Larger Block Size
ex) 64 blocks, block당 size = 16 bytes (즉, block당 4 word)
메인 메모리의 주소가 1200인 block은 어떤 block number에 mapping 되는 가??
16(2^4) byte를 위해, 최하위 4bit(0 ~ 3자리)를 offset으로
즉, 주소 중 최하위 4자리는 cache 저장에 무시할 수 있습니다.
주소의 최하위 4bit는 필요없으므로 4자리를 깎기 위해 right shift 4(>> 4)를 하면 16으로 나누면 됩니다.
따라서 block address = floor(1200 / 16) = 75가 됩니다.
64(2^6)개의 block이니 그 위 6bit를 (4 ~ 9)자리를 index로
75(1001011)를 block의 수로 나머지 연산을 하면
1001011 % 64(2^6) = 001011 = 11
index위치는 11입니다.

Multiword Block Direct Mapped Caches
cache의 block에 여러 word가 저장되는 것입니다.
방금 본 예제도 block당 4 word였습니다. 위의 예제는 그냥 block number만 구하는 것이었고 여기서 자세히 설명)
ex) block당 16 word, cache의 size = 4K words

16 word는 16 * 4 bytes = 2^6 bytes 즉, 최하위 6bit를 offset으로 사용합니다.
word단위로 access하므로, 이 중 word offset은 최하위 2bit(0 ~1자리, 4 byte)
그 위 4bit(2 ~5자리)가 block offset
cache size = 4K word = 2^12 word = 2^(4 + 8) word
즉 , block의 개수가 2^8개 이니 256개 입니다.
offset의 상위 8bit(6 ~13자리)가 index
나머지 최상위 18bit(14 ~ 31자리)가 tag입니다.
한 block에 16개의 word가 담기지만 CPU가 access하는 것은 1 word
즉, MUX를 사용하며, 여기에 block offset을 통해 block의 몇 번째 word에 access할지 결정합니다.
이 cache는 temporal locality와 spatial locality 둘다 활용합니다.
Block Size Considerations
block 크기의 고려사항입니다.
block이 클 수록 miss rate는 감소합니다.
spatial locality 때문입니다. 한꺼 번에 많이 저장하기 때문입니다.
하지만 cache의 크기는 고정되어 있습니다.
cache의 크기는 고정되어 있는데, block의 크기가 커지면 cache의 line(block의 수)의 수는 줄어듦니다.
line이 줄어든다는 것은 하나의 line이 map해야 할 담당 메모리 위치가 늘어나게 된다는 것입니다.
(refresh가 자주 일어나고, 경쟁(competition)이 잦아집니다.)
즉, miss rate를 증가시킵니다.
block이 클 수록, cache의 line에 read/write가 자주 발생하면서 오염(pollution)됩니다.
refresh때, overhead가 더 커질 수 있습니다.
block이 클 수록 miss penalty도 커집니다.
miss가 발생했을 때, miss마다 한 번에 더많은 block을 읽어와야 합니다.
miss rate를 감소시키려다, 전체적인 성능은 더 구려질 수 있습니다.
refresh하려는 word들 중 target word만 우선 바로 보내서 먼저시작하는 방법이 도움이 될 수 는 있습니다.
Cache Misses
cache가 hit 됐을 때, CPU는 보통처럼 동작합니다.
cache가 miss됐을 때, CPU는 pipeline에 stall을 발생시킵니다.
메모리의 다음계층(lower level)에서 해당 block을 fetch해옵니다.
instruction cache miss였다면 다시 instruction fetch가 될 수 있도록 합니다.
data cache miss 였다면, data access를 완료합니다.
Write-Through
data write가 발생하면, cache와 메모리의 데이터를 모두 업데이트 하는 것입니다.
data write가 발생하면 메모리가 아닌 cache의 block을 바로 업데이트할 수 있습니다.
하지만 그렇게 되면 메모리와 cache의 일관성이 없어집니다.
원본 메모리는 old값인데, cache만 new값이 되어버립니다.
그러면 cache와 메모리를 동시에 업데이트 하면 되는데 이것 또한 시간이 오래 걸립니다.
해결책은 write buffer 입니다.
메모리에 쓸 data를 buffer에 가지고 있는 것입니다. 메모리에 write될 때 까지
CPU는 즉시 지연없이 계속 진행할 수 있습니다.(write buffer에 있는 data를 사용하면서)
메모리에 write가 될 때까지 기다리지 않아도 됩니다.
만약 write buffer가 이미 가득 차 있을 때에만 stall이 발생합니다.(이 때는 메모리에 써야함)
Write-Back
write-through와는 다른 방식입니다.
data write가 발생하면, 메모리가 아닌 cache의 block만 바로 업데이트 합니다.
그렇게 되면 메인 메모리와 cache의 data가 달라집니다. 이제 데이터가 다른지 같은지 알아야 합니다.
각 block이 다른지(dirty한지) 추적해야 합니다. dirty bit를 둬서 확인합니다.
dirty block이 제거될 때 즉, cache의 data가 유효값인데, 해당 line에 교체 등의 이유로 cache에서 빠져나가야
될 경우, 그 때 메모리에 write 합니다.
여기에도 write buffer를 활용하여 메모리에 쓰는 것을 CPU가 기다리지 않도록 할 수 있습니다.
Write Allocation
write miss가 발생한다면 어떻게 되는가??
write-through의 대안
1. miss된 data를 가져옵니다.(fetch the block)
2. write around : block을 fetch하지 않습니다.(No write allocate)
그러면 cache에는 write하지 않고, 메모리만 직접 업데이트 합니다.
write-back의 대안
주로 fetch the block
Example : Intrinsity FastMATH
* Embedded MIPS processor
ㆍ12-stage pipeline
ㆍ각 cycle마다 instruction과 data의 access. 즉 access마다 1 cycle 소요.
*Split cache: I-cache와 D-cache가 나뉘어져있음(separate).
ㆍInstruction cache. Data cache.
ㆍ각각 16KB: 256 blocks * 16 words/block
ㆍD-cache: write-through or write-back
*SPEC2000 miss rate
ㆍI-cache: 0.4%
ㆍD-cache: 11.4%
ㆍ가중 평균(weighted average): 3.2%

Measuring Cache Performance
cache의 성능을 측정합니다.
CPU time을 측정하는 요소는 다음과 같습니다.
Program execution cycle (cache hit time을 포함)
memory stall cycle (주로 cache miss들로 부터 발생합니다.)

EX)
I-cache miss rate: 2%
D-cache miss rate: 4%
miss penalty: 100 cycles
base CPI (ideal cache): 2.0
instruction들의 36%가 load & store로 이루어져 있음.
*miss cycles per instruction
ㆍI-cache = 0.02 * 100 = 2
ㆍD-cache = 0.36 * 0.04 * 100 = 1.44
*actual CPI = 2.0 + 2 + 1.44 = 5.44
ㆍideal CPU는 5.44/2.0 = 2.72배의 속도.
(※ ideal은 말그대로 이상적인. miss가 0인. 초기상태를 생각해도 miss가 0일 순 없는데, 여튼 0에 한없이 가까운.)
Average Access Time
hit time역시 성능에 중요합니다.
Average Memory Access Time(AMAT) 평균 메모리 접근 시간
AMAT = hit time + miss rate * miss penalty
ex)
ㆍCPU with 1ns clock (CPU의 clock period가 1ns)
ㆍhit time: 1 cycle
ㆍmiss penalty: 20 cycles
ㆍI-cache miss rate: 5%
AMAT = 1 + 0.05 * 20 = 2ns
2ns라면 조건에서는 2 clock cycle 즉, 2 cycle per instruction
Performance Summary
*CPU 성능이 향상되면,
ㆍmiss penalty가 점점 더 중요하게 여겨진다.
ㆍ더 많은 비중을 차지하게 된다.
ㆍCPU가 빨라지면, 총 시간 중에 "메모리에서 소요되는 시간"이 더 많이 차지하게 됨.
(총 시간 중에 프로세서에서 소요되는 시간이 줄어들어서)
*base CPI를 줄이면,
ㆍ총 시간 중에, 메모리 stall에 소요되는 시간의 비중이 더 커짐.
*clock rate를 높이면(cycle time이 줄어서 더 자주 clock),
ㆍ메모리 stall에 걸리는 CPU cycle이 더 많아짐.
*시스템 성능을 평가할 때, cache 동작(behavior)을 무시할 수 없다.
Associative Caches
이제 그동안 본 것(Direct Map Cache, cache의 block(line)에 한 block이 들어갑니다.) 과는 다른 형태의 cache입니다.
cachedml set(line)에 여러 block이 들어갑니다. 이 cache의 line은 block이 단위가 아니라 set이 단위입니다.
Fully associative
block이 cache의 어느 entry에나 들어갈 수 있습니다.
모든 entry를 한번에 (즉시 동시에) 검색해야합니다.
entry마다 comparator가 필요합니다.(즉, 비용이 비싸집니다.)
n-way set associative
각 set은 n개의 entry로 구성되어 있습니다.(각 set은 n개의 entry를 갖고 있습니다.) set은 cache의 line과 같은것
block의 index가 어떤 set에 mapping되는지 결정합니다.(어느 set = block index % cache set의 갯수)
해당 set의 entry들을 한번에 검색해야합니다.
n개의 comparator가 필요합니다. (fully associative보다는 비용이 적어집니다.)
EX)

Fully associative는 set이 1개입니다.
Spectrum of Associative
8개의 entry를 가진 cache를 생각
아래의 4가지 구조가 가능합니다.

set이 1개이고 그 안에 모든 entry가 속하는 구조는 결국 fully assciative입니다.
Associativity Example
ex) 4 block의 cache 즉, 4 개의 entry를 갖는 cache를 비교해봅니다.
direct mapped
2-way set associative
fully associative
총 3종류가 가능합니다.
block access의 순서는 0 -> 8 -> 0 -> 6 -> 8
Direct mapped

5번의 access가 있었지만 모두 miss입니다.
2-way set associative

총 5번의 access에서 4번의 miss와 1 번의 hit이 발생했습니다.
4번째에서 set0의 way0을 최근에 access했으므로 way1에 새로 write(refresh)
5번째에서 set0의 way1에 최근에 가져왔으므로 way0에 새로 write(refresh)
Fully associative
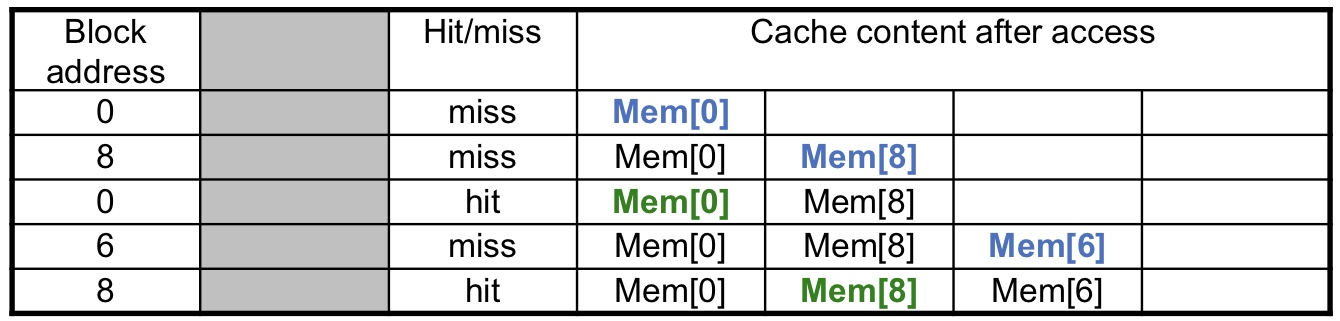
fully associative는 set이 1개 입니다. 즉, index가 없습니다.
cache는 4칸이므로, 꽉 찼다면 access / wirte한지 오랜된 것 부터 제거하고 새로 write(refresh)
How Much Associativity
어느 정도(몇 way)로 구성해야 하는가?
associative를 증가시킬 수 록 miss rate는 낮아집니다.
하지만 점차 그 효과는 낮아집니다.(효율이 낮아지는 것입니다. log 함수 그래프처럼)
miss rate는
1-way : 10.3%
2-way : 8.6%
3-way : 8.3%
8-way : 8.1%
4 way와 8 way나 성능의 차이는 거의 없지만 비용은 associativity가 커질 수록 점점 더 커지기 때문에
비용 대비 효율은 급감합니다.
Set Associative Cache Organization

set associative cache의 내부 구조입니다.
4-way set associative cache입니다.
Replacement Policy
교체 정책(방식)
cache miss가 발생했을 때, set 안에서 어떤 block을 교체할 것인지.
ㆁdirect mapped: 선택권이 없음. 그냥 무조건 교체.
ㆁset associative
*non-valid(valid bit가 0인) entry가 있다면, 이걸 선호
*그 다음 조건(non-valid가 여럿이거나, valid만 있거나)으로는 아래 같은 방식..
ㆁLeast-Recently Used (LRU) 최근에 적게 사용된. 즉, 잘 안쓰는.
*장시간 잘 쓰지 않는 것을 고른다.
ㆍ2-way에서는 둘 중 고르기 쉽고, 4-way에서는 다룰 만한데, 그 이상에서는 이걸 고르는 것도 어려워짐.
ㆁRandom
*근데 high associativity에서는 LRU와 거의 유사한 성능 수준을 보여줌..
Multilevel Caches
지금까지 한 계층의 cache를 봤었습니다.
실제로 사용하는 CPU는 여러계층으로 되어 있고, 최근에는 L3까지 있습니다.
Primary cache(L1)
CPU와 붙어있습니다.
용량이 작지만, 빠릅니다.
L2
L1에서 miss가 발생되었을 때에 access합니다.
L1보다는 조금 더 용량이 크고, 조금 더 느리지만, 여전히 메인메모리에 비해서 빠릅니다.
L3
최근에 고성능 시스템에서 사용합니다.
EX)
조건
CPU base CPI: 1
clock rate: 4GHz (즉, clock period는 1/(4*10^9) s/cycle = 0.25ns/cycle)
miss rate/instruction: 2%
메인메모리 access time: 100ns
Primary cache만 사용할 경우
miss penalty = 100ns / (0.25ns / cycle) = 400 cycles
effective CPI = 1 + 0.02 * 400 = 9
L2 Cache를 추가할 경우
L-2 access time: 5ns
global miss rate to main memory: 0.5%
primary miss with L-2 hit
penalty = 5ns / (0.25ns/cycle) = 20 cycles
primary miss with L-2 miss
추가 penalty = 400 cycles (메인메모리로 miss penalty는 아까 구했었음)
effective CPI = 1 + 0.02 * 20 + 0.005 * 400 = 3.4
성능비(performance ratio) = 9/3.4 = 2.6
L-2캐시를 함께 사용하는 것이, 2.6배의 속도.
'컴퓨터 아키텍쳐' 카테고리의 다른 글
Chapter 4 : Processor (0) 2022.06.10 Logic Design (0) 2022.04.18 Chapter 3 : Arithmetic for Computers (0) 2022.04.11 Chapter 2 : Instructions : Language of the Computer (0) 2022.03.24 Chapter 1 (0) 2022.03.06